
Histograma

Un histograma es una representación aproximada de la distribución de datos numéricos. El término fue introducido por primera vez por Karl Pearson. Para construir un histograma, el primer paso es "agrupar" (o "depositar") el rango de valores, es decir, dividir todo el rango de valores en una serie de intervalos, y luego contar cuántos valores caen en cada intervalo. Los contenedores generalmente se especifican como intervalos consecutivos que no se superponen de una variable. Los contenedores (intervalos) deben ser adyacentes y a menudo (pero no es obligatorio que lo sean) del mismo tamaño.
Si los contenedores son del mismo tamaño, se erige un rectángulo sobre el contenedor con una altura proporcional a la frecuencia: el número de casos en cada contenedor. También se puede normalizar un histograma para mostrar frecuencias "relativas". Luego muestra la proporción de casos que caen en cada una de varias categorías, con la suma de las alturas igual a 1.
Sin embargo, no es necesario que los contenedores tengan el mismo ancho; en ese caso, el rectángulo erigido se define para tener su área proporcional a la frecuencia de casos en el contenedor. Entonces, el eje vertical no es la frecuencia sino la densidad de frecuencia, el número de casos por unidad de la variable en el eje horizontal. Los ejemplos de ancho de bandeja variable se muestran en los datos de la oficina del censo a continuación.
Como los contenedores adyacentes no dejan espacios, los rectángulos de un histograma se tocan para indicar que la variable original es continua.
Los histogramas dan una idea aproximada de la densidad de la distribución subyacente de los datos y, a menudo, para la estimación de la densidad: estimación de la función de densidad de probabilidad de la variable subyacente. El área total de un histograma utilizado para la densidad de probabilidad siempre se normaliza a 1. Si la longitud de los intervalos en el eje x son todos 1, entonces un histograma es idéntico a una gráfica de frecuencia relativa.
Se puede pensar en un histograma como una estimación de densidad de kernel simplista, que utiliza un kernel para suavizar las frecuencias en los contenedores. Esto produce una función de densidad de probabilidad más suave, que en general reflejará con mayor precisión la distribución de la variable subyacente. La estimación de la densidad podría trazarse como una alternativa al histograma y, por lo general, se dibuja como una curva en lugar de un conjunto de cuadros. No obstante, los histogramas son los preferidos en las aplicaciones, cuando es necesario modelar sus propiedades estadísticas. La variación correlacionada de una estimación de densidad kernel es muy difícil de describir matemáticamente, mientras que es simple para un histograma en el que cada contenedor varía de forma independiente.
Una alternativa a la estimación de la densidad del kernel es el histograma desplazado promedio, que es rápido de calcular y brinda una estimación de curva suave de la densidad sin usar kernels.
El histograma es una de las siete herramientas básicas del control de calidad.
Los histogramas a veces se confunden con los gráficos de barras. Se usa un histograma para datos continuos, donde los contenedores representan rangos de datos, mientras que un gráfico de barras es un gráfico de variables categóricas. Algunos autores recomiendan que los gráficos de barras tengan espacios entre los rectángulos para aclarar la distinción.
Ejemplos

Estos son los datos del histograma de la derecha, utilizando 500 elementos:
| Contenedor/Intervalo | Recuento/Frecuencia |
|---|---|
| −3,5 a −2,51 | 9 |
| −2,5 a −1,51 | 32 |
| −1,5 a −0,51 | 109 |
| −0,5 a 0,49 | 180 |
| 0,5 a 1,49 | 132 |
| 1,5 a 2,49 | 34 |
| 2,5 a 3,49 | 4 |
Las palabras utilizadas para describir los patrones en un histograma son: "simétrico", "sesgado a la izquierda" o "a la derecha", "unimodal", "bimodal" o "multimodal".
 simétrica, unimodal
simétrica, unimodal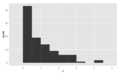 sesgado a la derecha
sesgado a la derecha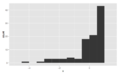 sesgado a la izquierda
sesgado a la izquierda bimodal
bimodal Multimodal
Multimodal Simétrico
Simétrico
Es una buena idea trazar los datos utilizando varios anchos de bandeja diferentes para obtener más información al respecto. Aquí hay un ejemplo de consejos dados en un restaurante.
 Consejos con un ancho de contenedor de $1, sesgado a la derecha, unimodal
Consejos con un ancho de contenedor de $1, sesgado a la derecha, unimodal Consejos que usan un ancho de bin de 10c, todavía sesgados a la derecha, multimodal con modos en $ y montos de 50c, indica redondeo, también algunos valores atípicos
Consejos que usan un ancho de bin de 10c, todavía sesgados a la derecha, multimodal con modos en $ y montos de 50c, indica redondeo, también algunos valores atípicos
La Oficina del Censo de EE. UU. descubrió que había 124 millones de personas que trabajaban fuera de sus hogares. Usando sus datos sobre el tiempo ocupado por el viaje al trabajo, la siguiente tabla muestra el número absoluto de personas que respondieron con tiempos de viaje "al menos 30 pero menos de 35 minutos" es más alto que los números de las categorías por encima y por debajo. Es probable que esto se deba a que las personas redondearon el tiempo de viaje informado. El problema de reportar valores como números redondeados arbitrariamente es un fenómeno común cuando se recopilan datos de personas.
| Intervalo | Ancho | Cantidad | Cantidad/ancho |
|---|---|---|---|
| 0 | 5 | 4180 | 836 |
| 5 | 5 | 13687 | 2737 |
| 10 | 5 | 18618 | 3723 |
| 15 | 5 | 19634 | 3926 |
| 20 | 5 | 17981 | 3596 |
| 25 | 5 | 7190 | 1438 |
| 30 | 5 | 16369 | 3273 |
| 35 | 5 | 3212 | 642 |
| 40 | 5 | 4122 | 824 |
| 45 | 15 | 9200 | 613 |
| 60 | 30 | 6461 | 215 |
| 90 | 60 | 3435 | 57 |
Este histograma muestra el número de casos por unidad de intervalo como la altura de cada bloque, de modo que el área de cada bloque es igual al número de personas de la encuesta que entran en su categoría. El área bajo la curva representa el número total de casos (124 millones). Este tipo de histograma muestra números absolutos, con Q en miles.
| Intervalo | Ancho | Cantidad (Q) | Q/total/ancho |
|---|---|---|---|
| 0 | 5 | 4180 | 0.0067 |
| 5 | 5 | 13687 | 0.0221 |
| 10 | 5 | 18618 | 0.0300 |
| 15 | 5 | 19634 | 0.0316 |
| 20 | 5 | 17981 | 0.0290 |
| 25 | 5 | 7190 | 0.0116 |
| 30 | 5 | 16369 | 0.0264 |
| 35 | 5 | 3212 | 0.0052 |
| 40 | 5 | 4122 | 0.0066 |
| 45 | 15 | 9200 | 0.0049 |
| 60 | 30 | 6461 | 0.0017 |
| 90 | 60 | 3435 | 0.0005 |
Este histograma difiere del primero solo en la escala vertical. El área de cada bloque es la fracción del total que representa cada categoría, y el área total de todas las barras es igual a 1 (la fracción significa "todas"). La curva que se muestra es una estimación de densidad simple. Esta versión muestra proporciones y también se conoce como histograma de unidad de área.
En otras palabras, un histograma representa una distribución de frecuencias por medio de rectángulos cuyos anchos representan intervalos de clase y cuyas áreas son proporcionales a las frecuencias correspondientes: la altura de cada uno es la densidad de frecuencia promedio del intervalo. Los intervalos se colocan juntos para mostrar que los datos representados por el histograma, aunque exclusivos, también son contiguos. (Por ejemplo, en un histograma es posible tener dos intervalos de conexión de 10,5 a 20,5 y de 20,5 a 33,5, pero no dos intervalos de conexión de 10,5 a 20,5 y 22,5 a 32,5. Los intervalos vacíos se representan como vacíos y no se saltan).

Definiciones matemáticas
Los datos utilizados para construir un histograma se generan a través de una función m i que cuenta el número de observaciones que caen en cada una de las categorías separadas (conocidas como bins). Por lo tanto, si hacemos que n sea el número total de observaciones y k sea el número total de bins, los datos del histograma m i cumplen las siguientes condiciones:

Histograma acumulativo
Un histograma acumulativo es un mapeo que cuenta el número acumulativo de observaciones en todos los contenedores hasta el contenedor especificado. Es decir, el histograma acumulativo M i de un histograma m j se define como:

Número de contenedores y ancho
No hay un número "mejor" de contenedores, y los diferentes tamaños de contenedores pueden revelar diferentes características de los datos. La agrupación de datos es al menos tan antigua como el trabajo de Graunt en el siglo XVII, pero no se dieron pautas sistemáticas hasta el trabajo de Sturges en 1926.
El uso de contenedores más anchos donde la densidad de los puntos de datos subyacentes es baja reduce el ruido debido a la aleatoriedad del muestreo; el uso de contenedores más estrechos donde la densidad es alta (para que la señal ahogue el ruido) da una mayor precisión a la estimación de la densidad. Por lo tanto, puede ser beneficioso variar el ancho del contenedor dentro de un histograma. No obstante, los contenedores de igual ancho son ampliamente utilizados.
Algunos teóricos han intentado determinar un número óptimo de contenedores, pero estos métodos generalmente hacen fuertes suposiciones sobre la forma de la distribución. Según la distribución real de los datos y los objetivos del análisis, pueden ser apropiados diferentes anchos de intervalo, por lo que generalmente se necesita experimentación para determinar un ancho apropiado. Sin embargo, existen varias pautas y reglas generales útiles.
El número de contenedores k puede asignarse directamente o puede calcularse a partir de un ancho de contenedor h sugerido como:

Las llaves indican la función de techo.
Opción de raíz cuadrada

que toma la raíz cuadrada de la cantidad de puntos de datos en la muestra (utilizada por los histogramas de Analysis Toolpak de Excel y muchos otros) y redondea al siguiente número entero.
Fórmula de Sturges
La fórmula de Sturges se deriva de una distribución binomial e implícitamente supone una distribución aproximadamente normal.

La fórmula de Sturges basa implícitamente los tamaños de los contenedores en el rango de los datos y puede tener un rendimiento deficiente si n < 30, porque el número de contenedores será pequeño (menos de siete) y es poco probable que muestre bien las tendencias en los datos. En el otro extremo, la fórmula de Sturges puede sobrestimar el ancho del contenedor para conjuntos de datos muy grandes, lo que da como resultado histogramas demasiado suavizados. También puede funcionar mal si los datos no se distribuyen normalmente.
Cuando se compara con la regla de Scott y la regla de Terrell-Scott, otras dos fórmulas ampliamente aceptadas para intervalos de histogramas, el resultado de la fórmula de Sturges es más cercano cuando n ≈ 100.
Regla del arroz
![{displaystyle k=lceil 2{sqrt[{3}]{n}}rceil,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/10afe41745cb092987fd396321e42a29ec385623)
La regla de Rice se presenta como una alternativa simple a la regla de Sturges.
Fórmula de Doane
La fórmula de Doane es una modificación de la fórmula de Sturges que intenta mejorar su rendimiento con datos no normales.

donde 

Regla de referencia normal de Scott
El ancho del contenedor 
![{displaystyle h={frac {3,49{sombrero {sigma}}}{raíz cuadrada[{3}]{n}}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a7c27e8297b12a864e4820cb56e64daf436b790f)
donde 
La elección de Freedman-Diaconis
La regla de Freedman-Diaconis da el ancho del contenedor
![{displaystyle h=2{frac {operatorname {IQR} (x)}{sqrt[{3}]{n}}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/66ab98a5a6eac6044fa3ba3cf5caabb5e6d07288)
que se basa en el rango intercuartílico, denotado por IQR. Reemplaza 3.5σ de la regla de Scott con 2 IQR, que es menos sensible que la desviación estándar a valores atípicos en los datos.
Minimización del error cuadrático estimado de validación cruzada
Este enfoque de minimizar el error cuadrático medio integrado de la regla de Scott se puede generalizar más allá de las distribuciones normales, mediante el uso de una validación cruzada de exclusión:

Aquí, 
La elección de Shimazaki y Shinomoto
La elección se basa en la minimización de una función de riesgo L estimada

donde 




Anchos de contenedores variables
En lugar de elegir contenedores espaciados uniformemente, para algunas aplicaciones es preferible variar el ancho del contenedor. Esto evita bins con conteos bajos. Un caso común es elegir contenedores equiprobables, donde se espera que el número de muestras en cada contenedor sea aproximadamente igual. Los contenedores se pueden elegir de acuerdo con alguna distribución conocida o se pueden elegir en función de los datos, de modo que cada contenedor tenga 
Para bins equiprobables, se sugiere la siguiente regla para el número de bins:

Esta elección de contenedores está motivada por maximizar el poder de una prueba de chi-cuadrado de Pearson que prueba si los contenedores contienen el mismo número de muestras. Más específicamente, para un intervalo de confianza dado, 

Donde 



Observación
Una buena razón por la que el número de contenedores debe ser proporcional a ![{raíz cuadrada[ {3}]{n}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b780c7060d1bc0ab596390e950dc537cee82af1a)





![{displaystyle s/{sqrt[{3}]{n}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/adb970135fc8968694cb4c3494e5b847667acb8b)

Aplicaciones
- En hidrología, el histograma y la función de densidad estimada de la precipitación y los datos de descarga del río, analizados con una distribución de probabilidad, se utilizan para obtener información sobre su comportamiento y frecuencia de ocurrencia. Un ejemplo se muestra en la figura azul.
- En muchos programas de procesamiento de imágenes digitales hay una herramienta de histograma, que le muestra la distribución del contraste/brillo de los píxeles.
Contenido relacionado
Población estadística
Gráfico anamórfico
Prueba de Kolmogorov-Smirnov