
Prueba t de Student
Una t-prueba es un tipo de análisis estadístico que se utiliza para comparar los promedios de dos grupos y determinar si es más probable que las diferencias entre ellos surjan del azar.. Es cualquier prueba de hipótesis estadística en la que el estadístico de prueba sigue una distribución t de Student bajo la hipótesis nula. Se aplica más comúnmente cuando el estadístico de prueba seguiría una distribución normal si se conociera el valor de un término de escala en el estadístico de prueba (normalmente, el término de escala es desconocido y, por lo tanto, es un parámetro molesto). Cuando el término de escala se estima en función de los datos, el estadístico de prueba (bajo ciertas condiciones) sigue una distribución t de Student. La aplicación más común de la prueba t es probar si las medias de dos poblaciones son diferentes.
Historia

El término "t-estadística" se abrevia de "estadística de prueba de hipótesis". En estadística, la distribución t fue derivada por primera vez como distribución posterior en 1876 por Helmert y Lüroth. La distribución t también apareció en una forma más general como distribución de Pearson tipo IV en el artículo de Karl Pearson de 1895. Sin embargo, la distribución t, también conocida como distribución t de Student, recibe su nombre de William Sealy Gosset, quien la publicó por primera vez en inglés en 1908 en la revista científica Biometrika usando el seudónimo "Estudiante" porque su empleador prefería que el personal utilizara seudónimos al publicar artículos científicos. Gosset trabajaba en la cervecería Guinness de Dublín, Irlanda, y estaba interesado en los problemas de las muestras pequeñas (por ejemplo, las propiedades químicas de la cebada con muestras pequeñas). De ahí que una segunda versión de la etimología del término Student sea que Guinness no quería que sus competidores supieran que estaban usando la prueba t para determinar la calidad de la materia prima. Aunque fue William Gosset en honor a quien surgió el término "Estudiante" está escrito, en realidad fue gracias al trabajo de Ronald Fisher que la distribución se hizo conocida como "distribución de estudiantes" y "Prueba t de Student".
Gosset había sido contratado debido a la política de Claude Guinness de reclutar a los mejores graduados de Oxford y Cambridge para aplicar la bioquímica y la estadística a los procesos industriales de Guinness. Gosset ideó la prueba t como una forma económica de controlar la calidad de la cerveza negra. El trabajo de la prueba t fue presentado y aceptado en la revista Biometrika y publicado en 1908.
Guinness tenía la política de permitir al personal técnico licencia para estudiar (la llamada "licencia para estudiar"), que Gosset utilizó durante los dos primeros trimestres del año académico 1906-1907 en el Profesor Karl Pearson' Laboratorio Biométrico del University College London. La identidad de Gosset era entonces conocida por sus colegas estadísticos y por el editor en jefe Karl Pearson.
Usos


Las pruebas t más utilizadas son las de una y dos muestras:
- A una muestra prueba de ubicación de si la media de una población tiene un valor especificado en una hipótesis nula.
- A dos muestras prueba de ubicación de la hipótesis nula tal que los medios de dos poblaciones son iguales. Todas estas pruebas se suelen llamar Estudiante t- Tests, aunque estrictamente hablando que el nombre sólo debe ser utilizado si las diferencias de las dos poblaciones también se supone que son iguales; la forma de la prueba utilizada cuando esta suposición es bajada a veces se llama prueba t de Welch. Estas pruebas se denominan a menudo no pagado o muestras independientes t-pruebas, ya que normalmente se aplican cuando las unidades estadísticas que subyacen a las dos muestras que se comparan no se superponen.
Suposiciones
La mayoría de las estadísticas de prueba tienen la forma t = Z/s, donde < span class="texhtml">Z y s son funciones de los datos.
Z puede ser sensible a la hipótesis alternativa (es decir, su magnitud tiende a ser mayor cuando la hipótesis alternativa es verdadera), mientras que s es un parámetro de escala que permite determinar la distribución de t.
Como ejemplo, en la prueba t de una muestra

Donde X es la muestra media de una muestra X1, X2,... Xn, de tamaño n, s es el error estándar de la media, es la estimación de la desviación estándar de la población, y μ es la población media.

Los supuestos subyacentes a una prueba t en la forma más simple anterior son los siguientes:
- X sigue una distribución normal con media μ y diferencia σ2/n.
- s2()n−1)/σ2 sigue una distribución de χ2 con n− 1 grados de libertad. Esta hipótesis se cumple cuando se utilizan las observaciones para estimar s2 proviene de una distribución normal (y i.i.d. para cada grupo).
- Z y s son independientes.
En la prueba t que compara las medias de dos muestras independientes, se deben cumplir los siguientes supuestos:
- Los medios de comparación de las dos poblaciones deben seguir distribuciones normales. Bajo supuestos débiles, esto sigue en grandes muestras del teorema límite central, incluso cuando la distribución de observaciones en cada grupo no es normal.
- Si utiliza la definición original del estudiante de la t-test, las dos poblaciones que se comparan deben tener la misma varianza (posible con F-test, la prueba de Levene, la prueba de Bartlett, o la prueba Brown-Forsythe; o evaluable gráficamente utilizando una parcela Q-Q). Si los tamaños de la muestra en los dos grupos que se comparan son iguales, el original del estudiante t- La prueba es altamente robusta para la presencia de diferencias desiguales. La prueba t de Welch es insensible a la igualdad de las diferencias, independientemente de si los tamaños de la muestra son similares.
- Los datos utilizados para llevar a cabo la prueba deben ser muestreados independientemente de las dos poblaciones en comparación o ser emparejados completamente. Esto no es en general testable de los datos, pero si se sabe que los datos son dependientes (por ejemplo, emparejados por el diseño de prueba), hay que aplicar una prueba dependiente. Para datos emparejados parcialmente, el clásico independiente t- Las pruebas pueden dar resultados inválidos, ya que la estadística de prueba podría no seguir un t distribución, mientras que el dependiente t- La prueba es suboptimal ya que descarta los datos no pagados.
La mayoría de las pruebas t de dos muestras son robustas excepto ante grandes desviaciones de los supuestos.
Para mayor exactitud, las pruebas t y Z requieren normalidad de las medias muestrales, y la prueba t requiere adicionalmente que la varianza muestral sigue una distribución χ2 escalada, y que la media muestral y la varianza muestral sean estadísticamente independientes. La normalidad de los valores de datos individuales no es necesaria si se cumplen estas condiciones. Según el teorema del límite central, las medias muestrales de muestras moderadamente grandes suelen estar bien aproximadas mediante una distribución normal, incluso si los datos no están distribuidos normalmente. Para datos no normales, la distribución de la varianza muestral puede desviarse sustancialmente de un χ2 distribución.
Sin embargo, si el tamaño de la muestra es grande, el teorema de Slutsky implica que la distribución de la varianza muestral tiene poco efecto en la distribución de la estadística de prueba. Eso es, como tamaño de muestra aumentos:

- según el teorema límite central,
- conforme a la ley de gran número,
- .



Pruebas t de dos muestras emparejadas y no apareadas


Las pruebas t de dos muestras para una diferencia de medias implican muestras independientes (muestras no apareadas) o muestras apareadas. Las pruebas t pareadas son una forma de bloqueo y tienen mayor poder (probabilidad de evitar un error tipo II, también conocido como falso negativo) que las pruebas no pareadas cuando las unidades pareadas son similares con respecto a & #34;factores de ruido" (ver factor de confusión) que son independientes de la pertenencia a los dos grupos que se comparan. En un contexto diferente, las pruebas t pareadas se pueden utilizar para reducir los efectos de los factores de confusión en un estudio observacional.
Muestras independientes (no emparejadas)
La prueba t de muestras independientes se utiliza cuando se obtienen dos conjuntos separados de muestras independientes e idénticamente distribuidas, y se compara una variable de cada una de las dos poblaciones. Por ejemplo, supongamos que estamos evaluando el efecto de un tratamiento médico e inscribimos a 100 sujetos en nuestro estudio, luego asignamos aleatoriamente 50 sujetos al grupo de tratamiento y 50 sujetos al grupo de control. En este caso, tenemos dos muestras independientes y usaríamos la forma no apareada de la prueba t.
Muestras emparejadas
Las pruebas t de muestras pareadas suelen consistir en una muestra de pares emparejados de unidades similares, o un grupo de unidades que se ha probado dos veces (una "medidas repetidas" t-prueba).
Un ejemplo típico de la prueba t de medidas repetidas sería cuando los sujetos son evaluados antes de un tratamiento, por ejemplo para detectar presión arterial alta, y los mismos sujetos son evaluados nuevamente después del tratamiento con un análisis de sangre. medicación para bajar la presión. Al comparar las cifras del mismo paciente antes y después del tratamiento, utilizamos efectivamente a cada paciente como su propio control. De esa manera, el rechazo correcto de la hipótesis nula (aquí: de que el tratamiento no produjo diferencias) puede volverse mucho más probable, con un poder estadístico aumentando simplemente porque ahora se ha eliminado la variación aleatoria entre pacientes. Sin embargo, un aumento del poder estadístico tiene un precio: se requieren más pruebas y cada sujeto debe ser evaluado dos veces. Debido a que la mitad de la muestra ahora depende de la otra mitad, la versión emparejada de la prueba t de Student solo tiene n/2< /span> − 1 grados de libertad (siendo n el número total de observaciones). Los pares se convierten en unidades de prueba individuales y la muestra debe duplicarse para lograr el mismo número de grados de libertad. Normalmente, hay n − 1 grados de libertad (con n siendo el número total de observaciones).
Una prueba t de muestras pareadas basada en una "muestra de pares coincidentes" resultados de una muestra no apareada que posteriormente se utiliza para formar una muestra apareada, mediante el uso de variables adicionales que se midieron junto con la variable de interés. El emparejamiento se lleva a cabo identificando pares de valores que consisten en una observación de cada una de las dos muestras, donde el par es similar en términos de otras variables medidas. Este enfoque se utiliza a veces en estudios observacionales para reducir o eliminar los efectos de los factores de confusión.
Las pruebas t de muestras pareadas a menudo se denominan "pruebas t de muestras dependientes".
Cálculos
A continuación se proporcionan expresiones explícitas que se pueden utilizar para llevar a cabo varias pruebas t. En cada caso, se proporciona la fórmula para un estadístico de prueba que sigue exactamente o se aproxima mucho a una distribución t bajo la hipótesis nula. Además, se dan los grados de libertad adecuados en cada caso. Cada una de estas estadísticas se puede utilizar para realizar una prueba de una o dos colas.
Una vez determinados el valor t y los grados de libertad, se puede encontrar un valor p utilizando una tabla de valores de la distribución t de Student. Si el valor p calculado está por debajo del umbral elegido para la significación estadística (normalmente el nivel 0,10, 0,05 o 0,01), entonces la hipótesis nula se rechaza a favor de la hipótesis alternativa.
Prueba t de una muestra
Al probar la hipótesis nula de que la media poblacional es igual a un valor específico μ0, se utiliza la estadística

Donde es la muestra media, s es la desviación estándar muestra y n es el tamaño de la muestra. Los grados de libertad utilizados en esta prueba son n− 1. Aunque la población matriz no necesita ser distribuida normalmente, la distribución de la población de la muestra significa se supone que es normal.

Por el teorema límite central, si las observaciones son independientes y el segundo momento existe, entonces será aproximadamente normal .


Pendiente de una recta de regresión
Supongamos que uno se ajusta al modelo.

donde se conoce x, α y β son desconocidas, ε es una variable aleatoria distribuida normalmente con media 0 y varianza desconocida σ2 y Y< /span> es el resultado de interés. Queremos probar la hipótesis nula de que la pendiente β es igual a algún valor especificado β0 (a menudo se considera 0, en cuyo caso la hipótesis nula es que x y y no están correlacionados).
Dejar

Entonces

tiene una distribución t con n − 2 grados de libertad si la hipótesis nula es verdadera. El error estándar del coeficiente de pendiente:

puede escribirse en términos de residuos. Dejar

Entonces tpuntuación viene dada por

Otra forma de determinar la tpuntuación es

donde r es el coeficiente de correlación de Pearson.
La tpuntuación, intersección se puede determinar a partir de la tpuntuación, pendiente:

donde sx2 es la varianza de la muestra.
Prueba t independiente de dos muestras
Tamaños de muestra iguales y varianza
Dados dos grupos (1, 2), esta prueba sólo es aplicable cuando:
- los dos tamaños de muestra son iguales,
- se puede suponer que las dos distribuciones tienen la misma variabilidad.
Las violaciones de estos supuestos se analizan a continuación.
El estadístico t para comprobar si las medias son diferentes se puede calcular de la siguiente manera:

dónde

Aquí sp es la desviación estándar agrupada para n = n1 = n2 y s 2
>X1 y s 2
>X2 son los estimadores insesgados de la población diferencia. El denominador de t es el error estándar de la diferencia entre dos medias.
Para las pruebas de significancia, los grados de libertad para esta prueba son 2n − 2, donde n es el tamaño de la muestra.
Tamaños de muestra iguales o desiguales, varianzas similares (1/2 < sX1/sX2 < 2)
Esta prueba se utiliza sólo cuando se puede suponer que las dos distribuciones tienen la misma varianza (cuando se viola esta suposición, ver más abajo). Las fórmulas anteriores son un caso especial de las fórmulas siguientes, se recuperan cuando ambas muestras tienen el mismo tamaño: n = n1 = n2.
El estadístico t para comprobar si las medias son diferentes se puede calcular de la siguiente manera:

dónde

es la desviación estándar combinada de las dos muestras: se define de esta manera para que su cuadrado sea un estimador insesgado de la varianza común, sean o no las mismas medias poblacionales. En estas fórmulas, ni − 1 es el número de grados de libertad para cada grupo y el tamaño total de la muestra. menos dos (es decir, n1 + n2 − 2< /span>) es el número total de grados de libertad, que se utiliza en las pruebas de significancia.
Tamaños de muestra iguales o desiguales, varianzas desiguales (sX1 > 2sX2 o sX2 > 2sX1)
Esta prueba, también conocida como prueba t de Welch, se utiliza sólo cuando se supone que las dos varianzas de la población no son iguales (los dos tamaños de muestra pueden ser iguales o no).) y, por tanto, debe estimarse por separado. El estadístico t para probar si las medias poblacionales son diferentes se calcula como

dónde

Aquí. si2 es el estimador imparcial de la varianza de cada una de las dos muestras con ni = número de participantes en grupo i ()i = 1 o 2). En este caso no es una varianza. Para su uso en pruebas de significado, la distribución de la estadística de prueba se aproxima como estudiante ordinario t-distribución con los grados de libertad calculados utilizando


Esto se conoce como ecuación de Welch-Satterthwaite. La verdadera distribución del estadístico de prueba en realidad depende (ligeramente) de las dos varianzas poblacionales desconocidas (ver problema de Behrens-Fisher).
Método exacto para varianzas y tamaños de muestra desiguales
La prueba trata del famoso problema de Behrens-Fisher, es decir, comparar la diferencia entre las medias de dos poblaciones distribuidas normalmente cuando se supone que las varianzas de las dos poblaciones no son iguales, basándose en dos muestras independientes.
La prueba se desarrolla como una prueba exacta que permite tamaños de muestra desiguales y diferencias desiguales de dos poblaciones. La propiedad exacta todavía tiene incluso con pequeño tamaños de muestra extremadamente pequeños y desequilibrados (por ejemplo. ).

La estadística para probar si las medias son diferentes se puede calcular de la siguiente manera:
Vamos. y ser los vectores de muestras i.i.d. () de y por separado.
![{displaystyle X=[X_{1},X_{2},ldotsX_{m}]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a0f37f25b326e4b6229a7f0be5283ace07d1a97f)
![{displaystyle Y=[Y_{1},Y_{2},ldotsY_{n}]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a81b49d1f74f1a3c22759407966c63524eac1d2e)



Vamos. ser un matriz ortogonal cuyos elementos de la primera fila son todos , similarmente, dejar ser las primeras n filas de una matriz ortogonal (cuyos elementos de la primera fila son todos ).






Entonces... es un vector aleatorio normal n-dimensional.


De la distribución anterior vemos que





Prueba t dependiente para muestras pareadas
Esta prueba se utiliza cuando las muestras son dependientes; es decir, cuando solo hay una muestra que ha sido analizada dos veces (medidas repetidas) o cuando hay dos muestras que han sido emparejadas o "emparejadas". Este es un ejemplo de una prueba de diferencias pareadas. El estadístico t se calcula como

Donde y son la desviación promedio y estándar de las diferencias entre todos los pares. Los pares son, por ejemplo, las puntuaciones previas y posteriores a la prueba de una persona o entre pares de personas coinciden en grupos significativos (por ejemplo, extraídos del mismo grupo familiar o de edad: ver tabla). La constante μ0 es cero si queremos probar si el promedio de la diferencia es significativamente diferente. El grado de libertad utilizado es n − 1, donde n representa el número de pares.


Ejemplo de pares emparejados Pareja Nombre Edad Prueba 1 John. 35 250 1 Jane 36 340 2 Jimmy 22 460 2 Jessy 21 200 Ejemplo de medidas reiteradas Número Nombre Prueba 1 Prueba 2 1 Mike 35% 67% 2 Melanie 50% 46% 3 Melissa 90% 86% 4 Mitchell 78% 91% Ejemplos trabajados
Vamos. A1 denota un conjunto obtenido mediante el dibujo de una muestra aleatoria de seis mediciones:
y dejar A2 denota un segundo conjunto obtenido de manera similar:
Estos podrían ser, por ejemplo, los pesos de los tornillos que fueron fabricados por dos máquinas diferentes.
Realizaremos pruebas de la hipótesis nula de que los medios de las poblaciones de las que se tomaron las dos muestras son iguales.
La diferencia entre los dos medios de muestra, cada uno denotado por Xi, que aparece en el numerador para todos los enfoques de prueba de dos muestras discutidos anteriormente, es
Las desviaciones estándar de la muestra para las dos muestras son aproximadamente 0.05 y 0.11, respectivamente. Para esas pequeñas muestras, una prueba de igualdad entre las dos diferencias de población no sería muy poderosa. Puesto que los tamaños de la muestra son iguales, las dos formas de los dos muestreos t- La prueba actuará de forma similar en este ejemplo.
Variaciones desiguales
Si se sigue el enfoque de las diferencias desiguales (que se examina más arriba), los resultados son
y los grados de libertad
La estadística de prueba es aproximadamente 1.959, lo que da una prueba de dos colas p- valor de 0.09077.
Variaciones de igualdad
Si se sigue el enfoque para la igualdad de diferencias (que se discutió más arriba), los resultados son
y los grados de libertad
La estadística de prueba es aproximadamente igual a 1.959, lo que da un doble p- valor de 0.07857.
Pruebas estadísticas relacionadas
Alternativas a la prueba t para problemas de ubicación
El t-test proporciona una prueba exacta para la igualdad de los medios de dos poblaciones normales con diferencias desconocidas, pero iguales. (La prueba t de Welch es una prueba casi exacta para el caso en que los datos son normales pero las diferencias pueden diferir.) Para muestras moderadamente grandes y una prueba a medida, la t- La prueba es una violación relativamente robusta a moderada de la suposición de normalidad. En muestras lo suficientemente grandes, la prueba t asintotica se acerca a la prueba z, y se vuelve robusta incluso a grandes desviaciones de la normalidad.
Si los datos son sustancialmente no normales y el tamaño de la muestra es pequeño, el t- La prueba puede dar resultados engañosos. Vea la prueba de ubicación para las distribuciones de mezclas de escala gausiana para alguna teoría relacionada con una familia particular de distribuciones no normales.
Cuando la suposición de normalidad no se sostiene, una alternativa no paramétrica a la t- La prueba puede tener mejor poder estadístico. Sin embargo, cuando los datos no son normales con diferencias diferentes entre grupos, una prueba t puede tener mejor control de errores tipo-1 que algunas alternativas no paramétricas. Además, métodos no paramétricos, como la prueba Mann-Whitney U discutida a continuación, normalmente no prueban por una diferencia de medios, por lo que debe ser utilizado cuidadosamente si una diferencia de medios es de interés científico primario. Por ejemplo, Mann-Whitney La prueba U mantendrá el error tipo 1 en el alfa nivel deseado si ambos grupos tienen la misma distribución. También tendrá poder para detectar una alternativa por la que el grupo B tiene la misma distribución que A pero después de algún cambio por una constante (en cuyo caso habría una diferencia en los medios de los dos grupos). Sin embargo, podría haber casos en los que el grupo A y B tendrá diferentes distribuciones pero con los mismos medios (como dos distribuciones, una con escepticismo positivo y la otra con una negativa, pero cambiada para tener los mismos medios). En tales casos, la MW podría tener más que el poder de nivel alfa en rechazar la hipótesis Null, pero atribuir la interpretación de la diferencia en los medios a tal resultado sería incorrecto.
En presencia de un outlier, la prueba t no es robusta. Por ejemplo, para dos muestras independientes cuando las distribuciones de datos son asimétricas (es decir, las distribuciones se hacen) o las distribuciones tienen colas grandes, entonces la prueba de Wilcoxon-sum (también conocida como la prueba Mann-Whitney U) puede tener tres o cuatro veces mayor potencia que la de la t- Prueba. La contraparte no paramétrica a las muestras emparejadas t- La prueba de Wilcoxon firmado-rank para muestras emparejadas. Para una discusión sobre la elección entre el t- Pruebas y alternativas no paramétricas, véase Lumley, et al. (2002).
Análisis unilateral de la varianza (ANOVA) generaliza los dos muestreos t-prueba cuando los datos pertenecen a más de dos grupos.
Un diseño que incluye tanto observaciones pares como observaciones independientes
Cuando ambas observaciones emparejadas y observaciones independientes están presentes en el diseño de dos muestras, asumiendo que los datos se pierden completamente al azar (MCAR), las observaciones emparejadas o observaciones independientes pueden ser descartadas para proceder con las pruebas estándar anteriores. Alternativamente haciendo uso de todos los datos disponibles, asumiendo la normalidad y MCAR, se podría utilizar la prueba t de superposición parcial generalizada.
Pruebas multivariables
Una generalización del estudiante t estadística, llamada la estadística t-squared de Hotelling, permite la prueba de hipótesis en múltiples (a menudo correlacionadas) medidas dentro de la misma muestra. Por ejemplo, un investigador podría someter una serie de temas a una prueba de personalidad consistente en múltiples escalas de personalidad (por ejemplo, el Inventario de Personalidad Multifasica de Minnesota). Debido a que las medidas de este tipo suelen estar relacionadas positivamente, no es recomendable realizar univariate separado t-tests to test hipotheses, as these would neglect the covariance among measures and inflate the chance of falsely rejecting at least one hipothesis (Type I error). En este caso, una única prueba multivariada es preferible para pruebas de hipótesis. Método de Fisher para combinar múltiples pruebas con alfa reducido para la correlación positiva entre las pruebas es uno. Otro es el de Hotelling T2 estadística sigue un T2 distribución. Sin embargo, en la práctica la distribución raramente se utiliza, ya que los valores tabulados para T2 son difíciles de encontrar. Por lo general, T2 es convertido en un F estadística.
Para una prueba multivariada de un muestreo, la hipótesis es que el vector medio (el vector medio)μ) es igual a un vector dado (μ0). La estadística de prueba es el t2 de Hotelling:
Donde n es el tamaño de la muestra, x es el vector de los medios de columna y S es un m × m matriz de covariancia de muestra.
Para una prueba multivariable de dos muestras, la hipótesis es que los vectores medios (μ1, μ2) de dos muestras son iguales. La estadística de prueba es el dos-sample t2 de Hotelling:
La prueba t de dos muestras es un caso especial de simple regresión lineal
El t-test de dos muestras es un caso especial de simple regresión lineal como lo ilustra el siguiente ejemplo.
Un ensayo clínico examina 6 pacientes con fármaco o placebo. 3 pacientes reciben 0 unidades de fármaco (grupo placebo). 3 pacientes reciben 1 unidad de fármaco (el grupo de tratamiento activo). Al final del tratamiento, los investigadores miden el cambio de base en el número de palabras que cada paciente puede recordar en una prueba de memoria.

Los datos y el código se proporcionan para el análisis utilizando el lenguaje de programación R con el
t.testylmfunciones para la prueba t y la regresión lineal. Aquí están los datos (ficticios) generados en R.> word.recall.data=data.frame(drug.dose=c(0,0,0,1,1,1), word.recall=c(1,2,3,5,6,7))Pacientes droga. dosis Word.recall 1 0 1 2 0 2 3 0 3 4 1 5 5 1 6 6 1 7 Realice la prueba t. Observe que el supuesto de igual varianza, var.equal=T, es necesario para hacer el análisis exactamente equivalente a la simple regresión lineal.
■ con()word.recall.data, t.test()Word.recall~droga. dosis, var.equal=T)
Ejecutar el código R da los siguientes resultados.
- La palabra mala. recordar en el grupo 0 droga. dosis es 2.
- La palabra mala. en el grupo de 1 droga. dosis es 6.
- La diferencia entre los grupos de tratamiento en la palabra media.recall es 6 – 2 = 4.
- La diferencia de palabra. recordar entre dosis de drogas es significativo (p=0.00805).
Realizar una regresión lineal de los mismos datos. Las cálculos se pueden realizar utilizando la función R
lm()para un modelo lineal.■ word.recall.data.lm = lm()Word.recall~droga. dosis, datos=word.recall.data)■ Resumen()word.recall.data.lm)
La regresión lineal proporciona una tabla de coeficientes y valores p.Coeficiente Estimación Std. Error valor t P-valor Intercepto 2 0,574 3.464 0,02572 droga. dosis 4 0.8165 4.899 0,000805 El cuadro de coeficientes da los siguientes resultados.
- El valor estimado de 2 para la interceptación es el valor medio de la palabra recordar cuando la dosis de drogas es 0.
- El valor estimado de 4 para la dosis de drogas indica que para un cambio de 1 unidad en la dosis de drogas (de 0 a 1) hay un cambio de 4 unidades en la palabra de memoria media (de 2 a 6). Esta es la pendiente de la línea que une los dos medios de grupo.
- El valor p que la pendiente de 4 es diferente de 0 es p = 0.00805.
Los coeficientes para la regresión lineal especifican la pendiente e interceptación de la línea que se une a los dos medios de grupo, como se ilustra en el gráfico. La interceptación es 2 y la pendiente es 4.
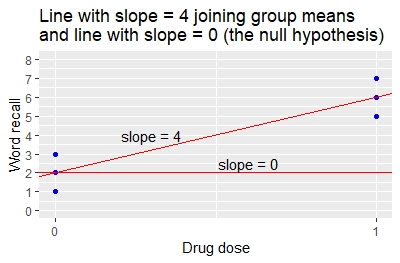
Compare el resultado de la regresión lineal al resultado de la prueba t.
- De la prueba t, la diferencia entre el grupo significa 6-2=4.
- De la regresión, la pendiente es también 4 indicando que un cambio de 1 unidad en la dosis de drogas (de 0 a 1) da un cambio de 4 unidades en la palabra de memoria media (de 2 a 6).
- El valor p-valor t-test para la diferencia en los medios, y el valor p-regreso para la pendiente, son ambos 0.00805. Los métodos dan resultados idénticos.
Este ejemplo muestra que, para el caso especial de una simple regresión lineal donde hay un solo x-variable que tiene valores 0 y 1, la prueba t da los mismos resultados que la regresión lineal. La relación también se puede mostrar algebraicamente.
Reconociendo esta relación entre la prueba t y la regresión lineal facilita el uso de múltiples regresiones lineales y análisis multi-way de la varianza. Estas alternativas a las pruebas t permiten la inclusión de variables explicativas adicionales asociadas a la respuesta. Incluir tales variables explicativas adicionales utilizando regresión o anova reduce la varianza no explicada de otra manera, y generalmente produce mayor potencia para detectar diferencias que hacer pruebas t de dos muestras.
Implementaciones de software
Muchos programas de hoja de cálculo y paquetes estadísticos, como QtiPlot, LibreOffice Calc,Microsoft Excel, SAS, SPSS, Stata, DAP, gretl, R, Python, PSPP, Wolfram Mathematica, MATLAB y Minitab, incluyen implementaciones de Student's t- Prueba.
Idioma/programa Función Notas Microsoft Excel pre 2010 TTEST(array1, array2, tails, type)Véase [1] Microsoft Excel 2010 y más tarde T.TEST(array1, array2, tails, type)Véase [2] Números de Apple TTEST(sample-1-values, sample-2-values, tails, test-type)Véase [3] LibreOffice Calc TTEST(Data1; Data2; Mode; Type)Véase [4] Hojas de Google TTEST(range1, range2, tails, type)Véase [5] Python scipy.stats.ttest_ind(a, b, equal_var=True)Véase [6] MATLAB ttest(data1, data2)Véase [7] Mathematica TTest[{data1,data2}]Véase [8] R t.test(data1, data2, var.equal=TRUE)Véase [9] SAS PROC TTESTVéase [10] Java tTest(sample1, sample2)Véase [11] Julia EqualVarianceTTest(sample1, sample2)Véase [12] Stata ttest data1 == data2Véase [13]











Contenido relacionado
Ley de los grandes números
Error de tipo I y de tipo II
Error estándar