
Carácter (informática)
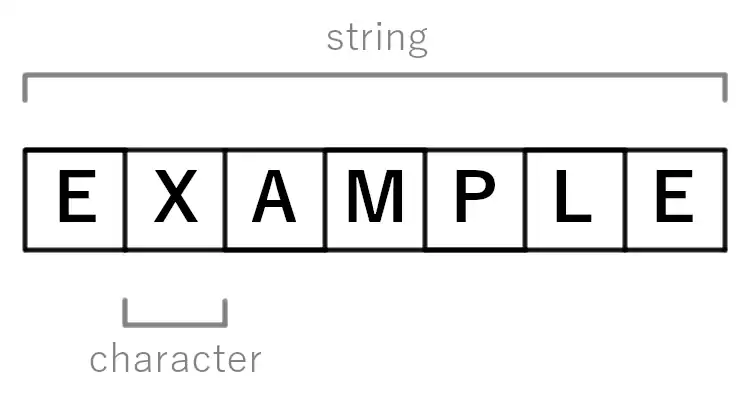
En informática y telecomunicaciones, el término carácter o caracter [caractér] se refiere a una unidad básica de información correspondiente a un grafema, símbolo o elemento básico de un alfabeto o silabario. Un carácter representa un elemento visual que forma parte de un sistema de escritura, siendo el componente fundamental para la representación de textos en dispositivos digitales y en la transmisión de datos.
Es importante entender que un carácter en informática puede ser más allá que letras o números convencionales. También incluye signos de puntuación, símbolos especiales y, en algunos sistemas de codificación, incluso instrucciones (no visibles directamente) que cumplen funciones de control.
Los caracteres en informática abarcan una amplia gama de elementos. Incluyen letras, números, signos de puntuación comunes como el punto "." o el guión "-", y espacios en blanco. Además, el concepto de carácter engloba a los caracteres de control. Estos no representan símbolos visibles, sino que son instrucciones para el formateo o procesamiento del texto. Ejemplos de caracteres de control son el retorno y el tabulador, así como instrucciones específicas para impresoras y otros dispositivos que manejan texto.
Los caracteres suelen agruparse en secuencias conocidas como "strings" cadenas, para el procesamiento digital de textos.
Históricamente, el término "carácter" se refería a un número específico de bits contiguos. Tradicionalmente, se asociaba un carácter con 8 bits (un byte). Sin embargo, en el pasado, se han utilizado otros formatos, como el carácter de 6 bits y el código Baudot de 5 bits. Incluso se llegó a utilizar una configuración de 4 bits, con solo 16 valores posibles. En la actualidad, los sistemas modernos emplean secuencias de tamaño variable de estas unidades fijas. Por ejemplo, UTF-8 utiliza un número variable de unidades de código de 8 bits para definir un "punto de código", mientras que Unicode usa una cantidad variable de estas unidades para definir un "carácter".
HSD
"Encoding"
Las computadoras y los equipos de comunicación representan caracteres mediante una codificación de caracteres que asigna cada carácter a algo (una cantidad entera representada por una secuencia de dígitos, por lo general) que se puede almacenar o transmitir a través de una red. Dos ejemplos de codificaciones habituales son ASCII y la codificación UTF-8 para Unicode. Si bien la mayoría de las codificaciones de caracteres asignan caracteres a números y/o secuencias de bits, el código Morse representa los caracteres mediante una serie de impulsos eléctricos de longitud variable.
Terminología
Históricamente, el término carácter ha sido ampliamente utilizado por los profesionales de la industria para referirse a un carácter codificado, a menudo según lo define el lenguaje de programación o la API. Asimismo, conjunto de caracteres se ha utilizado ampliamente para referirse a un repertorio específico de caracteres que se han asignado a secuencias de bits o códigos numéricos específicos. El término glifo se usa para describir una apariencia visual particular de un personaje. Muchas fuentes de computadora consisten en glifos que están indexados por el código numérico del carácter correspondiente.
Con el advenimiento y la aceptación generalizada de Unicode y los conjuntos de caracteres codificados agnósticos en bits, un carácter se ve cada vez más como una unidad de información, independiente de cualquier manifestación visual en particular. El estándar internacional ISO/IEC 10646 (Unicode) define carácter, o carácter abstracto como "un miembro de un conjunto de elementos utilizados para la organización, control o representación de datos". La definición de Unicode complementa esto con notas explicativas que alientan al lector a diferenciar entre caracteres, grafemas y glifos, entre otras cosas. Tal diferenciación es un ejemplo del tema más amplio de la separación de presentación y contenido.
Por ejemplo, los matemáticos suelen utilizar la letra hebrea alef ("א") para denotar ciertos tipos de infinito (ℵ), pero también se usa en el texto hebreo ordinario. En Unicode, estos dos usos se consideran caracteres diferentes y tienen dos identificadores numéricos Unicode diferentes ("puntos de código"), aunque pueden representarse de forma idéntica. Por el contrario, el logograma chino para agua ("水") puede tener una apariencia ligeramente diferente en los textos japoneses que en los textos chinos, y los tipos de letra locales pueden reflejar esto. Sin embargo, en Unicode se consideran el mismo carácter y comparten el mismo punto de código.
El estándar Unicode también diferencia entre estos caracteres abstractos y los caracteres codificados o caracteres codificados que se han emparejado con códigos numéricos que facilitan su representación en ordenadores.
Combinación de caracteres
Unicode también aborda el carácter de combinación. Por ejemplo, Unicode asigna un punto de código a cada uno de
- "i" (U+0069),
- la combinación de diaeresis (U+0308), y
- "ï" (U+00EF).
Esto hace posible codificar el carácter medio de la palabra 'naïve' ya sea como un solo carácter 'ï' o como combinación del carácter 'i ' con la diéresis combinatoria: (U+0069 LETRA I MINÚSCULA LATINA + U+0308 DIÉRESIS COMBINADA); esto también se traduce como 'ï '.
Estos se consideran canónicamente equivalentes según el estándar Unicode.
"Char" en C
Un char en el lenguaje de programación C es un tipo de datos con el tamaño de exactamente un byte, que a su vez se define para ser lo suficientemente grande como para contener cualquier miembro de la "ejecución básica juego de caracteres". El número exacto de bits se puede verificar mediante la macro CHAR_BIT. Con mucho, el tamaño más común es de 8 bits y el estándar POSIX requiere que sea de 8 bits. En los estándares C más nuevos, se requiere char para contener unidades de código UTF-8, lo que requiere un tamaño mínimo de 8 bits.
Un punto de código Unicode puede requerir hasta 21 bits. Esto no cabe en un char en la mayoría de los sistemas, por lo que se usa más de uno para algunos de ellos, como en la codificación de longitud variable UTF-8, donde cada punto de código ocupa de 1 a 4 bytes. Además, un "personaje" puede requerir más de un punto de código (por ejemplo, con la combinación de caracteres), dependiendo de lo que signifique la palabra "carácter".
El hecho de que un carácter se almacenó históricamente en un solo byte llevó a que los dos términos ("char" y "character") se usaran indistintamente en la mayoría de la documentación. Esto a menudo hace que la documentación sea confusa o engañosa cuando se utilizan codificaciones multibyte como UTF-8, y ha llevado a implementaciones ineficientes e incorrectas de funciones de manipulación de cadenas (como calcular la "longitud" de una cadena como un conteo de unidades de código en lugar de bytes). La documentación moderna de POSIX intenta arreglar esto, definiendo "carácter" como una secuencia de uno o más bytes que representan un solo símbolo gráfico o código de control, e intenta usar "byte" cuando se refiere a datos de caracteres. Sin embargo, todavía contiene errores como definir una matriz de char como una matriz de caracteres (en lugar de una matriz de bytes).
Unicode también se puede almacenar en cadenas formadas por unidades de código que son más grandes que char. Estos se denominan "caracteres anchos". El tipo C original se llamaba wchar_t. Debido a que algunas plataformas definen wchar_t como 16 bits y otras lo definen como 32 bits, las versiones recientes han agregado char16_t, char32_t. Incluso entonces, los objetos que se almacenan pueden no ser caracteres, por ejemplo, el UTF-16 de longitud variable a menudo se almacena en matrices de char16_t.
Otros idiomas también tienen un tipo char. Algunos, como C++, usan 8 bits como C. Otros, como Java, usan 16 bits para char para representar valores UTF-16.
"Char" en Java
Java tiene un tipo de dato primitivo llamado char para caracteres. char en Java es un carácter Unicode de 16 bits. Dado que Java usa Unicode, puede representar una amplia gama de caracteres más allá del conjunto estándar ASCII.
"String" en PHP
PHP usa el tipo de dato string para caracteres, ya que no tiene un tipo de dato char específico como C. Los caracteres en PHP son esencialmente cadenas con una longitud de uno. Las cadenas de PHP son secuencias de bytes, y su manejo puede variar en base a la codificación de caracteres (como UTF-8).
"Rune" en Golang (Go)
Go tiene un tipo de dato distinto llamado rune para caracteres. Un rune representa un punto de código Unicode y es un alias para int32. Go también soporta el tipo de dato byte, que representa caracteres ASCII, y es un alias para uint8.
Contenido relacionado
Tarjeta perforada
Arquitectura de harvard
Proceso (informática)