
Desviación mediana
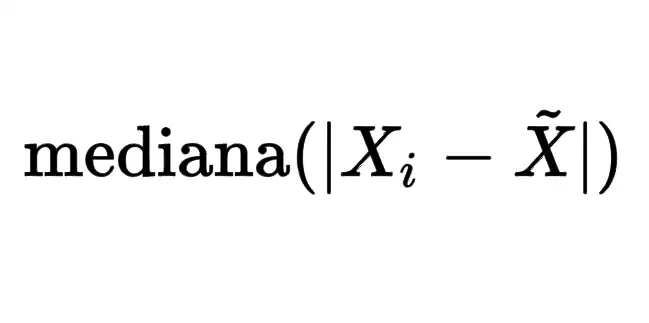
La desviación mediana absoluta o simplemente desviación mediana, es una forma de medir la dispersión estadística de un conjunto de datos usando las diferencias absolutas entre cada unidad estadística y la mediana del conjunto de datos. En otras palabras, es la mediana de las desviaciones absolutas de la mediana del conjunto. No debe confundirse con la desviación media.
Para calcular la desviación mediana se debe:
- Encontrar la diferencia absoluta entre cada punto de datos y la mediana.
- Calcular la mediana de estas diferencias absolutas.
La desviación mediana se considera una medida robusta de la dispersión (variabilidad) de un conjunto de datos cuantitativos univariados, a diferencia de la varianza o de la desviación estándar, que se ven más afectadas por valores extremos y distribuciones no-normales. Un bajo valor de desviación mediana indica que los datos están cerca de la mediana y tienen baja variabilidad. Un alto valor de desviación mediana significa que los datos están lejos de la mediana y tienen alta variabilidad.
La desviación mediana no solo se aplica descriptivamente a muestras de datos, sino que también puede extenderse para inferir el parámetro correspondiente en una población completa. Esto se logra a través del cálculo de la desviación mediana en una muestra representativa, ofreciendo una visión de la variabilidad poblacional.
Es importante señalar que la desviación mediana no se calcula directamente sobre el conjunto de datos, sino sobre el conjunto resultante de las medianas del conjunto (residual), medidas solo en sus valores absolutos, de allí su nombre. Por lo que la desviación mediana no presenta datos sobre la población, sino exclusivamente cuantifica la variabilidad.
Este enfoque residual, centrado en la mediana para evaluar la variabilidad asegura que la desviación mediana sea menos susceptible a las fluctuaciones extremas en los datos, comparada con otras medidas de dispersión, y es ampliamente aceptada como una medida de variabilidad robusta y fiable.
HSD
Ejemplo
Considere los datos (1, 1, 2, 2, 4, 6, 9). Tiene un valor mediano de 2. Las desviaciones absolutas sobre 2 son (1, 1, 0, 0, 2, 4, 7) que a su vez tienen un valor mediano de 1 (porque las desviaciones absolutas ordenadas son (0, 0, 1, 1, 2, 4, 7)). Entonces, la desviación absoluta mediana para estos datos es 1.
Usos
La desviación absoluta mediana es una medida de dispersión estadística. Además, la MAD es una estadística robusta, siendo más resistente a los valores atípicos en un conjunto de datos que la desviación estándar. En la desviación estándar, las distancias desde la media se elevan al cuadrado, por lo que las desviaciones grandes se ponderan más y, por lo tanto, los valores atípicos pueden influir en gran medida. En el MAD, las desviaciones de un pequeño número de valores atípicos son irrelevantes.
Debido a que la MAD es un estimador de escala más sólido que la varianza muestral o la desviación estándar, funciona mejor con distribuciones sin media o varianza, como la distribución de Cauchy.
Relación con la desviación estándar
La MAD se puede usar de manera similar a como se usaría la desviación para el promedio. Para utilizar la MAD como un estimador consistente para la estimación de la desviación estándar 

donde 
Para los datos normalmente distribuidos

es decir, el recíproco de la función cuantil 



Por lo tanto, debemos tener que

notando que

tenemos eso 

Otra forma de establecer la relación es notar que MAD es igual a la media de la distribución normal:

Esta forma se utiliza, por ejemplo, en el error probable.
Desviación absoluta de una mediana geométrica
De manera similar a cómo la mediana se generaliza a la mediana geométrica en datos multivariados, se puede construir una MAD geométrica que generalice la MAD. Dado un par de datos bidimensionales (X 1, Y 1 ), (X 2, Y 2),..., (X n, Y n) y una mediana geométrica adecuadamente calculada 

Esto da el mismo resultado que el MAD univariante en 1 dimensión y se extiende fácilmente a dimensiones superiores. En el caso de valores complejos (X +i Y), la relación de MAD con la desviación estándar no cambia para los datos normalmente distribuidos.
Población estimada por desviación mediana
La MAD poblacional se define de manera análoga a la MAD muestral, pero se basa en la distribución completa y no en una muestra. Para una distribución simétrica con media cero, la población MAD es el percentil 75 de la distribución.
A diferencia de la varianza, que puede ser infinita o indefinida, la MAD poblacional es siempre un número finito. Por ejemplo, la distribución estándar de Cauchy tiene una varianza indefinida, pero su MAD es 1.
La primera mención conocida del concepto de MAD se produjo en 1816, en un artículo de Carl Friedrich Gauss sobre la determinación de la precisión de las observaciones numéricas.
Contenido relacionado
Ciencias formales
Modelo estadístico
Rango intercuartil