
Probabilidad a priori
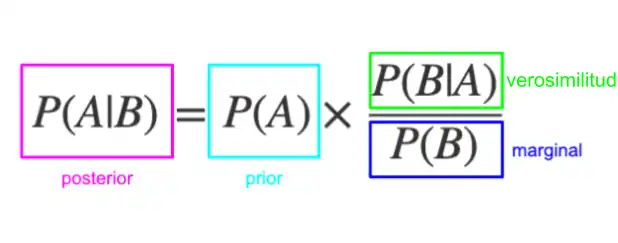
La probabilidad a priori o previa, es una estimación de la probabilidad de que ocurra un evento antes de observarlo o de tener en cuenta cualquier nueva evidencia. Esta suposición inicial tiene diferentes niveles de verosimilitud y ofrece información de tipo inferencial (deductiva) al observador sobre el comportamiento futuro del evento. La probabilidad a priori es especialmente importante en estadística bayesiana, donde la inferencia toma en cuenta los valores previos y posteriores al punto de observación. También es importante en áreas como filosofía del conocimiento.
Las probabilidades a priori permiten despejar un estado de incertidumbre inicial, evitar el sesgo inducido por la ausencia datos, y sanear datos previos desactualizados o mal distribuidos. Es importante diferenciar la probabilidad a priori –que refleja el conocimiento previo– de la probabilidad a posteriori, que se obtiene después de incorporar la nueva evidencia.
Un ejemplo de probabilidad previa, es la probabilidad de que una moneda desconocida caiga en "cara". Sin información sobre la moneda, aplicamos el principio de indiferencia: existen dos eventos posibles (cara o cruz), mutuamente excluyentes y con toda seguridad uno de ellos ocurrirá. Por lo tanto, la probabilidad a priori de obtener "cara" es 1/n, en este caso 1/2.
HSD
Probabilidad a priori en estadística bayesiana
Una distribución de probabilidad a priori de una cantidad incierta, a menudo llamada simplemente a priori , es su distribución de probabilidad asumida antes de que se tenga en cuenta alguna evidencia. Por ejemplo, el prior podría ser la distribución de probabilidad que representa las proporciones relativas de votantes que votarán por un político particular en una elección futura. La cantidad desconocida puede ser un parámetro del modelo o una variable latente en lugar de una variable observable.
En la estadística bayesiana, la regla de Bayes prescribe cómo actualizar la información anterior con nueva información para obtener la distribución de probabilidad posterior, que es la distribución condicional de la cantidad incierta dados los nuevos datos. Históricamente, la elección de priores a menudo se limitaba a una familia conjugada de una función de probabilidad dada, por lo que daría como resultado un posterior manejable de la misma familia. Sin embargo, la amplia disponibilidad de los métodos Monte Carlo de la cadena de Markov ha hecho que esto sea menos preocupante.
Hay muchas formas de construir una distribución previa. En algunos casos, se puede determinar un anterior a partir de información pasada, como experimentos anteriores. Un previo también puede obtenerse de la evaluación puramente subjetiva de un experto experimentado. Cuando no se disponga de información, podrá adoptarse un previo no informativo justificado por el principio de indiferencia. En las aplicaciones modernas, los prior también se eligen a menudo por sus propiedades mecánicas, como la regularización y la selección de características.
Las distribuciones previas de los parámetros del modelo a menudo dependerán de sus propios parámetros. La incertidumbre sobre estos hiperparámetros puede, a su vez, expresarse como distribuciones de probabilidad hiperprior. Por ejemplo, si se utiliza una distribución beta para modelar la distribución del parámetro p de una distribución de Bernoulli, entonces:
- p es un parámetro del sistema subyacente (distribución de Bernoulli), y
- α y β son parámetros de la distribución previa (distribución beta); de ahí los hiperparámetros .
En principio, los priores se pueden descomponer en muchos niveles condicionales de distribuciones, los llamados priores jerárquicos.
Nivel de verosimilitud de la probabilidad a priori
A priori informativo
Un previo informativo expresa información específica y definida sobre una variable. Un ejemplo es una distribución previa de la temperatura de mañana al mediodía. Un enfoque razonable es hacer que la distribución anterior sea normal con un valor esperado igual a la temperatura del mediodía de hoy, con una varianza igual a la varianza diaria de la temperatura atmosférica, o una distribución de la temperatura para ese día del año.
Este ejemplo tiene una propiedad en común con muchos anteriores, a saber, que el posterior de un problema (la temperatura de hoy) se convierte en el anterior de otro problema (la temperatura de mañana); La evidencia preexistente que ya ha sido tomada en cuenta es parte de la anterior y, a medida que se acumula más evidencia, la posterior está determinada en gran medida por la evidencia más que por cualquier supuesto original, siempre que el supuesto original admitiera la posibilidad de lo que es la evidencia. sugerencia. Los términos "anterior" y "posterior" generalmente se refieren a un dato u observación específica.
A priori fuertemente informativo
Un a priori fuerte es un supuesto, teoría, concepto o idea precedente sobre el cual, después de tener en cuenta nueva información, se funda un supuesto, teoría, concepto o idea actual. Un previo fuerte es un tipo de previo informativo en el que la información contenida en la distribución previa domina la información contenida en los datos que se analizan. El análisis bayesiano combina la información contenida en la distribución anterior con la extraída de los datos para producir la distribución posterior que, en el caso de una "prior fuerte", cambiaría poco con respecto a la distribución anterior.
A priori débilmente informativo
Un previo débilmente informativo expresa información parcial sobre una variable, dirigiendo el análisis hacia soluciones que se alinean con el conocimiento existente sin limitar demasiado los resultados y evitar estimaciones extremas. Un ejemplo es, al establecer la distribución previa para la temperatura de mañana al mediodía en St. Louis, usar una distribución normal con una media de 50 grados Fahrenheit y una desviación estándar de 40 grados, lo que restringe muy vagamente la temperatura al rango (10 grados, 90 grados). grados) con una pequeña probabilidad de estar por debajo de -30 grados o por encima de 130 grados. El propósito de un prior débilmente informativo es la regularización, es decir, mantener las inferencias en un rango razonable.
A priori poco informativo
Un prior poco informativo , plano o difuso expresa información vaga o general sobre una variable. El término "anterior poco informativo" es un nombre poco apropiado. Tal a priori también podría denominarse a priori no muy informativo , o a priori objetivo , es decir, uno que no se obtiene subjetivamente.
Los antecedentes no informativos pueden expresar información "objetiva" como "la variable es positiva" o "la variable es menor que algún límite". La regla más simple y antigua para determinar un prior no informativo es el principio de indiferencia, que asigna probabilidades iguales a todas las posibilidades. En los problemas de estimación de parámetros, el uso de un a priori no informativo normalmente produce resultados que no son muy diferentes del análisis estadístico convencional, ya que la función de probabilidad a menudo produce más información que el a priori no informativo.
Se han hecho algunos intentos de encontrar probabilidades a priori, es decir, distribuciones de probabilidad en algún sentido lógicamente requeridas por la naturaleza del propio estado de incertidumbre; Estos son un tema de controversia filosófica, con los bayesianos divididos aproximadamente en dos escuelas: "bayesianos objetivos", que creen que tales antecedentes existen en muchas situaciones útiles, y "bayesianos subjetivos" que creen que en la práctica los antecedentes generalmente representan juicios de opinión subjetivos que no puede justificarse rigurosamente (Williamson 2010). Quizás los argumentos más sólidos a favor del bayesianismo objetivo los dio Edwin T. Jaynes, basándose principalmente en las consecuencias de las simetrías y en el principio de máxima entropía.
Como ejemplo de priori a priori, según Jaynes (2003), consideremos una situación en la que se sabe que una pelota ha estado escondida debajo de uno de tres vasos, A, B o C, pero no hay otra información disponible sobre su ubicación. . En este caso, un prior uniforme de p ( A ) = p ( B ) = p ( C ) = 1/3 parece intuitivamente la única opción razonable. Más formalmente, podemos ver que el problema sigue siendo el mismo si intercambiamos las etiquetas ("A", "B" y "C") de las tazas. Por lo tanto, sería extraño elegir un a priori para el cual una permutación de las etiquetas provocaría un cambio en nuestras predicciones sobre en qué copa se encontrará la pelota; el prior uniforme es el único que conserva esta invariancia. Si se acepta este principio de invariancia, entonces se puede ver que el previo uniforme es el previo lógicamente correcto para representar este estado de conocimiento. Este prior es "objetivo" en el sentido de ser la elección correcta para representar un estado particular de conocimiento, pero no es objetivo en el sentido de ser una característica del mundo independiente del observador: en realidad la pelota existe bajo una copa particular. , y sólo tiene sentido hablar de probabilidades en esta situación si hay un observador con conocimiento limitado sobre el sistema.
Como ejemplo más polémico, Jaynes publicó un argumento basado en la invariancia del previo bajo un cambio de parámetros que sugiere que el previo que representa una incertidumbre completa sobre una probabilidad debería ser el previo de Haldane p (1 − p ) . El ejemplo que da Jaynes es el de encontrar una sustancia química en un laboratorio y preguntar si se disolverá en agua en experimentos repetidos. El prior de Haldane le da, con diferencia, el mayor peso a 

Se pueden construir prioridades que sean proporcionales a la medida de Haar si el espacio de parámetros X lleva una estructura de grupo natural que deja invariante nuestro estado de conocimiento bayesiano. Esto puede verse como una generalización del principio de invariancia utilizado para justificar el prior uniforme sobre las tres copas en el ejemplo anterior. Por ejemplo, en física podríamos esperar que un experimento dé los mismos resultados independientemente de nuestra elección del origen de un sistema de coordenadas. Esto induce la estructura de grupo del grupo de traducción en X , lo que determina la probabilidad a priori como una a priori constante impropia. De manera similar, algunas medidas son naturalmente invariantes ante la elección de una escala arbitraria (por ejemplo, ya sea que se utilicen centímetros o pulgadas, los resultados físicos deben ser iguales). En tal caso, el grupo de escala es la estructura del grupo natural, y el prior correspondiente en X es proporcional a 1/ x . A veces importa si utilizamos la medida de Haar invariante por la izquierda o por la derecha. Por ejemplo, las medidas de Haar invariantes izquierda y derecha en el grupo afín no son iguales. Berger (1985, p. 413) sostiene que la medida de Haar invariante por la derecha es la elección correcta.
Otra idea, defendida por Edwin T. Jaynes, es utilizar el principio de máxima entropía (MAXENT). La motivación es que la entropía de Shannon de una distribución de probabilidad mide la cantidad de información contenida en la distribución. Cuanto mayor es la entropía, menos información proporciona la distribución. Por lo tanto, al maximizar la entropía sobre un conjunto adecuado de distribuciones de probabilidad en X , se encuentra la distribución que es menos informativa en el sentido de que contiene la menor cantidad de información consistente con las restricciones que definen el conjunto. Por ejemplo, la entropía máxima previa en un espacio discreto, dado solo que la probabilidad está normalizada a 1, es la previa que asigna igual probabilidad a cada estado. Y en el caso continuo, la entropía máxima previa, dado que la densidad está normalizada con media cero y varianza unitaria, es la distribución normal estándar. El principio de entropía cruzada mínima generaliza MAXENT al caso de "actualizar" una distribución previa arbitraria con restricciones adecuadas en el sentido de máxima entropía.
José-Miguel Bernardo introdujo una idea relacionada, los priores de referencia. Aquí, la idea es maximizar la divergencia esperada de Kullback-Leibler de la distribución posterior en relación con la anterior. Esto maximiza la información posterior esperada sobre X cuando la densidad previa es p ( x ); por lo tanto, en cierto sentido, p ( x ) es el a priori "menos informativo" sobre X. El a priori de referencia se define en el límite asintótico, es decir, se considera el límite de los a priori así obtenidos cuando el número de puntos de datos llega al infinito. . En el presente caso, la divergencia KL entre las distribuciones anterior y posterior viene dada por

Aquí 



![{\displaystyle \log \,[p(x)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/14d7dce887b6d3319c586ebf1c3c4f67c41b5af9)
no depende de
![{\displaystyle KL=\int p(t)\int p(x\mid t)\log[p(x\mid t)]\,dx\,dt\,-\,\int \log[p(x )]\,\int p(t)p(x\mid t)\,dt\,dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b53acbaeae23a8e86a18a5a509e6a8be736b8257)
La integral interna en la segunda parte es la integral 
![{\displaystyle KL=\int p(t)\int p(x\mid t)\log[p(x\mid t)]\,dx\,dt\,-\,\int p(x)\log [p(x)]\,dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9e9bffc40482ce124d533b7bd01f3342a8a462b8)
Ahora usamos el concepto de entropía que, en el caso de distribuciones de probabilidad, es el valor esperado negativo del logaritmo de la función de masa o densidad de probabilidad o ![{\displaystyle H(x)=-\int p(x)\log[p(x)]\,dx.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8cc46eee434cdc4025f9c15d539246262db6c6c3)

En palabras, KL es el valor esperado negativo 

![{\displaystyle H=\log {\sqrt {2\pi e/[NI(x*)]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e4d98b49ae93de3be6a19c7d3bfcbd3a7a380139)
donde 

![{\displaystyle KL=-\log[1{\sqrt {kI(x*)}}]-\,\int p(x)\log[p(x)]\,dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/23d45b984081280f967ee89d88ab92d3780af0fe)
donde 
![{\displaystyle KL=-\int p(x)\log[p(x)/{\sqrt {kI(x)}}]\,dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/748ae60514e7ebdcb3b153adb295ac8212639642)
Se trata de una divergencia cuasi-KL ("cuasi" en el sentido de que la raíz cuadrada de la información de Fisher puede ser el núcleo de una distribución impropia). Debido al signo menos, debemos minimizarlo para maximizar la divergencia KL con la que comenzamos. El valor mínimo de la última ecuación ocurre cuando las dos distribuciones en el argumento del logaritmo, impropias o no, no divergen. Esto a su vez ocurre cuando la distribución previa es proporcional a la raíz cuadrada de la información de Fisher de la función de verosimilitud. Por lo tanto, en el caso de un solo parámetro, los antecedentes de referencia y los de Jeffreys son idénticos, aunque Jeffreys tiene una justificación muy diferente.
Los priores de referencia suelen ser los prioritarios objetivos de elección en problemas multivariados, ya que otras reglas (por ejemplo, la regla de Jeffreys) pueden dar lugar a prioritarios con comportamiento problemático.
Las distribuciones previas objetivas también pueden derivarse de otros principios, como la teoría de la información o la codificación (ver, por ejemplo, longitud mínima de la descripción) o estadísticas frecuentistas (las llamadas prioridades de coincidencia de probabilidad). Estos métodos se utilizan en la teoría de la inferencia inductiva de Solomonoff. La construcción de antecedentes objetivos se ha introducido recientemente en bioinformática, y especialmente en la inferencia en biología de sistemas cancerosos, donde el tamaño de la muestra es limitado y se encuentra disponible una gran cantidad de conocimiento previo . En estos métodos, se utiliza un criterio basado en la teoría de la información, como la divergencia KL o la función de probabilidad logarítmica para problemas de aprendizaje supervisado binario y problemas de modelos mixtos.
Los problemas filosóficos asociados con antecedentes poco informativos están asociados con la elección de una métrica o escala de medición adecuada. Supongamos que queremos una información previa para la velocidad de carrera de un corredor que no conocemos. Podríamos especificar, digamos, una distribución normal como prior para su velocidad, pero alternativamente podríamos especificar una prior normal para el tiempo que tarda en completar 100 metros, que es proporcional al recíproco de la primera prior. Se trata de antecedentes muy diferentes, pero no está claro cuál es el preferido. El método de Jaynes de transformación de grupos puede responder a esta pregunta en algunas situaciones.
De manera similar, si se nos pide que estimemos una proporción desconocida entre 0 y 1, podríamos decir que todas las proporciones son igualmente probables y utilizar un a priori uniforme. Alternativamente, podríamos decir que todos los órdenes de magnitud de la proporción son igualmente probables, laprior logarítmico , que es el prior uniforme del logaritmo de proporción. El a priori de Jeffreys intenta resolver este problema calculando un a priori que expresa la misma creencia sin importar qué métrica se utilice. La recomendación de Jeffreys para una proporción desconocidapesp(1 − p), que difiere de la recomendación de Jaynes.
Los a priori basados en nociones de probabilidad algorítmica se utilizan en la inferencia inductiva como base para la inducción en entornos muy generales.
Los problemas prácticos asociados con antecedentes poco informativos incluyen el requisito de que la distribución posterior sea adecuada. Los habituales antecedentes poco informativos sobre variables continuas e ilimitadas son inadecuados. Esto no tiene por qué ser un problema si la distribución posterior es adecuada. Otra cuestión de importancia es que si se va a utilizar un previo no informativo de forma rutinaria , es decir, con muchos conjuntos de datos diferentes, debe tener buenas propiedades frecuentistas. Normalmente, a un bayesiano no le preocuparían estos problemas, pero puede ser importante en esta situación. Por ejemplo, uno querría que cualquier regla de decisión basada en la distribución posterior fuera admisible bajo la función de pérdida adoptada. Desafortunadamente, a menudo es difícil comprobar la admisibilidad, aunque se conocen algunos resultados (por ejemplo, Berger y Strawderman 1996). El problema es particularmente grave con los modelos jerárquicos de Bayes; los antecedentes habituales (por ejemplo, el de Jeffreys) pueden dar reglas de decisión muy inadmisibles si se emplean en los niveles más altos de la jerarquía.
A priori inadecuado
Dejemos que los eventos 

entonces está claro que se obtendría el mismo resultado si todas las probabilidades anteriores P ( A i ) y P ( A j ) se multiplicaran por una constante dada; lo mismo sería cierto para una variable aleatoria continua. Si la suma en el denominador converge, las probabilidades posteriores aún sumarán (o se integrarán) a 1 incluso si los valores anteriores no lo hacen, por lo que es posible que solo sea necesario especificar los anteriores en la proporción correcta. Llevando esta idea más allá, en muchos casos es posible que la suma o integral de los valores anteriores ni siquiera necesite ser finita para obtener respuestas sensatas para las probabilidades posteriores. Cuando este es el caso, el prior se llama prior impropio . Sin embargo, la distribución posterior no tiene por qué ser una distribución adecuada si la anterior es incorrecta. Esto queda claro en el caso en el que el evento B es independiente de todos los A j .
Los estadísticos a veces utilizan antecedentes inadecuados como antecedentes no informativos. Por ejemplo, si necesitan una distribución previa para la media y la varianza de una variable aleatoria, pueden suponer p ( m , v ) ~ 1/ v (para v > 0), lo que sugeriría que cualquier valor de la media es "igualmente igual". probable" y que un valor para la varianza positiva se vuelve "menos probable" en proporción inversa a su valor. Muchos autores (Lindley, 1973; De Groot, 1937; Kass y Wasserman, 1996) advierten contra el peligro de sobreinterpretar esos antecedentes, ya que no son densidades de probabilidad. La única relevancia que tienen se encuentra en el posterior correspondiente, siempre que esté bien definido para todas las observaciones. (El prior de Haldane es un contraejemplo típico ) .
Por el contrario, no es necesario integrar las funciones de probabilidad, y una función de probabilidad que es uniformemente 1 corresponde a la ausencia de datos (todos los modelos son igualmente probables si no hay datos): la regla de Bayes multiplica un a priori por la probabilidad, y un El producto vacío es solo la probabilidad constante 1. Sin embargo, sin comenzar con una distribución de probabilidad previa, no se termina obteniendo una distribución de probabilidad posterior y, por lo tanto, no se pueden integrar ni calcular los valores esperados o la pérdida. Consulte Función de probabilidad § No integrabilidad para obtener más detalles.
Ejemplos
Ejemplos de antecedentes inadecuados incluyen:
- La distribución uniforme en un intervalo infinito (es decir, una media línea o la línea real completa).
- Beta(0,0), la distribución beta para α=0, β=0 (distribución uniforme en escala de probabilidades logarítmicas).
- El prior logarítmico sobre los reales positivos (distribución uniforme en escala logarítmica).
Estas funciones, interpretadas como distribuciones uniformes, también pueden interpretarse como la función de probabilidad en ausencia de datos, pero no son antecedentes adecuados.
Probabilidad a priori en mecánica estadística
La probabilidad a priori tiene una importante aplicación en la mecánica estadística. La versión clásica se define como la relación entre el número de eventos elementales (p. ej., el número de veces que se lanza un dado) y el número total de eventos, y estos se consideran puramente deductivos, es decir, sin experimentar. En el caso del dado, si lo miramos sobre la mesa sin tirarlo, se razona deductivamente que cada evento elemental tiene la misma probabilidad; por lo tanto, la probabilidad de cada resultado de un lanzamiento imaginario del dado (perfecto) o simplemente contando el número de caras es 1/6. Cada cara del dado aparece con la misma probabilidad, siendo la probabilidad una medida definida para cada evento elemental. El resultado es diferente si tiramos el dado veinte veces y preguntamos cuántas veces (de 20) aparece el número 6 en la cara superior. En este caso entra en juego el tiempo y tenemos un tipo diferente de probabilidad dependiendo del tiempo o del número de veces que se tire el dado. Por otro lado, la probabilidad a priori es independiente del tiempo, puedes mirar el dado sobre la mesa todo el tiempo que quieras sin tocarlo y deduces que la probabilidad de que aparezca el número 6 en la cara superior es 1/6.
En mecánica estadística, por ejemplo, la de un gas contenido en un volumen finito 














donde 




estos estados son indistinguibles (es decir, estos estados no llevan etiquetas). Una consecuencia importante es un resultado conocido como el teorema de Liouville, es decir, la independencia temporal de este elemento de volumen del espacio de fase y, por lo tanto, de la probabilidad a priori. Una dependencia temporal de esta cantidad implicaría información conocida sobre la dinámica del sistema y, por lo tanto, no sería una probabilidad a priori. Así la región

cuando se diferencia con respecto al tiempo
En la teoría cuántica completa se tiene una ley de conservación análoga. En este caso, la región del espacio de fases se reemplaza por un subespacio del espacio de estados expresado en términos de un operador de proyección 

donde 
Ejemplos
El siguiente ejemplo ilustra la probabilidad a priori (o ponderación a priori) en contextos (a) clásicos y (b) cuánticos.
(a) Probabilidad clásica a priori
Considere la energía de rotación E de una molécula diatómica con momento de inercia I en coordenadas polares esféricas 

La 


Integrando sobre 

y, por lo tanto, la ponderación clásica a priori en el rango de energía 



(b) Probabilidad cuántica a priori
Suponiendo que el número de estados cuánticos en un rango 


siendo cada nivel de este tipo (2n+1) veces degenerado. Al evaluar 

Así, en comparación con 

Así, la ponderación a priori en el contexto clásico (a) corresponde a la ponderación a priori aquí en el contexto cuántico (b). En el caso del oscilador armónico simple unidimensional de frecuencia natural, 


En el caso del átomo de hidrógeno o potencial de Coulomb (donde la evaluación del volumen del espacio de fase para energía constante es más complicada) se sabe que la degeneración mecánica cuántica es 


Funciones de distribución en probabilidad a priori
En mecánica estadística (ver cualquier libro) se derivan las llamadas funciones de distribución 

Estas funciones se obtienen para (1) un sistema en equilibrio dinámico (es decir, en condiciones constantes y uniformes) con (2) un número total (y enorme) de partículas 





Por lo tanto 



Dado que

Expresando esta ecuación en términos de sus derivadas parciales, se obtiene la ecuación de transporte de Boltzmann. ¿Cómo aparecen aquí de repente las coordenadas, 
Contenido relacionado
Causalidad de Granger
Función de riesgo
Probabilidad bayesiana