
Distribución exponencial
En teoría de probabilidad y estadística, la distribución exponencial es la distribución de probabilidad del tiempo entre eventos en un proceso de punto de Poisson, es decir, un proceso en el que los eventos ocurren de forma continua e independiente a una tasa promedio constante. Es un caso particular de la distribución gamma. Es el análogo continuo de la distribución geométrica y tiene la propiedad clave de no tener memoria. Además de ser utilizado para el análisis de los procesos de puntos de Poisson, se encuentra en varios otros contextos.
La distribución exponencial no es lo mismo que la clase de familias de distribuciones exponenciales. Esta es una gran clase de distribuciones de probabilidad que incluye la distribución exponencial como uno de sus miembros, pero también incluye muchas otras distribuciones, como las distribuciones normal, binomial, gamma y de Poisson.
Definiciones
Función de densidad de probabilidad
La función de densidad de probabilidad (pdf) de una distribución exponencial es
- <math alttext="{displaystyle f(x;lambda)={begin{cases}lambda e^{-lambda x}&xgeq 0,\0&xf()x;λ λ )={}λ λ e− − λ λ xx≥ ≥ 0,0x.0.{displaystyle f(x;lambda)={begin{cases}lambda e^{-lambda x} diezxgeq 0, consiguió0.end{cases}}}}<img alt="{displaystyle f(x;lambda)={begin{cases}lambda e^{-lambda x}&xgeq 0,\0&x
Aquí λ > 0 es el parámetro de la distribución, a menudo llamado parámetro de tasa. La distribución se admite en el intervalo [0, ∞). Si una variable aleatoria X tiene esta distribución, escribimos X ~ Exp(λ).
La distribución exponencial exhibe una divisibilidad infinita.
Función de distribución acumulativa
La función de distribución acumulativa viene dada por
- <math alttext="{displaystyle F(x;lambda)={begin{cases}1-e^{-lambda x}&xgeq 0,\0&xF()x;λ λ )={}1− − e− − λ λ xx≥ ≥ 0,0x.0.{displaystyle F(x;lambda)={begin{cases}1-e^{-lambda x} limitxgeq 0, consiguió0.end{cases}}<img alt="F(x;lambda) = begin{cases} 1-e^{-lambda x} & x ge 0, \ 0 & x
Parametrización alternativa
La distribución exponencial a veces se parametriza en términos del parámetro de escala β = 1/λ, que también es el significado:
Propiedades
Media, varianza, momentos y mediana


El valor medio o esperado de una variable aleatoria distribuida exponencialmente X con parámetro de tasa λ viene dado por
![{displaystyle operatorname {E} [X]={frac {1}{lambda }}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f9efa3ce3c964c59532609b3d6b8f01ce88f6221)
A la luz de los ejemplos que se dan a continuación, esto tiene sentido: si recibe llamadas telefónicas a una tasa promedio de 2 por hora, entonces puede esperar media hora por cada llamada.
La varianza de X viene dada por
![{displaystyle operatorname {Var} [X]={frac {1}{lambda ^{2}}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3c450db5013b1cfdaf5ea71106c9d13834e02d61)
Los momentos de X, para n▪ ▪ N{displaystyle nin mathbb {N} son dados por

![{displaystyle operatorname {E} left[X^{n}right]={frac {n!}{lambda ^{n}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5f5d3a82fbcff5a294e5360fb05b1e5f2166ec09)
Los momentos centrales de X, para n▪ ▪ N{displaystyle nin mathbb {N} son dados por

La mediana de X viene dada por
de acuerdo con la desigualdad mediana-media.
Sin memoria
Una variable aleatoria distribuida exponencialmente T obedece a la relación
Esto se puede ver considerando la función de distribución acumulativa complementaria:
Cuando T se interpreta como el tiempo de espera para que ocurra un evento relativo a un tiempo inicial, esta relación implica que, si T está condicionado a la falta de observación el evento durante un período de tiempo inicial s, la distribución del tiempo de espera restante es la misma que la distribución incondicional original. Por ejemplo, si un evento no ha ocurrido después de 30 segundos, la probabilidad condicional de que ocurra al menos 10 segundos más es igual a la probabilidad incondicional de observar el evento más de 10 segundos después del tiempo inicial.
La distribución exponencial y la distribución geométrica son las únicas distribuciones de probabilidad sin memoria.
La distribución exponencial es, en consecuencia, también necesariamente la única distribución de probabilidad continua que tiene una tasa de falla constante.
Cuantiles

La función cuantil (función de distribución acumulativa inversa) para Exp(λ) es
Los cuartiles son por lo tanto:
- primer cuartil: ln(4/3)/λ
- median: ln(2)/λ
- tercer cuartil: ln(4)/λ
Y como consecuencia el rango intercuartílico es ln(3)/λ.
Divergencia Kullback-Leibler
La divergencia dirigida Kullback-Leibler en nats de eλ λ {displaystyle e^{lambda } ("aproximadamente" distribución) de eλ λ 0{displaystyle e^{lambda - Sí. ('true' distribution) es dada por



Distribución máxima de entropía
Entre todas las distribuciones de probabilidad continuas con soporte [0, ∞) y media μ, la distribución exponencial con λ = 1/μ tiene la mayor entropía diferencial. En otras palabras, es la distribución de probabilidad de máxima entropía para un variable aleatorio X que es mayor o igual a cero y para el cual E[X] es fijo.
Distribución del mínimo de variables aleatorias exponenciales
Sean X1, …, Xn independientes distribuidos exponencialmente variables aleatorias con parámetros de tasa λ1, …, λn. Después


Esto se puede ver considerando la función de distribución acumulativa complementaria:
El índice de la variable que alcanza el mínimo se distribuye según la distribución categórica

Una prueba puede ser vista por dejar I=argmini▪ ▪ {}1,⋯ ⋯ ,n} {}X1,...... ,Xn}{displaystyle I=operatorname {argmin} _{iin {1,dot s ¿Qué?. Entonces,

Tenga en cuenta que

Momentos conjuntos de i.i.d. estadísticas de orden exponencial
Vamos X1,...... ,Xn{displaystyle X_{1},dotscX_{n} Ser n{displaystyle n} variables exponenciales aleatorias independientes y distribuidas idénticamente con parámetro de tasa λ. Vamos X()1),...... ,X()n){displaystyle X_{(1)},dotscX_{(n)} denota las estadísticas correspondientes del orden. Para <math alttext="{displaystyle ii.j{displaystyle i donej}<img alt="i el momento conjunto E [X()i)X()j)]{displaystyle operatorname {E} left[X_{(i)}X_{(j)}right]} de las estadísticas del orden X()i){displaystyle X_{(i)} y X()j){displaystyle X_{(j)}} es dado por



![{displaystyle operatorname {E} left[X_{(i)}X_{(j)}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7d350557a602c2566c092558fff0aefb0049c7c9)


![{displaystyle {begin{aligned}operatorname {E} left[X_{(i)}X_{(j)}right]&=sum _{k=0}^{j-1}{frac {1}{(n-k)lambda }}operatorname {E} left[X_{(i)}right]+operatorname {E} left[X_{(i)}^{2}right]\&=sum _{k=0}^{j-1}{frac {1}{(n-k)lambda }}sum _{k=0}^{i-1}{frac {1}{(n-k)lambda }}+sum _{k=0}^{i-1}{frac {1}{((n-k)lambda)^{2}}}+left(sum _{k=0}^{i-1}{frac {1}{(n-k)lambda }}right)^{2}.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0135f144a56c4b7565f7faa61cc3abb42afe9c0d)
Esto se puede ver invocando la ley de expectativa total y la propiedad sin memoria:
![{displaystyle {begin{aligned}operatorname {E} left[X_{(i)}X_{(j)}right]&=int _{0}^{infty }operatorname {E} left[X_{(i)}X_{(j)}mid X_{(i)}=xright]f_{X_{(i)}}(x),dx\&=int _{x=0}^{infty }xoperatorname {E} left[X_{(j)}mid X_{(j)}geq xright]f_{X_{(i)}}(x),dx&&left({textrm {since}}~X_{(i)}=ximplies X_{(j)}geq xright)\&=int _{x=0}^{infty }xleft[operatorname {E} left[X_{(j)}right]+xright]f_{X_{(i)}}(x),dx&&left({text{by the memoryless property}}right)\&=sum _{k=0}^{j-1}{frac {1}{(n-k)lambda }}operatorname {E} left[X_{(i)}right]+operatorname {E} left[X_{(i)}^{2}right].end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be5949313f3639a86ac81484ac8ca7f4f9edb4d4)
La primera ecuación se deriva de la ley de la expectativa total. La segunda ecuación explota el hecho de que una vez que condicionamos X()i)=x{displaystyle X_{(i)}=x}, debe seguir eso X()j)≥ ≥ x{displaystyle X_{(j)}geq x}. La tercera ecuación depende de la propiedad sin memoria para reemplazar E [X()j)▪ ▪ X()j)≥ ≥ x]{displaystyle operatorname {E} left[X_{(j)}mid X_{(j)}geq xright]} con E [X()j)]+x{displaystyle operatorname {E} left[X_{(j)}right]+x}.


![{displaystyle operatorname {E} left[X_{(j)}mid X_{(j)}geq xright]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/00169b33907d379235fd4561c63c13d4c51a619a)
![{displaystyle operatorname {E} left[X_{(j)}right]+x}](https://wikimedia.org/api/rest_v1/media/math/render/svg/775aa6cfd6c5d2b1e4b70ce3108a17f93f7b0224)
Suma de dos variables aleatorias exponenciales independientes
La función de distribución de probabilidad (PDF) de una suma de dos variables aleatorias independientes es la evolución de sus PDF individuales. Si X1{displaystyle X_{1} y X2{displaystyle X_{2} son variables exponenciales independientes al azar con los respectivos parámetros de velocidad λ λ 1{displaystyle lambda ¿Qué? y λ λ 2,{displaystyle lambda _{2},} entonces la densidad de probabilidad de Z=X1+X2{displaystyle Z=X_{1}+X_{2} es dado por





![{displaystyle {begin{aligned}f_{Z}(z)&=int _{-infty }^{infty }f_{X_{1}}(x_{1})f_{X_{2}}(z-x_{1}),dx_{1}\&=int _{0}^{z}lambda _{1}e^{-lambda _{1}x_{1}}lambda _{2}e^{-lambda _{2}(z-x_{1})},dx_{1}\&=lambda _{1}lambda _{2}e^{-lambda _{2}z}int _{0}^{z}e^{(lambda _{2}-lambda _{1})x_{1}},dx_{1}\&={begin{cases}{dfrac {lambda _{1}lambda _{2}}{lambda _{2}-lambda _{1}}}left(e^{-lambda _{1}z}-e^{-lambda _{2}z}right)&{text{ if }}lambda _{1}neq lambda _{2}\[4pt]lambda ^{2}ze^{-lambda z}&{text{ if }}lambda _{1}=lambda _{2}=lambda.end{cases}}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c2db15dda49fe8482485a68c9d7c9b1c1d46ee95)



En el caso de parámetros de igual tasa, el resultado es una distribución de Erlang con forma 2 y parámetro λ λ ,{displaystyle lambda} que a su vez es un caso especial de distribución gamma.

Distribuciones relacionadas
- If X ~ Laplace(μ, β−1), then |X − μ| ~ Exp(β).
- If X ~ Pareto(1, λ), then log(X) ~ Exp(λ).
- If X ~ SkewLogistic(θ), then log ( 1 + e − X ) ∼ Exp ( θ ) {displaystyle log left(1+e^{-X}right)sim operatorname {Exp} (theta)} .
- If Xi ~ U(0, 1) then lim n → ∞ n min ( X 1 , … , X n ) ∼ Exp ( 1 ) {displaystyle lim _{nto infty }nmin left(X_{1},ldotsX_{n}right)sim operatorname {Exp} (1)}
- The exponential distribution is a limit of a scaled beta distribution: lim n → ∞ n Beta ( 1 , n ) = Exp ( 1 ) . {displaystyle lim _{nto infty }noperatorname {Beta} (1,n)=operatorname {Exp} (1).}
- Exponential distribution is a special case of type 3 Pearson distribution.
- If X ~ Exp(λ) and Xi ~ Exp(λi) then:
- k X ∼ Exp ( λ k ) {displaystyle kXsim operatorname {Exp} left({frac {lambda }{k}}right)} , closure under scaling by a positive factor.
- 1 + X ~ BenktanderWeibull(λ, 1), which reduces to a truncated exponential distribution.
- keX ~ Pareto(k, λ).
- e−X ~ Beta(λ, 1).
- 1/keX ~ PowerLaw(k, λ)
- X ∼ Rayleigh ( 1 2 λ ) {displaystyle {sqrt {X}}sim operatorname {Rayleigh} left({frac {1}{sqrt {2lambda }}}right)} , the Rayleigh distribution
- X ∼ Weibull ( 1 λ , 1 ) {displaystyle Xsim operatorname {Weibull} left({frac {1}{lambda }},1right)} , the Weibull distribution
- X 2 ∼ Weibull ( 1 λ 2 , 1 2 ) {displaystyle X^{2}sim operatorname {Weibull} left({frac {1}{lambda ^{2}}},{frac {1}{2}}right)}
- μ − β log(λX) ∼ Gumbel(μ, β).
- ⌊ X ⌋ ∼ Geometric ( 1 − e − λ ) {displaystyle lfloor Xrfloor sim operatorname {Geometric} left(1-e^{-lambda }right)} , a geometric distribution on 0,1,2,3,...
- ⌈ X ⌉ ∼ Geometric ( 1 − e − λ ) {displaystyle lceil Xrceil sim operatorname {Geometric} left(1-e^{-lambda }right)} , a geometric distribution on 1,2,3,4,...
- If also Y ~ Erlang(n, λ) or Y ∼ Γ ( n , 1 λ ) {displaystyle Ysim Gamma left(n,{frac {1}{lambda }}right)} then X Y + 1 ∼ Pareto ( 1 , n ) {displaystyle {frac {X}{Y}}+1sim operatorname {Pareto} (1,n)}
- If also λ ~ Gamma(k, θ) (shape, scale parametrisation) then the marginal distribution of X is Lomax(k, 1/θ), the gamma mixture
- λ1X1 − λ2Y2 ~ Laplace(0, 1).
- min{X1,..., Xn} ~ Exp(λ1 +... + λn).
- If also λi = λ then:
- X 1 + ⋯ + X k = ∑ i X i ∼ {displaystyle X_{1}+cdots +X_{k}=sum _{i}X_{i}sim } Erlang(k, λ) = Gamma(k, λ−1) = Gamma(k, λ) (in (k, θ) and (α, β) parametrization, respectively) with an integer shape parameter k.
- Xi − Xj ~ Laplace(0, λ−1).
- If also Xi are independent, then:
- X i X i + X j {displaystyle {frac {X_{i}}{X_{i}+X_{j}}}} ~ U(0, 1)
- Z = λ i X i λ j X j {displaystyle Z={frac {lambda _{i}X_{i}}{lambda _{j}X_{j}}}} has probability density function f Z ( z ) = 1 ( z + 1 ) 2 {displaystyle f_{Z}(z)={frac {1}{(z+1)^{2}}}} . This can be used to obtain a confidence interval for λ i λ j {displaystyle {frac {lambda _{i}}{lambda _{j}}}} .
- If also λ = 1:
- μ − β log ( e − X 1 − e − X ) ∼ Logistic ( μ , β ) {displaystyle mu -beta log left({frac {e^{-X}}{1-e^{-X}}}right)sim operatorname {Logistic} (mubeta)} , the logistic distribution
- μ − β log ( X i X j ) ∼ Logistic ( μ , β ) {displaystyle mu -beta log left({frac {X_{i}}{X_{j}}}right)sim operatorname {Logistic} (mubeta)}
- μ − σ log(X) ~ GEV(μ, σ, 0).
- Further if Y ∼ Γ ( α , β α ) {displaystyle Ysim Gamma left(alpha{frac {beta }{alpha }}right)} then X Y ∼ K ( α , β ) {displaystyle {sqrt {XY}}sim operatorname {K} (alphabeta)} (K-distribution)
- If also λ = 1/2 then X ∼ χ2
2; i.e., X has a chi-squared distribution with 2 degrees of freedom. Hence:Exp ( λ ) = 1 2 λ Exp ( 1 2 ) ∼ 1 2 λ χ 2 2 ⇒ ∑ i = 1 n Exp ( λ ) ∼ 1 2 λ χ 2 n 2 {displaystyle operatorname {Exp} (lambda)={frac {1}{2lambda }}operatorname {Exp} left({frac {1}{2}}right)sim {frac {1}{2lambda }}chi _{2}^{2}Rightarrow sum _{i=1}^{n}operatorname {Exp} (lambda)sim {frac {1}{2lambda }}chi _{2n}^{2}}
- If X ∼ Exp ( 1 λ ) {displaystyle Xsim operatorname {Exp} left({frac {1}{lambda }}right)} and Y ∣ X {displaystyle Ymid X} ~ Poisson(X) then Y ∼ Geometric ( 1 1 + λ ) {displaystyle Ysim operatorname {Geometric} left({frac {1}{1+lambda }}right)} (geometric distribution)
- The Hoyt distribution can be obtained from exponential distribution and arcsine distribution
- The exponential distribution is a limit of the κ-exponential distribution in the κ = 0 {displaystyle kappa =0} case.
- Exponential distribution is a limit of the κ-Generalized Gamma distribution in the
α
=
1
{displaystyle alpha =1}
and
ν
=
1
{displaystyle nu =1}
cases:
- lim ( α , ν ) → ( 0 , 1 ) p κ ( x ) = ( 1 + κ ν ) ( 2 κ ) ν Γ ( 1 2 κ + ν 2 ) Γ ( 1 2 κ − ν 2 ) α λ ν Γ ( ν ) x α ν − 1 exp κ ( − λ x α ) = λ e − λ x {displaystyle lim _{(alphanu)to (0,1)}p_{kappa }(x)=(1+kappa nu)(2kappa)^{nu }{frac {Gamma {Big (}{frac {1}{2kappa }}+{frac {nu }{2}}{Big)}}{Gamma {Big (}{frac {1}{2kappa }}-{frac {nu }{2}}{Big)}}}{frac {alpha lambda ^{nu }}{Gamma (nu)}}x^{alpha nu -1}exp _{kappa }(-lambda x^{alpha })=lambda e^{-lambda x}}




























Otras distribuciones relacionadas:
- Distribución hiper-exponencial – la distribución cuya densidad es una suma ponderada de densidades exponenciales.
- Distribución hipoexponencial – distribución de una suma general de variables aleatorias exponenciales.
- exDistribución gaussiana – la suma de una distribución exponencial y una distribución normal.
Inferencia estadística
A continuación, suponga variable aleatoria X se distribuye exponencialmente con parámetro de tasa λ, y x1,...... ,xn{displaystyle x_{1},dotscx_{n} son n muestras independientes de X, con medio de muestra x̄ ̄ {displaystyle {bar {x}}.


Estimación de parámetros
El estimador de máxima verosimilitud para λ se construye de la siguiente manera.
La función de verosimilitud para λ, dada una muestra independiente e idénticamente distribuida x = (x1, …, xn) extraído de la variable, es:

donde:

La derivada del logaritmo de la función de verosimilitud es:
En consecuencia, la estimación de máxima verosimilitud para el parámetro de tasa es:

Esto es no un estimador imparcial de λ λ ,{displaystyle lambda} aunque x̄ ̄ {displaystyle {overline {x}}} es un estimador imparcial de MLE 1/λ λ {displaystyle 1/lambda } y la distribución significa.


El sesgo de λ λ ^ ^ mle{displaystyle {widehat {lambda } es igual a

![{displaystyle Bequiv operatorname {E} left[left({widehat {lambda }}_{text{mle}}-lambda right)right]={frac {lambda }{n-1}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6df9c9d7b6d1a8ffc31748e7cdf0cc750b442e4)

Se puede encontrar un minimizador aproximado del error cuadrático medio (ver también: equilibrio entre sesgo y varianza), suponiendo un tamaño de muestra mayor que dos, con un factor de corrección para el MLE:


Información del pescador
La información Fisher, denotada I()λ λ ){displaystyle {mathcal {}}(lambda)}, para un estimador del parámetro de tasa λ λ {displaystyle lambda } se da como:


![{displaystyle {mathcal {I}}(lambda)=operatorname {E} left[left.left({frac {partial }{partial lambda }}log f(x;lambda)right)^{2}right|lambda right]=int left({frac {partial }{partial lambda }}log f(x;lambda)right)^{2}f(x;lambda),dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2c70bd835b54bb1b7f344dbf1f04d170bd1d4852)
Conectando la distribución y resolviendo da:

Esto determina la cantidad de información que cada muestra independiente de una distribución exponencial lleva alrededor del parámetro de tasa desconocida λ λ {displaystyle lambda }.
Intervalos de confianza
El intervalo de confianza de 100(1 − α)% para el parámetro de tasa de una distribución exponencial viene dado por:
p,v100(p)vχ2
p,v

Esta aproximación puede ser aceptable para muestras que contengan al menos 15 a 20 elementos.
Inferencia bayesiana
El conjugado previo de la distribución exponencial es la distribución gamma (de la cual la distribución exponencial es un caso especial). La siguiente parametrización de la función de densidad de probabilidad gamma es útil:

La distribución posterior p se puede expresar en términos de la función de probabilidad definida anteriormente y una gamma previa:

Ahora se ha especificado la densidad posterior p hasta una constante de normalización faltante. Dado que tiene la forma de un pdf gamma, esto se puede completar fácilmente y se obtiene:

Aquí, el hiperparámetro α se puede interpretar como el número de observaciones anteriores y β como la suma de las observaciones anteriores. La media posterior aquí es:

Ocurrencia y aplicaciones
Ocurrencia de eventos
La distribución exponencial ocurre naturalmente cuando se describe la duración de los tiempos entre llegadas en un proceso de Poisson homogéneo.
La distribución exponencial puede verse como una contraparte continua de la distribución geométrica, que describe el número de ensayos de Bernoulli necesarios para que un proceso discreto cambie de estado. Por el contrario, la distribución exponencial describe el tiempo que tarda un proceso continuo en cambiar de estado.
En escenarios del mundo real, la suposición de una tasa constante (o probabilidad por unidad de tiempo) rara vez se cumple. Por ejemplo, la tasa de llamadas telefónicas entrantes difiere según la hora del día. Pero si nos enfocamos en un intervalo de tiempo durante el cual la tasa es más o menos constante, como de 2 a 4 p.m. durante los días laborales, la distribución exponencial se puede utilizar como un buen modelo aproximado para el tiempo hasta que llegue la próxima llamada telefónica. Se aplican advertencias similares a los siguientes ejemplos que producen variables distribuidas aproximadamente exponencialmente:
- El tiempo hasta que una partícula radiactiva decae, o el tiempo entre los clics de un contador Geiger
- El tiempo que tarda antes de su próxima llamada telefónica
- El tiempo hasta el incumplimiento (en pago a los titulares de deuda de la empresa) en el modelado de riesgo de crédito de forma reducida
Las variables exponenciales también se pueden usar para modelar situaciones en las que ciertos eventos ocurren con una probabilidad constante por unidad de longitud, como la distancia entre mutaciones en una hebra de ADN o entre atropellos en una carretera determinada.
En la teoría de las colas, los tiempos de servicio de los agentes en un sistema (por ejemplo, cuánto tarda un cajero bancario, etc. en atender a un cliente) a menudo se modelan como variables distribuidas exponencialmente. (La llegada de clientes, por ejemplo, también está modelada por la distribución de Poisson si las llegadas son independientes y se distribuyen de manera idéntica). La duración de un proceso que puede considerarse como una secuencia de varias tareas independientes sigue la distribución de Erlang (que es la distribución de la suma de varias variables independientes distribuidas exponencialmente). La teoría de la confiabilidad y la ingeniería de confiabilidad también hacen un uso extensivo de la distribución exponencial. Debido a la propiedad memoryless de esta distribución, es adecuada para modelar la porción de tasa de riesgo constante de la curva de la bañera utilizada en la teoría de confiabilidad. También es muy conveniente porque es muy fácil agregar tasas de falla en un modelo de confiabilidad. Sin embargo, la distribución exponencial no es apropiada para modelar la vida útil general de organismos o dispositivos técnicos, porque las "tasas de falla" aquí no son constantes: ocurren más fallas para sistemas muy jóvenes y para sistemas muy antiguos.
En física, si observa un gas a una temperatura y presión fijas en un campo gravitacional uniforme, las alturas de las distintas moléculas también siguen una distribución exponencial aproximada, conocida como fórmula barométrica. Esto es una consecuencia de la propiedad de entropía que se menciona a continuación.
En hidrología, la distribución exponencial se utiliza para analizar valores extremos de variables tales como valores máximos mensuales y anuales de lluvia diaria y volúmenes de descarga de ríos.
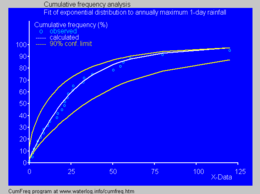
- El cuadro azul ilustra un ejemplo de equiparar la distribución exponencial para clasificar anualmente las precipitaciones máximas de un día mostrando también el cinturón de confianza del 90% basado en la distribución binomio. Los datos de precipitaciones están representados por posiciones de trama como parte del análisis de frecuencia acumulativa.
En la gestión de quirófanos, la distribución de la duración de la cirugía para una categoría de cirugías sin un contenido de trabajo típico (como en una sala de emergencias, englobando todo tipo de cirugías).
Predicción
Habiendo observado una muestra de n puntos de datos de una distribución exponencial desconocida, una tarea común es usar estas muestras para hacer predicciones sobre datos futuros de la misma fuente. Una distribución predictiva común sobre muestras futuras es la llamada distribución de complemento, formada al conectar una estimación adecuada para el parámetro de velocidad λ en la función de densidad exponencial. Una opción común de estimación es la proporcionada por el principio de máxima verosimilitud, y su uso produce la densidad predictiva sobre una muestra futura xn+1, condicionado a las muestras observadas x = (x1,..., xn) dado por

El enfoque bayesiano proporciona una distribución predictiva que tiene en cuenta la incertidumbre del parámetro estimado, aunque esto puede depender de forma crucial de la elección de la distribución previa.
Una distribución predictiva libre de los problemas de elección de priores que surgen bajo el enfoque subjetivo bayesiano es

que se puede considerar como
- una distribución de confianza frecuente, obtenida de la distribución de la cantidad pivotal xn+1/x̄ ̄ {displaystyle {x_{n+1}/{overline {x}};
- una probabilidad predictiva de perfil, obtenida eliminando el parámetro λ de la probabilidad conjunta de xn+ 1 y λ por maximización;
- un objetivo Bayesian predictivo posterior distribución, obtenido utilizando los Jeffreys no-informativos antes 1/λ;
- la distribución predictiva de la probabilidad máxima normalizada condicional (CNML), a partir de consideraciones teóricas de información.

La precisión de una distribución predictiva se puede medir usando la distancia o divergencia entre la distribución exponencial real con parámetro de tasa, λ0, y la distribución predictiva basada en la muestra x. La divergencia de Kullback-Leibler es una medida libre de parametrización de uso común de la diferencia entre dos distribuciones. Si Δ(λ0||p) denota la divergencia de Kullback-Leibler entre una exponencial con parámetro de tasa λ 0 y una distribución predictiva p se puede demostrar que
![{displaystyle {begin{aligned}operatorname {E} _{lambda _{0}}left[Delta (lambda _{0}parallel p_{rm {ML}})right]&=psi (n)+{frac {1}{n-1}}-log(n)\operatorname {E} _{lambda _{0}}left[Delta (lambda _{0}parallel p_{rm {CNML}})right]&=psi (n)+{frac {1}{n}}-log(n)end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/02702bfd262096d01f27b67eab961ff7ccb512a9)
donde se toma la expectativa con respecto a la distribución exponencial con parámetro de tasa λ0 ∈ (0, ∞), y ψ(·) es la función digamma. Está claro que la distribución predictiva de CNML es estrictamente superior a la distribución complementaria de máxima verosimilitud en términos de divergencia promedio de Kullback-Leibler para todos los tamaños de muestra n > 0.
Generación de variables aleatorias
Un método conceptualmente muy simple para generar variables exponenciales se basa en el muestreo por transformada inversa: Dada una variable aleatoria U extraída de la distribución uniforme en el intervalo unitario (0, 1), la variable

tiene una distribución exponencial, donde F−1 es la función cuantil, definida por

Además, si U es uniforme en (0, 1), entonces también lo es 1 − U. Esto significa que uno puede generar variables exponenciales de la siguiente manera:

Knuth y Devroye analizan otros métodos para generar variables exponenciales.
También está disponible un método rápido para generar un conjunto de variables exponenciales ordenadas sin usar una rutina de clasificación.
Contenido relacionado
Ecuación de pell
Necesidad y suficiencia
Límite (topología)