
Regresión logística

En estadística, el modelo logístico (o modelo logit) es un modelo estadístico que modela la probabilidad de que ocurra un evento al tener las probabilidades logarítmicas para el evento ser una combinación lineal de una o más variables independientes. En el análisis de regresión, la regresión logística (o regresión logit) estima los parámetros de un modelo logístico (los coeficientes en la combinación lineal). Formalmente, en la regresión logística binaria hay una sola variable dependiente binaria, codificada por una variable indicadora, donde los dos valores están etiquetados como "0" y "1", mientras que las variables independientes pueden ser cada una una variable binaria (dos clases, codificadas por una variable indicadora) o una variable continua (cualquier valor real). La probabilidad correspondiente del valor etiquetado como "1" puede variar entre 0 (ciertamente el valor "0") y 1 (ciertamente el valor "1"), de ahí el etiquetado; la función que convierte log-odds en probabilidad es la función logística, de ahí el nombre. La unidad de medida para la escala log-odds se llama logit, de logistic unit, por lo tanto los nombres alternativos. Ver § Antecedentes y § Definición para matemáticas formales, y § Ejemplo para un ejemplo resuelto.
Las variables binarias se utilizan ampliamente en estadística para modelar la probabilidad de que ocurra una determinada clase o evento, como la probabilidad de que un equipo gane, que un paciente esté sano, etc. (ver § Aplicaciones), y el modelo logístico ha sido el modelo más utilizado para la regresión binaria desde aproximadamente 1970. Las variables binarias se pueden generalizar a variables categóricas cuando hay más de dos valores posibles (por ejemplo, si una imagen es de un gato, un perro, un león, etc.), y la regresión logística binaria generalizada a regresión logística multinomial. Si las categorías múltiples están ordenadas, se puede usar la regresión logística ordinal (por ejemplo, el modelo logístico ordinal de probabilidades proporcionales). Ver § Extensiones para obtener más extensiones. El modelo de regresión logística en sí mismo simplemente modela la probabilidad de salida en términos de entrada y no realiza una clasificación estadística (no es un clasificador), aunque puede usarse para hacer un clasificador, por ejemplo, eligiendo un valor de corte y clasificando entradas con probabilidad mayor que el límite como una clase, por debajo del límite como la otra; esta es una forma común de hacer un clasificador binario.
También se pueden utilizar modelos lineales análogos para variables binarias con una función sigmoidea diferente en lugar de la función logística (para convertir la combinación lineal en una probabilidad), sobre todo el modelo probit; ver § Alternativas. La característica definitoria del modelo logístico es que el aumento de una de las variables independientes escala multiplicativamente las probabilidades del resultado dado a una tasa constante, donde cada variable independiente tiene su propio parámetro; para una variable dependiente binaria, esto generaliza la razón de probabilidades. De manera más abstracta, la función logística es el parámetro natural de la distribución de Bernoulli y, en este sentido, es la función "más simple" manera de convertir un número real a una probabilidad. En particular, maximiza la entropía (minimiza la información agregada) y, en este sentido, hace la menor cantidad de suposiciones de los datos que se modelan; ver § Entropía máxima.
Los parámetros de una regresión logística generalmente se estiman mediante la estimación de máxima verosimilitud (MLE). Esto no tiene una expresión de forma cerrada, a diferencia de los mínimos cuadrados lineales; ver § Ajuste del modelo. La regresión logística por MLE juega un papel básico similar para las respuestas binarias o categóricas que la regresión lineal por mínimos cuadrados ordinarios (OLS) juega para las respuestas escalares: es un modelo de línea de base simple y bien analizado; ver § Comparación con regresión lineal para la discusión. La regresión logística como modelo estadístico general fue desarrollada y popularizada originalmente principalmente por Joseph Berkson, comenzando en Berkson (1944), donde acuñó "logit"; ver § Historia.
Aplicaciones
La regresión logística se usa en varios campos, incluido el aprendizaje automático, la mayoría de los campos médicos y las ciencias sociales. Por ejemplo, Boyd et al. usando regresión logística. Muchas otras escalas médicas utilizadas para evaluar la gravedad de un paciente se han desarrollado mediante regresión logística. La regresión logística se puede utilizar para predecir el riesgo de desarrollar una determinada enfermedad (p. ej., diabetes, cardiopatía coronaria), en función de las características observadas del paciente (edad, sexo, índice de masa corporal, resultados de varios análisis de sangre, etc.). Otro ejemplo podría ser predecir si un votante nepalés votará por el Congreso de Nepal o el Partido Comunista de Nepal o cualquier otro partido, según la edad, los ingresos, el sexo, la raza, el estado de residencia, los votos en elecciones anteriores, etc. La técnica también puede ser utilizado en ingeniería, especialmente para predecir la probabilidad de falla de un proceso, sistema o producto dado. También se utiliza en aplicaciones de marketing como la predicción de la propensión de un cliente a comprar un producto o suspender una suscripción, etc. En economía, se puede utilizar para predecir la probabilidad de que una persona termine en la fuerza laboral. y una aplicación comercial sería predecir la probabilidad de que un propietario de vivienda no cumpla con el pago de una hipoteca. Los campos aleatorios condicionales, una extensión de la regresión logística a los datos secuenciales, se utilizan en el procesamiento del lenguaje natural.
Ejemplo
Problema
Como ejemplo simple, podemos usar una regresión logística con una variable explicativa y dos categorías para responder la siguiente pregunta:
Un grupo de 20 estudiantes pasa entre 0 y 6 horas estudiando para un examen. ¿Cómo afecta el número de horas de estudio a la probabilidad de que el estudiante pase el examen?
La razón para usar la regresión logística para este problema es que los valores de la variable dependiente, aprobado y reprobado, mientras están representados por "1" y "0", no son números cardinales. Si el problema se cambió de modo que se reemplazó el aprobado/reprobado con el grado 0–100 (números cardinales), entonces se podría usar el análisis de regresión simple.
La tabla muestra la cantidad de horas que cada estudiante dedicó a estudiar y si aprobaron (1) o reprobaron (0).
| Horas (xk) | 0,50 | 0,75 | 1.00 | 1.25 | 1.50 | 1.75 | 1.75 | 2.00 | 2.25 | 2.50 | 2.75 | 3.00 | 3.25 | 3.50 | 4.00 | 4.25 | 4.50 | 4.75 | 5.00 | 5.50 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Paso (Sí.k) | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
Deseamos ajustar una función logística a los datos consistentes en las horas estudiadas (xk) y el resultado de la prueba (Sí.k=1 para pasar, 0 para fallar). Los puntos de datos son indexados por el subscript k que corre desde k=1{displaystyle k=1} a k=K=20{displaystyle k=K=20}. El x variable se llama "la variable explicativa", y la Sí. variable se llama la "variable categórica" compuesta de dos categorías: "pass" o "fail" correspondiente a los valores categóricos 1 y 0 respectivamente.


Modelo
La función logística es de la forma:
- p()x)=11+e− − ()x− − μ μ )/s{displaystyle p(x)={1}{1+e^{-(x-mu)/s}}}}

Donde μ es un parámetro de ubicación (el punto medio de la curva, donde p()μ μ )=1/2{displaystyle p(mu)=1/2}) y s es un parámetro de escala. Esta expresión puede ser reescrita como:

- p()x)=11+e− − ()β β 0+β β 1x){fnMicrosoft Sans Serif}}}}

Donde β β 0=− − μ μ /s{displaystyle beta ¿Qué? y se conoce como la interceptación (es el vertical interceptar o interceptar Sí.-intercepto de la línea Sí.=β β 0+β β 1x{displaystyle y=beta ¿Qué?), y β β 1=1/s{displaystyle beta ¿Qué? (parámetro de escala inversa o parámetro de tasa): estos son Sí.-intercepto y pendiente de los troncos como función x. Por el contrario, μ μ =− − β β 0/β β 1{displaystyle mu =-beta ¿Por qué? ¿Qué? y s=1/β β 1{displaystyle s=1/beta ¿Qué?.





Ajuste
La medida habitual de bondad de ajuste para una regresión logística utiliza pérdida logística (o pérdida de registro), la probabilidad de registro negativa. Para un dado xk y Sí.k, escribir pk=p()xk){displaystyle P_{k}=p(x_{k}}. El pk{displaystyle P_{k} son las probabilidades de que el correspondiente Sí.k{displaystyle y_{k} será unidad y 1− − pk{displaystyle 1-p_{k} son las probabilidades de que sean cero (ver distribución Bernoulli). Deseamos encontrar los valores de β β 0{displaystyle beta ¿Qué? y β β 1{displaystyle beta ¿Qué? que da el "mejor ajuste" a los datos. En el caso de regresión lineal, la suma de las desviaciones cuadradas del ajuste de los puntos de datos (Sí.k), la pérdida de error cuadrado, se toma como una medida de la bondad del ajuste, y el mejor ajuste se obtiene cuando esa función es minimizado.






La pérdida de registro para el k-ésimo punto es:
- {}− − In pksiSí.k=1,− − In ()1− − pk)siSí.k=0.{displaystyle {begin{cases}-ln p_{k} {text{ if }y_{k}=1,-ln(1-p_{k}) limitada{text{ if }y_{k}=0.end{cases}}}

La pérdida de registro se puede interpretar como el "surprisal" del resultado real Sí.k{displaystyle y_{k} relativa a la predicción pk{displaystyle P_{k}, y es una medida de contenido de información. Tenga en cuenta que la pérdida de registro es siempre mayor o igual a 0, igual a 0 sólo en caso de una predicción perfecta (es decir, cuando pk=1{displaystyle P_{k}=1} y Sí.k=1{displaystyle Y..., o pk=0{displaystyle P_{k}=0} y Sí.k=0{displaystyle y_{k}=0}), y se acerca el infinito mientras la predicción empeora (es decir, cuando Sí.k=1{displaystyle Y... y pk→ → 0{displaystyle p_{k}to 0} o Sí.k=0{displaystyle y_{k}=0} y pk→ → 1{displaystyle p_{k}to 1}), que significa que el resultado real es "más sorprendente". Dado que el valor de la función logística es siempre estrictamente entre cero y uno, la pérdida de registro es siempre mayor que cero y menos que el infinito. Tenga en cuenta que a diferencia de una regresión lineal, donde el modelo puede tener cero pérdida en un punto pasando por un punto de datos (y cero pérdida total si todos los puntos están en línea), en una regresión logística no es posible tener cero pérdida en ningún punto, ya que Sí.k{displaystyle y_{k} es 0 o 1, pero <math alttext="{displaystyle 0<p_{k}0.pk.1{displaystyle 0 realizadasp_{k}<img alt="{displaystyle 0<p_{k}.






Estos se pueden combinar en una sola expresión:
- − − Sí.kIn pk− − ()1− − Sí.k)In ()1− − pk).{displaystyle - Sí. p_{k}-(1-y_{k})ln(1-p_{k}).}

Esta expresión es más formalmente conocida como la entropía cruzada de la distribución predicha ()pk,()1− − pk)){displaystyle {big (}p_{k},(1-p_{k}{big)}} de la distribución efectiva ()Sí.k,()1− − Sí.k)){fnMicrosoft Sans Serif}, como distribuciones de probabilidad en el espacio de dos elementos de (pasar, fallar).


La suma de estos, la pérdida total, es la probabilidad de log negativo global − − l l {displaystyle -ell }, y el mejor ajuste se obtiene para las opciones de β β 0{displaystyle beta ¿Qué? y β β 1{displaystyle beta ¿Qué? para la cual − − l l {displaystyle -ell } es minimizado.

Alternativamente, en lugar de minimizar la pérdida, se puede maximizar su inversa, la probabilidad logarítmica (positiva):
- l l =.. k:Sí.k=1In ()pk)+.. k:Sí.k=0In ()1− − pk)=.. k=1K()Sí.kIn ()pk)+()1− − Sí.k)In ()1− − pk)){displaystyle ell =sum - Sí. - Sí. ¿Por qué?

o maximizar de manera equivalente la propia función de probabilidad, que es la probabilidad de que el conjunto de datos dado sea producido por una función logística particular:
- L=∏ ∏ k:Sí.k=1pk∏ ∏ k:Sí.k=0()1− − pk){displaystyle L=prod - Sí. - Sí.

Este método se conoce como estimación de máxima verosimilitud.
Estimación de parámetros
Desde l no lineal en β β 0{displaystyle beta ¿Qué? y β β 1{displaystyle beta ¿Qué?, determinar sus valores óptimos requerirá métodos numéricos. Tenga en cuenta que un método de maximizar l es exigir los derivados de l con respecto a β β 0{displaystyle beta ¿Qué? y β β 1{displaystyle beta ¿Qué? ser cero:
- 0=∂ ∂ l l ∂ ∂ β β 0=.. k=1K()Sí.k− − pk){displaystyle 0={frac {partial ell }{partial beta - Sí. ¿Qué?

- 0=∂ ∂ l l ∂ ∂ β β 1=.. k=1K()Sí.k− − pk)xk{displaystyle 0={frac {partial ell }{partial beta - Sí. ¿Por qué?

y el procedimiento de maximización se puede lograr mediante la resolución de las dos ecuaciones anteriores para β β 0{displaystyle beta ¿Qué? y β β 1{displaystyle beta ¿Qué?, que, de nuevo, requerirá generalmente el uso de métodos numéricos.
Los valores de β β 0{displaystyle beta ¿Qué? y β β 1{displaystyle beta ¿Qué? que maximizan l y L utilizando los datos anteriores se encuentran:
- β β 0.. − − 4.1{displaystyle beta _{0}approx -4.1}
- β β 1.. 1,5{displaystyle beta _{1}approx 1.5}


que arroja un valor para μ y s de:
- μ μ =− − β β 0/β β 1.. 2.7{displaystyle mu =-beta ¿Por qué? ¿Qué?
- s=1/β β 1.. 0,677{displaystyle s=1/beta ################################################################################################################################################################################################################################################################


Predicciones
El β β 0{displaystyle beta ¿Qué? y β β 1{displaystyle beta ¿Qué? Los coeficientes pueden entrar en la ecuación de regresión logística para estimar la probabilidad de pasar el examen.
Por ejemplo, para un estudiante que estudia 2 horas, ingresando el valor x=2{displaystyle x=2} en la ecuación da la probabilidad estimada de pasar el examen de 0.25:

- t=β β 0+2β β 1.. − − 4.1+2⋅ ⋅ 1,5=− − 1.1{displaystyle t=beta _{0}+2beta _{1}approx -4.1+2cdot 1.5=-1.1}

- p=11+e− − t.. 0,25=Probability of passing exam{displaystyle p={frac {1}{1+e^{-t}approx 0,25={text{Probability of passing exam}}}

Del mismo modo, para un alumno que estudia 4 horas, la probabilidad estimada de aprobar el examen es de 0,87:
- t=β β 0+4β β 1.. − − 4.1+4⋅ ⋅ 1,5=1.9{displaystyle t=beta _{0}+4beta _{1}approx -4.1+4cdot 1.5=1.9}

- p=11+e− − t.. 0.87=Probability of passing exam{displaystyle p={frac {1}{1+e^{-t}approx 0.87={text{Probability of passing exam}}}

Esta tabla muestra la probabilidad estimada de aprobar el examen para varios valores de horas de estudio.
| Horas de estudio x) | Examen de paso | ||
|---|---|---|---|
| Saldos lógicos t) | Odds (et) | Probability (p) | |
| 1 | −2.57 | 0,076 Entendido 1:13.1 | 0,07 |
| 2 | −1.07 | 0,34 Ø 1:2,91 | 0,266 |
| μ μ .. 2.7{displaystyle mu approx 2.7} | 0 | 1 | 12{fnMicroc} {1}{2}}} = 0,50 |
| 3 | 0.44 | 1.55 | 0.61 |
| 4 | 1.94 | 6.96 | 0.87 |
| 5 | 3.45 | 31.4 | 0.97 |


Evaluación del modelo
El análisis de regresión logística da el siguiente resultado.
| Coeficiente | Std. Error | z- valor | p-valor (Wald) | |
|---|---|---|---|---|
| Interceptoβ0) | −4.1 | 1.8 | −2.3 | 0,021 |
| Horas (β1) | 1,5 | 0.6 | 2.4 | 0,017 |
En la prueba Wald, la salida indica que las horas de estudio están asociadas significativamente con la probabilidad de pasar el examen (en inglés)p=0,017{displaystyle p=0.017}). En lugar del método Wald, el método recomendado para calcular el p-valor para la regresión logística es la prueba de probabilidad- ratio (LRT), que para estos datos dan p.. 0,00064{displaystyle papprox 0,00064} (ver § Deviance and likelihood ratio tests below).


Generalizaciones
Este modelo simple es un ejemplo de regresión logística binaria y tiene una variable explicativa y una variable categórica binaria que puede asumir uno de dos valores categóricos. La regresión logística multinomial es la generalización de la regresión logística binaria para incluir cualquier número de variables explicativas y cualquier número de categorías.
Antecedentes




Definición de la función logística
Una explicación de la regresión logística puede comenzar con una explicación de la función logística estándar. La función logística es una función sigmoide, que toma cualquier entrada real t{displaystyle t}, y produce un valor entre cero y uno. Para el logit, esto se interpreta como la toma de los log-odds de entrada y la probabilidad de salida. El estándar función logística σ σ :R→ → ()0,1){displaystyle sigma:mathbb {R} rightarrow (0,1)} se define como sigue:

- σ σ ()t)=etet+1=11+e− − t{displaystyle sigma (t)={frac {} {fn} {fn}} {fnMicroc} {1}{1+e^{-t}}

En la Figura 1 se muestra un gráfico de la función logística en el intervalo t (−6,6).
Supongamos que t{displaystyle t} es una función lineal de una sola variable explicativa x{displaystyle x} (el caso donde t{displaystyle t} es un combinación lineal de múltiples variables explicativas se trata de manera similar). Entonces podemos expresar t{displaystyle t} como sigue:

- t=β β 0+β β 1x{displaystyle t=beta ¿Qué?

Y la función logística general p:R→ → ()0,1){displaystyle p:mathbb {R} rightarrow (0,1)} puede ser escrito como:

- p()x)=σ σ ()t)=11+e− − ()β β 0+β β 1x){displaystyle p(x)=sigma (t)={frac {1}{1+e^{-(beta _{0}+beta _{1}x)}}}}

En el modelo logístico, p()x){displaystyle p(x)} se interpreta como la probabilidad de la variable dependiente Y{displaystyle Sí. igualar un éxito/caso en lugar de un fracaso/no caso. Está claro que las variables de respuesta Yi{displaystyle Y... no se distribuyen de forma idéntica: P()Yi=1▪ ▪ X){displaystyle P(Y_{i}=1mid X)} difiere de un punto de datos Xi{displaystyle X_{i} a otro, aunque son independientes dada matriz de diseño X{displaystyle X} y parámetros compartidos β β {displaystyle beta }.







Definición de la inversa de la función logística
Ahora podemos definir la función logit (arriba) como el inverso g=σ σ − − 1{displaystyle g=sigma } de la función logística estándar. Es fácil ver que satisface:

- g()p()x))=σ σ − − 1()p()x))=logit p()x)=In ()p()x)1− − p()x))=β β 0+β β 1x,{displaystyle g(p(x)=sigma ^{-1}(p(x)=operatorname {logit} p(x)=ln left({frac {p(x)}{1-p(x)}right)=beta ¿Qué?

y de manera equivalente, después de exponenciar ambos lados tenemos las probabilidades:
- p()x)1− − p()x)=eβ β 0+β β 1x.{displaystyle {frac {p(x)}{1-p(x)}=e^{beta ¿Qué? - Sí.

Interpretación de estos términos
En las ecuaciones anteriores, los términos son los siguientes:
- g{displaystyle g} es la función logit. La ecuación para g()p()x)){displaystyle g(p(x)} ilustra que el logit (es decir, log-odds o logaritmo natural de las probabilidades) es equivalente a la expresión de regresión lineal.
- In{displaystyle ln } denota el logaritmo natural.
- p()x){displaystyle p(x)} es la probabilidad de que la variable dependiente sea igual a un caso, dada alguna combinación lineal de los predictores. La fórmula para p()x){displaystyle p(x)} ilustra que la probabilidad de la variable dependiente igualar un caso es igual al valor de la función logística de la expresión de regresión lineal. Esto es importante porque muestra que el valor de la expresión de regresión lineal puede variar de la infinidad negativa a positiva y, sin embargo, después de la transformación, la expresión resultante de la probabilidad p()x){displaystyle p(x)} rangos entre 0 y 1.
- β β 0{displaystyle beta ¿Qué? es la interceptación de la ecuación de regresión lineal (el valor del criterio cuando el predictor es igual a cero).
- β β 1x{displaystyle beta _{1}x} es el coeficiente de regresión multiplicado por algún valor del predictor.
- base e{displaystyle e} denota la función exponencial.





Definición de las cuotas
Las probabilidades de que la variable dependiente sea igual a un caso (debido a alguna combinación lineal x{displaystyle x} de los predictores) es equivalente a la función exponencial de la expresión de regresión lineal. Esto ilustra cómo el logit sirve como una función de enlace entre la probabilidad y la expresión de regresión lineal. Dado que el logit varía entre la infinidad negativa y positiva, proporciona un criterio adecuado sobre el cual llevar a cabo la regresión lineal y el logit se convierte fácilmente en las probabilidades.
Así que definimos las probabilidades de la variable dependiente igualando un caso (debido a alguna combinación lineal x{displaystyle x} de los predictores) como sigue:
- probabilidades=eβ β 0+β β 1x.{displaystyle {text{odds}=e^{beta ¿Qué? - Sí.

La razón de probabilidades
Para una variable independiente continua, la razón de probabilidades se puede definir como:
- OR=probabilidades ()x+1)probabilidades ()x)=()p()x+1)1− − p()x+1))()p()x)1− − p()x))=eβ β 0+β β 1()x+1)eβ β 0+β β 1x=eβ β 1{fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicroc {fnMicroc {fnMicroc} {fnMicroc} {fnMicroc} {fnMicroc} {c}}} {c} {f}}}} {f}}}}}} {f}}}}}} {f} {f} {f}} {f}f}}}}}}}}}}}f}}}}}}}}}}}}}}}} {f} {f}f} {f}}}} {f}f}} {f}} {f}f} {f}} {f}}}}}}}f}}}}f}f}}f}}}}}}}}}} ¿Por qué? ¿Qué? ¿Qué? ¿Qué?
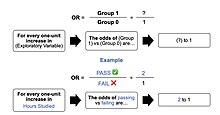 La imagen representa un esbozo de lo que una relación de probabilidades parece por escrito, a través de una plantilla además del ejemplo de puntuación de la prueba en la sección "Ejemplo" del contenido. En términos simples, si hipotéticamente obtenemos una relación de probabilidades de 2 a 1, podemos decir... "Para cada aumento de una unidad en las horas estudiadas, las probabilidades de pasar (grupo 1) o fallar (grupo 0) son (esperadamente) 2 a 1 (Denis, 2019).
La imagen representa un esbozo de lo que una relación de probabilidades parece por escrito, a través de una plantilla además del ejemplo de puntuación de la prueba en la sección "Ejemplo" del contenido. En términos simples, si hipotéticamente obtenemos una relación de probabilidades de 2 a 1, podemos decir... "Para cada aumento de una unidad en las horas estudiadas, las probabilidades de pasar (grupo 1) o fallar (grupo 0) son (esperadamente) 2 a 1 (Denis, 2019).


Esta relación exponencial proporciona una interpretación β β 1{displaystyle beta ¿Qué?: Las probabilidades se multiplican por eβ β 1{displaystyle e^{beta ¿Qué? por cada aumento de 1 unidad en x.

Para una variable binaria independiente la relación de probabilidades se define como adbc{displaystyle {frac {}{bc}} Donde a, b, c y d son células en una tabla de contingencia 2×2.

Múltiples variables explicativas
Si hay múltiples variables explicativas, la expresión anterior β β 0+β β 1x{displaystyle beta ¿Qué? puede ser revisado β β 0+β β 1x1+β β 2x2+⋯ ⋯ +β β mxm=β β 0+.. i=1mβ β ixi{displaystyle beta ¿Qué? ##{1}x_{1}+beta _{2}x_{2}+cdots +beta # {m}x_{m}=beta ¿Qué? ##{i=1} {m}beta ¿Qué?. Entonces cuando esto se utiliza en la ecuación relativa a las probabilidades de un éxito de los valores de los predictores, la regresión lineal será una regresión múltiple con m explanadores; los parámetros β β j{displaystyle beta _{j}} para todos j=0,1,2,...... ,m{displaystyle j=0,1,2,dotsm} se estiman todos.




Nuevamente, las ecuaciones más tradicionales son:
- log p1− − p=β β 0+β β 1x1+β β 2x2+⋯ ⋯ +β β mxm{displaystyle log {frac {p}{1-p}=beta ¿Qué? ##{1}x_{1}+beta # {2}x_{2}+cdots +beta ¿Qué?

y
- p=11+b− − ()β β 0+β β 1x1+β β 2x2+⋯ ⋯ +β β mxm){displaystyle p={frac {1}{1+b^{-(beta ¿Qué? ##{1}x_{1}+beta _{2}x_{2}+cdots +beta ♪♪

donde generalmente b=e{displaystyle b=e}.

Definición
La configuración básica de la regresión logística es la siguiente. Nos dan un conjunto de datos que contiene N puntos. Cada punto i consta de un conjunto de variables de entrada m x1,i... xm,i (también llamadas variables independientes, variables explicativas, variables predictoras, características o atributos), y un resultado binario variable Yi (también conocida como variable dependiente, variable de respuesta, variable de salida o clase), es decir, puede asumir solo las dos posibles valores 0 (a menudo significa 'no' o 'fracaso') o 1 (a menudo significa 'sí' o 'éxito'). El objetivo de la regresión logística es utilizar el conjunto de datos para crear un modelo predictivo de la variable de resultado.
Al igual que en la regresión lineal, se supone que las variables de resultado Yi dependen de las variables explicativas x 1,i... xm,i.
- Variables explicativas
Las variables explicativas pueden ser de cualquier tipo: reales, binarias, categóricas, etc. La distinción principal es entre variables continuas y variables discretas.
(Las variables discretas que se refieren a más de dos opciones posibles generalmente se codifican usando variables ficticias (o variables indicadoras), es decir, se crean variables explicativas separadas que toman el valor 0 o 1 para cada valor posible de la variable discreta, con un 1 significa "variable tiene el valor dado" y 0 significa "variable no tiene ese valor").
- Variables de resultados
Formalmente, los resultados Yi se describen como datos distribuidos por Bernoulli, donde cada resultado está determinado por una probabilidad no observada pi que es específico del resultado en cuestión, pero relacionado con las variables explicativas. Esto puede expresarse en cualquiera de las siguientes formas equivalentes:
- Yi▪ ▪ x1,i,...... ,xm,i♪ ♪ Bernoulli ()pi)E [Yi▪ ▪ x1,i,...... ,xm,i]=piPr()Yi=Sí.▪ ▪ x1,i,...... ,xm,i)={}pisiSí.=11− − pisiSí.=0Pr()Yi=Sí.▪ ▪ x1,i,...... ,xm,i)=piSí.()1− − pi)()1− − Sí.){displaystyle {begin{aligned}Y_{i}mid x_{1,i},ldotsx_{m, i} &sim operatorname {Bernoulli} (p_{i})\fnMithbb {f} [Y_{i}mid x_{1,i},ldotsx_{m,i}] x_{1,i},ldotsx_{m,i}) correspond={begin{cases}p_{i} limit{if{if - Sí. {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif}} {f}}}}f}}}}}f}}}}}}fnMientras me lo siento que no lo siento mucho.
![{displaystyle {begin{aligned}Y_{i}mid x_{1,i},ldotsx_{m,i} &sim operatorname {Bernoulli} (p_{i})\operatorname {mathbb {E} } [Y_{i}mid x_{1,i},ldotsx_{m,i}]&=p_{i}\Pr(Y_{i}=ymid x_{1,i},ldotsx_{m,i})&={begin{cases}p_{i}&{text{if }}y=1\1-p_{i}&{text{if }}y=0end{cases}}\Pr(Y_{i}=ymid x_{1,i},ldotsx_{m,i})&=p_{i}^{y}(1-p_{i})^{(1-y)}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/49627157ac00e729a38538029505c210f99955d7)
Los significados de estas cuatro líneas son:
- La primera línea expresa la distribución de probabilidad de cada Yi: condicionado a las variables explicativas, sigue una distribución de Bernoulli con parámetros pi, la probabilidad del resultado de 1 para el juicio i. Como se señaló anteriormente, cada ensayo separado tiene su propia probabilidad de éxito, al igual que cada ensayo tiene sus propias variables explicativas. La probabilidad del éxito pi no se observa, sólo el resultado de un juicio individual Bernoulli utilizando esa probabilidad.
- La segunda línea expresa el hecho de que el valor esperado de cada Yi es igual a la probabilidad de éxito pi, que es una propiedad general de la distribución Bernoulli. En otras palabras, si ejecutamos un gran número de ensayos de Bernoulli utilizando la misma probabilidad de éxito pi, entonces tomar el promedio de todos los resultados 1 y 0, entonces el resultado sería cercano pi. Esto se debe a que hacer un promedio de esta manera simplemente calcula la proporción de éxitos vistos, que esperamos converger a la probabilidad subyacente del éxito.
- La tercera línea escribe la función de masa de probabilidad de la distribución Bernoulli, especificando la probabilidad de ver cada uno de los dos posibles resultados.
- La cuarta línea es otra forma de escribir la función de masa de probabilidad, que evita tener que escribir casos separados y es más conveniente para ciertos tipos de cálculos. Esto se basa en el hecho de que Yi puede tomar sólo el valor 0 o 1. En cada caso, uno de los exponentes será 1, "elegir" el valor debajo de él, mientras que el otro es 0, "canceling out" el valor debajo de él. Por lo tanto, el resultado es o pi o 1 −piComo en la línea anterior.
- Función del predictor lineal
La idea básica de regresión logística es utilizar el mecanismo ya desarrollado para la regresión lineal modelando la probabilidad pi usando una función de predictor lineal, es decir, una combinación lineal de las variables explicativas y un conjunto de coeficientes de regresión que son específicos al modelo a mano pero lo mismo para todos los ensayos. Función del predictor lineal f()i){displaystyle f(i)} para un punto de datos particular i está escrito como:

- f()i)=β β 0+β β 1x1,i+⋯ ⋯ +β β mxm,i,{displaystyle f(i)=beta ¿Qué? ##{1}x_{1,i}+cdots +beta ¿Qué?

Donde β β 0,...... ,β β m{displaystyle beta _{0},ldotsbeta ¿Qué? son coeficientes de regresión que indican el efecto relativo de una variable explicativa particular en el resultado.

El modelo generalmente se pone en una forma más compacta de la siguiente manera:
- Los coeficientes de regresión β0, β1,... βm se agrupan en un solo vector β de tamaño m+ 1.
- Para cada punto de datos i, un pseudovariable explicativo adicional x0,i se añade, con un valor fijo de 1, correspondiente al coeficiente de interceptación β0.
- Las variables explicativas resultantes x0,i, x1,i,... xm,i se agrupan en un solo vector Xi de tamaño m+ 1.
Esto hace posible escribir la función predictora lineal de la siguiente manera:
- f()i)=β β ⋅ ⋅ Xi,{beta}cdot mathbf {X} _{i},}

utilizando la notación para un producto escalar entre dos vectores.

Muchas variables explicativas, dos categorías
El ejemplo anterior de regresión logística binaria en una variable explicativa puede generalizarse a la regresión logística binaria en cualquier número de variables explicativas x1, x2,... y cualquier número de valores categóricos Sí.=0,1,2,...... {displaystyle y=0,1,2,dots }.

Para empezar, podemos considerar un modelo logístico con M variables explicativas, x1, x2... xM y, como en el ejemplo anterior, dos valores categóricos (Sí. = 0 y 1). Para el modelo simple de regresión logística binaria, asumimos una relación lineal entre la variable predictor y los log-odds (también llamado logit) del evento que Sí.=1{displaystyle y=1}. Esta relación lineal puede extenderse al caso de M variables explicativas:

- t=logb p1− − p=β β 0+β β 1x1+β β 2x2+⋯ ⋯ +β β MxM{displaystyle t=log _{b}{frac} {p}{1-p}=beta ¿Qué? ##{1}x_{1}+beta _{2}x_{2}+cdots +beta ¿Qué?

Donde t es el log-odds y β β i{displaystyle beta _{i} son parámetros del modelo. Se ha introducido una generalización adicional en la que se basa el modelo (b) no está restringido al número de Euler e. En la mayoría de las aplicaciones, la base b{displaystyle b} del logaritmo generalmente se toma para ser e. Sin embargo, en algunos casos puede ser más fácil comunicar los resultados trabajando en base 2 o base 10.


Para una notación más compacta, especificaremos las variables explicativas y las β coeficientes como ()M+1){displaystyle (M+1)}- vectores dimensionales:

- x={}x0,x1,x2,...... ,xM}{displaystyle {boldsymbol {x}={x_{0},x_{1},x_{2},dotsx_{M}}}
- β β ={}β β 0,β β 1,β β 2,...... ,β β M}{displaystyle {boldsymbol {beta }={beta _{0},beta _{1},beta _{2},dotsbeta ¿Qué?


con una variable explicativa agregada x0 =1. El logit ahora se puede escribir como:
- t=.. m=0Mβ β mxm=β β ⋅ ⋅ x{displaystyle t=sum ### {m=0} {M}beta ## {m}x_{m}={boldsymbol {beta}cdot x}

Solving for the probability p que Sí.=1{displaystyle y=1} rendimientos:
- p()x)=bβ β ⋅ ⋅ x1+bβ β ⋅ ⋅ x=11+b− − β β ⋅ ⋅ x=Sb()t){displaystyle p({boldsymbol {x})={frac {b^{boldsymbol {beta}cdot {betam} {x}}{1+b^{boldsymbol {beta}cdot {betam} {x}}={frac} {1}{1+b^{-{boldsymbol {beta}cdot {betam} {x}}=S_{b}(t)},

Donde Sb{displaystyle S_{b} es la función sigmoide con base b{displaystyle b}. La fórmula anterior muestra que una vez β β m{displaystyle beta ¿Qué? se fijan, podemos calcular fácilmente los log-odds que Sí.=1{displaystyle y=1} para una observación determinada, o la probabilidad de que Sí.=1{displaystyle y=1} para una observación dada. El principal caso de uso de un modelo logístico se debe dar una observación x{displaystyle {boldsymbol {x}}, y estimar la probabilidad p()x){displaystyle p({boldsymbol {x})} que Sí.=1{displaystyle y=1}. Los coeficientes beta óptimos se pueden encontrar de nuevo al maximizar la probabilidad de registro. Para K medidas, definición xk{displaystyle {boldsymbol {x}_{k} como vector explicativo del k- mide y Sí.k{displaystyle y_{k} como resultado categórico de esa medición, la probabilidad de registro puede ser escrita en una forma muy similar a la simple M=1{displaystyle M=1} caso anterior:






- l l =.. k=1KSí.klogb ()p()xk))+.. k=1K()1− − Sí.k)logb ()1− − p()xk)){displaystyle ell =sum ¿Por qué? ¿Por qué?

Como en el ejemplo simple anterior, encontrar los parámetros β óptimos requerirá métodos numéricos. Una técnica útil es igualar las derivadas de la verosimilitud logarítmica con respecto a cada uno de los parámetros β a cero, lo que produce un conjunto de ecuaciones que se mantendrán en el máximo de la verosimilitud logarítmica:
- ∂ ∂ l l ∂ ∂ β β m=0=.. k=1KSí.kxmk− − .. k=1Kp()xk)xmk{displaystyle {frac {partial ell }{partial beta ¿Qué? ¿Qué? ¿Qué? {x}_{k})x_{mk}

donde xmk es el valor de la variable explicativa xm de k- th medida.
Considerar un ejemplo con M=2{displaystyle M=2} variables explicativas, b=10{displaystyle b=10}, y coeficientes β β 0=− − 3{displaystyle beta ¿Qué?, β β 1=1{displaystyle beta ¿Qué?, y β β 2=2{displaystyle beta ¿Qué? que han sido determinados por el método anterior. Para ser concreto, el modelo es:





- t=log10 p1− − p=− − 3+x1+2x2{displaystyle t=log _{10}{frac {p}{1-p}=-3+x_{1}+2x_{2}
- p=bβ β ⋅ ⋅ x1+bβ β ⋅ ⋅ x=bβ β 0+β β 1x1+β β 2x21+bβ β 0+β β 1x1+β β 2x2=11+b− − ()β β 0+β β 1x1+β β 2x2){displaystyle p={bik {\fnh00\fnh00\fnh00} {beta}cdot {betam} {x}}{1+b^{boldsymbol {beta}cdot {fnK}}={beta {fnK}}}= {fnMicroc {b} {beta {f}}}}}}} {f}}}}} {fnK}}} {fnf}}}}} {fnf}}fnfnKf}}}}}}}}} {f}f}f}f}f}f}f}fnfnf}f}f}f}fnf}fnfnfnfnfnfnf}fnfnfnfnfnKfnKfnKfnfnfnKfnfnfnfnKfnfnfnKfnKfnfnfnfnfnfnKfnKfnfn ¿Qué? ##{1}x_{1}+beta {2}x_{2}}{1+b^{beta ¿Qué? ##{1}x_{1}+beta - ¿Qué? {1}{1+b^{-(beta ¿Qué? ##{1}x_{1}+beta - Sí.,


Donde p es la probabilidad del evento que Sí.=1{displaystyle y=1}. Esto puede interpretarse como sigue:
- β β 0=− − 3{displaystyle beta ¿Qué? es el intercepto y. Es el log-odds del evento que Sí.=1{displaystyle y=1}, cuando los predictores x1=x2=0{displaystyle x_{1}=x_{2}=0}. Al exponente, podemos ver eso cuando x1=x2=0{displaystyle x_{1}=x_{2}=0} las probabilidades del evento que Sí.=1{displaystyle y=1} 1-a-1000, o 10− − 3{displaystyle 10^{-3}. Del mismo modo, la probabilidad del evento que Sí.=1{displaystyle y=1} cuando x1=x2=0{displaystyle x_{1}=x_{2}=0} puede ser calculado como 1/()1000+1)=1/1001.{displaystyle 1/(1000+1)=1/1001.}
- β β 1=1{displaystyle beta ¿Qué? significa que aumentar x1{displaystyle x_{1}} por 1 aumenta los log-odds por 1{displaystyle 1}. Así que si x1{displaystyle x_{1}} aumenta en 1, las probabilidades que Sí.=1{displaystyle y=1} aumento por factor de 101{displaystyle 10^{1}. Note que probabilidad de Sí.=1{displaystyle y=1} también ha aumentado, pero no ha aumentado tanto como las probabilidades han aumentado.
- β β 2=2{displaystyle beta ¿Qué? significa que aumentar x2{displaystyle x_{2} por 1 aumenta los log-odds por 2{displaystyle 2}. Así que si x2{displaystyle x_{2} aumenta en 1, las probabilidades que Sí.=1{displaystyle y=1} aumento por factor de 102.{displaystyle 10^{2} Observe cómo el efecto x2{displaystyle x_{2} en los log-odds es dos veces más grande que el efecto de x1{displaystyle x_{1}}, pero el efecto en las probabilidades es 10 veces mayor. Pero el efecto sobre el probabilidad de Sí.=1{displaystyle y=1} no es tanto como 10 veces mayor, es sólo el efecto en las probabilidades que es 10 veces mayor.









Regresión logística multinomial: muchas variables explicativas y muchas categorías
En los casos anteriores de dos categorías (regreso logístico bilateral), las categorías fueron indexadas por "0" y "1", y tuvimos dos distribuciones de probabilidad: La probabilidad de que el resultado se produzca en la categoría 1 fue dada por p()x){displaystyle p({boldsymbol {x})}y la probabilidad de que el resultado fuera en la categoría 0 fue dada por 1− − p()x){displaystyle 1-p({boldsymbol {x}}}. La suma de ambas probabilidades es igual a la unidad, como deben ser.

En general, si tenemos M+1{displaystyle M+1} variables explicativas (incluidas x0) y N+1{displaystyle N+1} categorías, necesitaremos N+1{displaystyle N+1} distribuciones de probabilidad separadas, una para cada categoría, indexada por n, que describen la probabilidad de que el resultado categórico Sí. para vector explicativo x estará en la categoría Y.... También será necesario que la suma de estas probabilidades sobre todas las categorías sea igual a la unidad. Usando la base matemáticamente conveniente e, estas probabilidades son:


- pn()x)=eβ β n⋅ ⋅ x1+.. u=1Neβ β u⋅ ⋅ x{displaystyle p_{n}({boldsymbol {x})={frac {e^{boldsymbol {beta }_{n}cdot {boldsymbol {x}}{1+sum ¿Qué? {beta ♪♪♪♪♪ {}}}} para n=1,2,...... ,N{displaystyle n=1,2,dotsN}
- p0()x)=1− − .. n=1Npn()x)=11+.. u=1Neβ β u⋅ ⋅ x{displaystyle p_{0}({boldsymbol {x})=1-sum ¿Qué? {1}{1+sum ¿Qué? {beta ♪♪♪♪♪ {}}}}



Cada una de las probabilidades excepto p0()x){displaystyle p_{0}({boldsymbol {x})} tendrá su propio conjunto de coeficientes de regresión β β n{displaystyle {boldsymbol {beta ♪♪. Se puede ver que, según sea necesario, la suma de la pn()x){displaystyle p_{n}({boldsymbol {x})} sobre todas las categorías es la unidad. Note que la selección de p0()x){displaystyle p_{0}({boldsymbol {x})} ser definido en términos de las otras probabilidades es artificial. Cualquiera de las probabilidades podría haber sido seleccionada para ser tan definida. Este valor especial n se denomina el "índice de pivote", y los log-odds (tn) se expresan en términos de la probabilidad pivote y se expresan nuevamente como una combinación lineal de las variables explicativas:



- tn=In ()pn()x)p0()x))=β β n⋅ ⋅ x{fn} {fn} {fnfn} {fn} {fn} {fn}}} {p_{0} {fnfn}}}}} {fnfnfnfn}}}= {fnfnfn}}}}}}}sigual]= {ppppp}}}}}}}}}}}}}}pppppppppp]=pppppppppppppppppppp]=ppppppppppppppppppppnhnhnhnhnhnhnhnhnhnhnhnhnhnhnhnhn }_ {n}cdot {fn} {fn}

Note también que para el caso simple de N=1{displaystyle N=1}, el caso de dos categorías se recupera, con p()x)=p1()x){displaystyle p({boldsymbol {x})=p_{1}({boldsymbol {x}}} y p0()x)=1− − p1()x){fnMicrosoft Sans Serif}=1-p_{1}({boldsymbol {x})}.



La probabilidad de que un conjunto particular de K mediciones o puntos de datos serán generados por las probabilidades anteriores ahora se puede calcular. Indización de cada medición por k, deja que k- el conjunto de variables explicativas medidas se denotan por xk{displaystyle {boldsymbol {x}_{k} y sus resultados categóricos se denotan Sí.k{displaystyle y_{k} que puede ser igual a cualquier entero en [0,N]. La probabilidad de registro es entonces:
- l l =.. k=1K.. n=0NΔ Δ ()n,Sí.k)In ()pn()xk)){displaystyle ell =sum ¿Qué? ¿Por qué?

Donde Δ Δ ()n,Sí.k){displaystyle Delta (n,y_{k}} es una función indicadora igual a la unidad si Sí.k = n y cero de otro modo. En el caso de dos variables explicativas, esta función indicadora se definió como Sí.k cuando n = 1 y 1-yk cuando n = 0. Esto era conveniente, pero no necesario. De nuevo, los coeficientes beta óptimos se pueden encontrar maximizando la función de probabilidad de registro generalmente utilizando métodos numéricos. Un posible método de solución es establecer los derivados de la probabilidad log con respecto a cada coeficiente beta igual a cero y resolver para los coeficientes beta:

- ∂ ∂ l l ∂ ∂ β β nm=0=.. k=1KΔ Δ ()n,Sí.k)xmk− − .. k=1Kpn()xk)xmk{displaystyle {frac {partial ell }{partial beta ¿Qué? Delta (n,y)x_{mk}-sum ¿Qué? {x}_{k})x_{mk}

Donde β β nm{displaystyle beta _{nm} es m- el coeficiente del β β n{displaystyle {boldsymbol {beta ♪♪ vectores y xmk{displaystyle x_{mk} es m-la variable explicativa de la k- mide. Una vez que se hayan estimado los coeficientes beta de los datos, podremos estimar la probabilidad de que cualquier conjunto posterior de variables explicativas resulte en cualquiera de las posibles categorías de resultados.


Interpretaciones
Existen varias especificaciones e interpretaciones equivalentes de la regresión logística, que encajan en diferentes tipos de modelos más generales y permiten diferentes generalizaciones.
Como modelo lineal generalizado
El modelo particular utilizado por la regresión logística, que la distingue de la regresión lineal estándar y de otros tipos de análisis de regresión utilizados para resultados con valores binarios, es la forma en que la probabilidad de un resultado particular se vincula con la función predictora lineal:
- logit ()E [Yi▪ ▪ x1,i,...... ,xm,i])=logit ()pi)=In ()pi1− − pi)=β β 0+β β 1x1,i+⋯ ⋯ +β β mxm,i{displaystyle operatorname {logit} (operatorname {mathbb {E} [Y_{i}mid x_{1,i},ldotsx_{m,i})=operatorname {logit} (p_{i})=ln left({frac] {p_{i}{1-p_{i}}right)=beta ¿Qué? ##{1}x_{1,i}+cdots +beta ¿Qué?
![{displaystyle operatorname {logit} (operatorname {mathbb {E} } [Y_{i}mid x_{1,i},ldotsx_{m,i}])=operatorname {logit} (p_{i})=ln left({frac {p_{i}}{1-p_{i}}}right)=beta _{0}+beta _{1}x_{1,i}+cdots +beta _{m}x_{m,i}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be13d1b675b8fb6e9db4835cd151b5fc9076e282)
Escrito usando la notación más compacta descrita arriba, esto es:
- logit ()E [Yi▪ ▪ Xi])=logit ()pi)=In ()pi1− − pi)=β β ⋅ ⋅ Xi{displaystyle operatorname {logit} (operatorname {mathbb {E} {X} _{i})=fnfnfnfnfnfnfnfnfnfn}=fncfnfnfnfnfnfnfnfnfnfnfnfnfnh00} {fnK}{1-p_{i}}right)={boldsymbol {beta}cdot mathbf {X}
![{displaystyle operatorname {logit} (operatorname {mathbb {E} } [Y_{i}mid mathbf {X} _{i}])=operatorname {logit} (p_{i})=ln left({frac {p_{i}}{1-p_{i}}}right)={boldsymbol {beta }}cdot mathbf {X} _{i}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/55adb25231d3cea8f63c4fe56a8677f6eb59415f)
Esta formulación expresa la regresión logística como un tipo de modelo lineal generalizado, que predice variables con varios tipos de distribuciones de probabilidad ajustando una función predictora lineal de la forma anterior a algún tipo de transformación arbitraria del valor esperado de la variable.
La intuición para la transformación mediante la función logit (el registro natural de las probabilidades) se explicó anteriormente. También tiene el efecto práctico de convertir la probabilidad (que está ligada a ser entre 0 y 1) a una variable que va más allá ()− − JUEGO JUEGO ,+JUEGO JUEGO ){displaystyle (-infty+infty)} — equiparando así el rango potencial de la función de predicción lineal en el lado derecho de la ecuación.

Tenga en cuenta que tanto las probabilidades pi como los coeficientes de regresión no se observan, y los medios para determinarlos no forman parte del modelo sí mismo. Por lo general, se determinan mediante algún tipo de procedimiento de optimización, p. estimación de máxima verosimilitud, que encuentra los valores que mejor se ajustan a los datos observados (es decir, que dan las predicciones más precisas para los datos ya observados), generalmente sujeta a condiciones de regularización que buscan excluir valores poco probables, p. valores extremadamente grandes para cualquiera de los coeficientes de regresión. El uso de una condición de regularización es equivalente a hacer una estimación máxima a posteriori (MAP), una extensión de la máxima verosimilitud. (La regularización se realiza más comúnmente utilizando una función de regularización al cuadrado, que es equivalente a colocar una distribución previa gaussiana de media cero en los coeficientes, pero también son posibles otros regularizadores). Se use o no la regularización, por lo general no es posible encontrar una solución de forma cerrada; en su lugar, se debe utilizar un método numérico iterativo, como mínimos cuadrados reponderados iterativamente (IRLS) o, más comúnmente en estos días, un método cuasi-Newton como el método L-BFGS.
La interpretación de la βj Estimaciones del parámetro es como el efecto aditivo en el registro de las probabilidades para un cambio de unidad en el j la variable explicativa. En el caso de una variable explicativa dicotómica, por ejemplo, género eβ β {displaystyle e^{beta } es la estimación de las probabilidades de tener el resultado para, por ejemplo, hombres en comparación con las mujeres.

Una fórmula equivalente utiliza la inversa de la función logit, que es la función logística, es decir:
- E [Yi▪ ▪ Xi]=pi=logit− − 1 ()β β ⋅ ⋅ Xi)=11+e− − β β ⋅ ⋅ Xi{displaystyle operatorname {Mathbb {E} {X}_{i}=p_{i}=operatorname {logit} {{-1}({boldsym {bolbeta}cdot mathbf {X} _{i}={frac {1}{1+e^{-{boldsymbol {beta}cdot mathbf {X}
![{displaystyle operatorname {mathbb {E} } [Y_{i}mid mathbf {X} _{i}]=p_{i}=operatorname {logit} ^{-1}({boldsymbol {beta }}cdot mathbf {X} _{i})={frac {1}{1+e^{-{boldsymbol {beta }}cdot mathbf {X} _{i}}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/337230f2ea410541cdcf94442ce37b92515dd364)
La fórmula también se puede escribir como una distribución de probabilidad (específicamente, usando una función de masa de probabilidad):
- Pr()Yi=Sí.▪ ▪ Xi)=piSí.()1− − pi)1− − Sí.=()eβ β ⋅ ⋅ Xi1+eβ β ⋅ ⋅ Xi)Sí.()1− − eβ β ⋅ ⋅ Xi1+eβ β ⋅ ⋅ Xi)1− − Sí.=eβ β ⋅ ⋅ Xi⋅ ⋅ Sí.1+eβ β ⋅ ⋅ Xi{displaystyle Pr(Y_{i}=ymid mathbf {X} _{i}={p_{i}}{y} {y}(1-p_{i})}{1-y}=left({frac_=frac} {i} {fncipal} {beta}cdot mathbf {X} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {beta}cdot mathbf Está bien. {beta}cdot mathbf {X} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {beta}cdot mathbf {X} {fn}}}derecha)} {fnMicroc} {fncipal} {beta}cdot mathbf {X} # {1+e^{boldsymbol {beta}cdot mathbf {X}

Como modelo de variable latente
El modelo logístico tiene una formulación equivalente a un modelo de variable latente. Esta formulación es común en la teoría de los modelos de elección discreta y facilita la extensión a ciertos modelos más complicados con múltiples opciones correlacionadas, así como la comparación de la regresión logística con el modelo probit estrechamente relacionado.
Imagínese que, para cada prueba i, hay una variable latente continua Yi * (es decir, una variable aleatoria no observada) que se distribuye de la siguiente manera:
- YiAlternativa Alternativa =β β ⋅ ⋅ Xi+ε ε i{displaystyle Y... [X] _{i}+varepsilon ¿Qué?

dónde
- ε ε i♪ ♪ Logística ()0,1){displaystyle varepsilon _{i}sim operatorname {Logistic} (0,1),}

es decir la variable latente se puede escribir directamente en términos de la función predictora lineal y una variable de error aleatorio aditivo que se distribuye de acuerdo con una distribución logística estándar.
Entonces Yi puede verse como un indicador de si esta variable latente es positiva:
- 0 {text{ i.e. }}-varepsilon _{i}Yi={}1siYiAlternativa Alternativa ■0i.e.− − ε ε i.β β ⋅ ⋅ Xi,0De lo contrario.{displaystyle Y_{i}={begin{cases}1 sentimiento{if {fnMicrosoft Sans Serif} {X} {fnMicrosoft Sans Serif}}}
0 {text{ i.e. }}-varepsilon _{i}
La elección de modelar la variable de error específicamente con una distribución logística estándar, en lugar de una distribución logística general con la ubicación y la escala establecidas en valores arbitrarios, parece restrictiva, pero de hecho no lo es. Debe tenerse en cuenta que podemos elegir los coeficientes de regresión nosotros mismos y, muy a menudo, podemos usarlos para compensar cambios en los parámetros de la distribución de la variable de error. Por ejemplo, una distribución de variable de error logístico con un parámetro de ubicación distinto de cero μ (que establece la media) es equivalente a una distribución con un parámetro de ubicación cero, donde μ se ha añadido al coeficiente de intersección. Ambas situaciones producen el mismo valor para Yi* independientemente de la configuración de las variables explicativas. De manera similar, un parámetro de escala arbitrario s es equivalente a establecer el parámetro de escala en 1 y luego dividir todos los coeficientes de regresión por s. En este último caso, el valor resultante de Yi* será menor por un factor de s que en el caso anterior, para todos los conjuntos de variables explicativas, pero de manera crítica, siempre permanecerá en el mismo lado de 0 y, por lo tanto, conducirá a la misma Yi elección.
(Tenga en cuenta que esto predice que la irrelevancia del parámetro de escala puede no trasladarse a modelos más complejos donde hay más de dos opciones disponibles).
Resulta que esta formulación es exactamente equivalente a la anterior, expresada en términos del modelo lineal generalizado y sin variables latentes. Esto se puede mostrar de la siguiente manera, utilizando el hecho de que la función de distribución acumulada (CDF) de la distribución logística estándar es la función logística, que es la inversa de la función logit, es decir
- <math alttext="{displaystyle Pr(varepsilon _{i}Pr()ε ε i.x)=logit− − 1 ()x){displaystyle Pr(varepsilon _{i}traducidos)=operatorname {logit} ^{-1}(x)}<img alt="{displaystyle Pr(varepsilon _{i}
Entonces:
- 0mid mathbf {X} _{i})\[5pt]&=Pr({boldsymbol {beta }}cdot mathbf {X} _{i}+varepsilon _{i}>0)\[5pt]&=Pr(varepsilon _{i}>-{boldsymbol {beta }}cdot mathbf {X} _{i})\[5pt]&=Pr(varepsilon _{i}Pr()Yi=1▪ ▪ Xi)=Pr()YiAlternativa Alternativa ■0▪ ▪ Xi)=Pr()β β ⋅ ⋅ Xi+ε ε i■0)=Pr()ε ε i■− − β β ⋅ ⋅ Xi)=Pr()ε ε i.β β ⋅ ⋅ Xi)(porque la distribución logística es simétrica)=logit− − 1 ()β β ⋅ ⋅ Xi)=pi(véase supra){displaystyle {begin{aligned}Pr(Y_{i}=1mid mathbf {X} _{i}) Due=Pr(Y_{i}{ast } {0mid mathbf {X} _{i})[5pt] {X} _{i}+varepsilon _{i} confianza0)[5pt] ################################################################################################################################################################################################################################################################ {X} _{i})[5pt] {varepsilon _{i}{i}{boldsymbol {beta }cdotmathbf {X} _{i})} {i} {i} {i} {i} {i} {i} {i}=i} {i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i} {i}i}i}i}i}i} {i}i}i}i}i}i}i} {i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i}i} {X} {fnMicrosoft Sans Serif}}end{aligned}}
0mid mathbf {X} _{i})\[5pt]&=Pr({boldsymbol {beta }}cdot mathbf {X} _{i}+varepsilon _{i}>0)\[5pt]&=Pr(varepsilon _{i}>-{boldsymbol {beta }}cdot mathbf {X} _{i})\[5pt]&=Pr(varepsilon _{i}
Esta formulación, que es estándar en los modelos de elección discreta, aclara la relación entre la regresión logística (el "modelo logit") y el modelo probit, que utiliza una variable de error distribuida según una distribución normal estándar en lugar de una distribución logística estándar. Tanto la distribución logística como la normal son simétricas con una "curva de campana" unimodal básica. forma. La única diferencia es que la distribución logística tiene colas algo más pesadas, lo que significa que es menos sensible a los datos atípicos (y, por lo tanto, algo más robusta para modelar especificaciones erróneas o datos erróneos).
Modelo bidireccional de variable latente
Otra formulación más usa dos variables latentes separadas:
- Yi0Alternativa Alternativa =β β 0⋅ ⋅ Xi+ε ε 0Yi1Alternativa Alternativa =β β 1⋅ ⋅ Xi+ε ε 1{displaystyle {begin{aligned}Y_{i}{0ast } {boldsymbol {beta }_{0}cdot mathbf [X] _{i}+varepsilon ################################################################################################################################################################################################################################################################ {beta }_{1}cdot mathbf {X} _{i}+varepsilon _{1}end{aligned}

dónde
- ε ε 0♪ ♪ EV1 ()0,1)ε ε 1♪ ♪ EV1 ()0,1){displaystyle {begin{aligned}varepsilon ################################################################################################################################################################################################################################################################ [EV] _{1}(0,1)\varepsilon - ¿Qué?

donde EV1(0,1) es una distribución estándar de valores extremos de tipo 1: es decir,
- Pr()ε ε 0=x)=Pr()ε ε 1=x)=e− − xe− − e− − x{displaystyle Pr(varepsilon _{0}=x)=Pr(varepsilon _{1}=x)=e^{-x}e^{-e^{-x}}}

Entonces
- Y_{i}^{0ast },\0&{text{otherwise.}}end{cases}}}" xmlns="http://www.w3.org/1998/Math/MathML">Yi={}1siYi1Alternativa Alternativa ■Yi0Alternativa Alternativa ,0De lo contrario.{displaystyle Y_{i}={begin{cases}1 sentimiento{if Sí. {fnMicrosoft Sans Serif}}end{cases}}
Y_{i}^{0ast },\0&{text{otherwise.}}end{cases}}" aria-hidden="true" class="mwe-math-fallback-image-inline" src="https://wikimedia.org/api/rest_v1/media/math/render/svg/3d267a820539ad6e4f16ced8f8bdfe4bd908d8c6" style="vertical-align: -2.505ex; width:24.466ex; height:6.176ex;"/>
Este modelo tiene una variable latente separada y un conjunto separado de coeficientes de regresión para cada resultado posible de la variable dependiente. El motivo de esta separación es que facilita la extensión de la regresión logística a variables categóricas de resultados múltiples, como en el modelo logit multinomial. En tal modelo, es natural modelar cada resultado posible utilizando un conjunto diferente de coeficientes de regresión. También es posible motivar cada una de las variables latentes separadas como la utilidad teórica asociada con la elección asociada y, por lo tanto, motivar la regresión logística en términos de la teoría de la utilidad. (En términos de la teoría de la utilidad, un actor racional siempre elige la opción con la mayor utilidad asociada). Este es el enfoque adoptado por los economistas al formular modelos de elección discreta, porque proporciona una base teórica sólida y facilita las intuiciones sobre el modelo, que a su vez facilita la consideración de varios tipos de extensiones. (Vea el ejemplo a continuación).
La elección de la distribución de valores extremos de tipo 1 parece bastante arbitraria, pero hace que las matemáticas funcionen y es posible justificar su uso a través de la teoría de la elección racional.
Resulta que este modelo es equivalente al modelo anterior, aunque esto no parece obvio, ya que ahora hay dos conjuntos de coeficientes de regresión y variables de error, y las variables de error tienen una distribución diferente. De hecho, este modelo reduce directamente al anterior con las siguientes sustituciones:
- β β =β β 1− − β β 0{displaystyle {boldsymbol {beta }={boldsymbol {beta }_{1}-{boldsymbol {beta }
- ε ε =ε ε 1− − ε ε 0{displaystyle varepsilon =varepsilon _{1}-varepsilon ¿Qué?


Una intuición para esto viene del hecho de que, puesto que elegimos basado en el máximo de dos valores, sólo su diferencia importa, no los valores exactos — y esto elimina efectivamente un grado de libertad. Otro hecho crítico es que la diferencia de dos variables de valor extremo tipo-1 es una distribución logística, es decir. ε ε =ε ε 1− − ε ε 0♪ ♪ Logística ()0,1).{displaystyle varepsilon =varepsilon _{1}-varepsilon _{0}sim operatorname {Logistic} (0,1). } Podemos demostrar el equivalente como sigue:

- Y_{i}^{0ast }mid mathbf {X} _{i}right)&\[5pt]={}&Pr left(Y_{i}^{1ast }-Y_{i}^{0ast }>0mid mathbf {X} _{i}right)&\[5pt]={}&Pr left({boldsymbol {beta }}_{1}cdot mathbf {X} _{i}+varepsilon _{1}-left({boldsymbol {beta }}_{0}cdot mathbf {X} _{i}+varepsilon _{0}right)>0right)&\[5pt]={}&Pr left(({boldsymbol {beta }}_{1}cdot mathbf {X} _{i}-{boldsymbol {beta }}_{0}cdot mathbf {X} _{i})+(varepsilon _{1}-varepsilon _{0})>0right)&\[5pt]={}&Pr(({boldsymbol {beta }}_{1}-{boldsymbol {beta }}_{0})cdot mathbf {X} _{i}+(varepsilon _{1}-varepsilon _{0})>0)&\[5pt]={}&Pr(({boldsymbol {beta }}_{1}-{boldsymbol {beta }}_{0})cdot mathbf {X} _{i}+varepsilon >0)&&{text{(substitute }}varepsilon {text{ as above)}}\[5pt]={}&Pr({boldsymbol {beta }}cdot mathbf {X} _{i}+varepsilon >0)&&{text{(substitute }}{boldsymbol {beta }}{text{ as above)}}\[5pt]={}&Pr(varepsilon >-{boldsymbol {beta }}cdot mathbf {X} _{i})&&{text{(now, same as above model)}}\[5pt]={}&Pr(varepsilon Pr()Yi=1▪ ▪ Xi)=Pr()Yi1Alternativa Alternativa ■Yi0Alternativa Alternativa ▪ ▪ Xi)=Pr()Yi1Alternativa Alternativa − − Yi0Alternativa Alternativa ■0▪ ▪ Xi)=Pr()β β 1⋅ ⋅ Xi+ε ε 1− − ()β β 0⋅ ⋅ Xi+ε ε 0)■0)=Pr()()β β 1⋅ ⋅ Xi− − β β 0⋅ ⋅ Xi)+()ε ε 1− − ε ε 0)■0)=Pr()()β β 1− − β β 0)⋅ ⋅ Xi+()ε ε 1− − ε ε 0)■0)=Pr()()β β 1− − β β 0)⋅ ⋅ Xi+ε ε ■0)(Sustituto)ε ε arriba)=Pr()β β ⋅ ⋅ Xi+ε ε ■0)(Sustituto)β β arriba)=Pr()ε ε ■− − β β ⋅ ⋅ Xi)(ahora, igual que el modelo anterior)=Pr()ε ε .β β ⋅ ⋅ Xi)=logit− − 1 ()β β ⋅ ⋅ Xi)=pi{displaystyle {begin{aligned}Pr(Y_{i}=1mid {X}* Pr left(Y_{i}{1ast } Y... {X}{i}derecha) Pr left - Sí. {X}{i}derecha) Pr left({boldsymbol {beta }_{1}cdot mathbf [X] _{i}+varepsilon ¿Por qué? }_{0}cdot mathbf [X] _{i}+varepsilon ¿Por qué? Pr left({boldsymbol {beta }_{1}cdot mathbf {X} {beta }_{0}cdot mathbf [X] _{i})+(varepsilon _{1}-varepsilon {} {})} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} }_{1}-{boldsymbol {beta }_{0})cdot mathbf [X] _{i}+(varepsilon ¿Por qué? }_{1}-{boldsymbol {beta }_{0})cdot mathbf {X} _{i}+varepsilon √0) {text{ as above)}cdot mathbf {X} _{i}+varepsilon √0)} {text{fnuncio}{boldsymbol {beta }{text{ as above)}[5pt]={}{} {cdotcdotcr(varepsilon } {i} {cdotcdotcdoti}{} {cdotcdot} {cdotcdotcdotcdotc} {cdoti} {} {cdotcdot} {i} {cdotc}}}} {i} {i} {cdotcdotcdotc} {cdot} {cdotc} {i} {cdotc} {i} {i} {c} {i} {c} {i}}} {i} {cdotc}}} [5pt]={beta }cdot mathbf {X} _{i} {fnc}cdot mathbf {X} {fn} {fnK} {fnK}} {fnK}} {fnK}} {fn}}}} {fn} {fnK}}}} {fnK}}}}}}}}} {\fnK}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} {\\\\\\\\\}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}
Y_{i}^{0ast }mid mathbf {X} _{i}right)&\[5pt]={}&Pr left(Y_{i}^{1ast }-Y_{i}^{0ast }>0mid mathbf {X} _{i}right)&\[5pt]={}&Pr left({boldsymbol {beta }}_{1}cdot mathbf {X} _{i}+varepsilon _{1}-left({boldsymbol {beta }}_{0}cdot mathbf {X} _{i}+varepsilon _{0}right)>0right)&\[5pt]={}&Pr left(({boldsymbol {beta }}_{1}cdot mathbf {X} _{i}-{boldsymbol {beta }}_{0}cdot mathbf {X} _{i})+(varepsilon _{1}-varepsilon _{0})>0right)&\[5pt]={}&Pr(({boldsymbol {beta }}_{1}-{boldsymbol {beta }}_{0})cdot mathbf {X} _{i}+(varepsilon _{1}-varepsilon _{0})>0)&\[5pt]={}&Pr(({boldsymbol {beta }}_{1}-{boldsymbol {beta }}_{0})cdot mathbf {X} _{i}+varepsilon >0)&&{text{(substitute }}varepsilon {text{ as above)}}\[5pt]={}&Pr({boldsymbol {beta }}cdot mathbf {X} _{i}+varepsilon >0)&&{text{(substitute }}{boldsymbol {beta }}{text{ as above)}}\[5pt]={}&Pr(varepsilon >-{boldsymbol {beta }}cdot mathbf {X} _{i})&&{text{(now, same as above model)}}\[5pt]={}&Pr(varepsilon
Ejemplo
Como ejemplo, considere una elección a nivel provincial donde la elección es entre un partido de centro-derecha, un partido de centro-izquierda y un partido secesionista (por ejemplo, el Parti Québécois, que quiere que Quebec se separe de Canadá). Entonces usaríamos tres variables latentes, una para cada elección. Luego, de acuerdo con la teoría de la utilidad, podemos interpretar las variables latentes como expresión de la utilidad que resulta de hacer cada una de las elecciones. También podemos interpretar los coeficientes de regresión como indicadores de la fuerza que tiene el factor asociado (es decir, la variable explicativa) para contribuir a la utilidad, o más correctamente, la cantidad por la cual un cambio unitario en una variable explicativa cambia la utilidad de una elección dada. Un votante podría esperar que el partido de centro-derecha bajara los impuestos, especialmente a los ricos. Esto no daría ningún beneficio a las personas de bajos ingresos, es decir, ningún cambio en la utilidad (ya que generalmente no pagan impuestos); causaría un beneficio moderado (es decir, algo más de dinero o un aumento moderado de la utilidad) para las personas de ingreso medio; generaría importantes beneficios para las personas de altos ingresos. Por otro lado, se podría esperar que el partido de centro-izquierda aumente los impuestos y los compense con un mayor bienestar y otras ayudas para las clases media y baja. Esto causaría un beneficio positivo significativo para las personas de bajos ingresos, tal vez un beneficio débil para las personas de ingresos medios y un beneficio negativo significativo para las personas de ingresos altos. Finalmente, el partido secesionista no tomaría medidas directas sobre la economía, sino que simplemente se separaría. Un votante de bajos o medianos ingresos podría no esperar básicamente ninguna ganancia o pérdida clara de utilidad de esto, pero un votante de altos ingresos podría esperar una utilidad negativa ya que es probable que sea propietario de empresas, lo que le resultará más difícil hacer negocios en tal ambiente y probablemente pierda dinero.
Estas intuiciones se pueden expresar de la siguiente manera:
| Center-right | Center-left | Secesionista | |
|---|---|---|---|
| Altos ingresos | fuerte + | fuerte − | fuerte − |
| Ingresos medios | moderado + | débil + | ninguno |
| Ingresos bajos | ninguno | fuerte + | ninguno |
Esto muestra claramente que
- Hay que establecer conjuntos separados de coeficientes de regresión para cada elección. Cuando se expresa en términos de utilidad, esto se puede ver muy fácilmente. Las diferentes opciones tienen diferentes efectos en la utilidad neta; además, los efectos varían de maneras complejas que dependen de las características de cada individuo, por lo que hay que ser conjuntos separados de coeficientes para cada característica, no simplemente una única característica extra por elección.
- Aunque el ingreso es una variable continua, su efecto en la utilidad es demasiado complejo para que se trate como una sola variable. O necesita dividirse directamente en rangos, o mayores poderes de ingreso deben ser añadidos para que la regresión polinomio en ingresos se haga efectivamente.
Como "log-lineal" modelo
Otra formulación combina la formulación de variable latente bidireccional anterior con la formulación original más arriba sin variables latentes, y en el proceso proporciona un enlace a una de las formulaciones estándar del logit multinomial.
Aquí, en lugar de escribir el logit de las probabilidades pi como un predictor lineal, separamos el predictor lineal en dos, uno para cada uno de los dos resultados:
- In Pr()Yi=0)=β β 0⋅ ⋅ Xi− − In ZIn Pr()Yi=1)=β β 1⋅ ⋅ Xi− − In Z{displaystyle {begin{aligned}ln} Pr(Y_{i}=0) {beta }_{0}cdot mathbf {X} _{i}-ln Z\\\ln\cH}=1) {beta }_{1}cdot mathbf [X] _{i}-ln Zend{aligned}}

Se han introducido dos conjuntos separados de coeficientes de regresión, al igual que en el modelo variable de dos vías, y las dos ecuaciones aparecen una forma que escribe el logaritmo de la probabilidad asociada como predictor lineal, con un término extra − − In Z{displaystyle -ln Z} al final. Este término, como resulta, sirve como factor de normalización asegurando que el resultado sea una distribución. Esto se puede ver exponente de ambos lados:

- Pr()Yi=0)=1Zeβ β 0⋅ ⋅ XiPr()Yi=1)=1Zeβ β 1⋅ ⋅ Xi{displaystyle {begin{aligned} Pr(Y_{i}=0) {1} {fn}e}e^{\boldsymbol {beta} }_{0}cdot mathbf {X}_{i}[5pt]Pr(Y_{i}=1) Consigu={frac {1}{Z}e^{boldsymbol {beta] }_{1}cdot mathbf {X} {fn} {fnK} {fnK}} {fnK}} {fnK}}} {fn}}} {fn}}} {fnK}}}}}} {fnK}}}}}}} {fnK}}}}}fnKf}}}}} {f}}}}}}}}}}}}}}f}}}}}}}}}}}}}}}}}}}}}}}f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}
![{displaystyle {begin{aligned}Pr(Y_{i}=0)&={frac {1}{Z}}e^{{boldsymbol {beta }}_{0}cdot mathbf {X} _{i}}\[5pt]Pr(Y_{i}=1)&={frac {1}{Z}}e^{{boldsymbol {beta }}_{1}cdot mathbf {X} _{i}}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6e1e2a04fd15f2e5617c0606a7644fe719823960)
De esta forma está claro que el propósito de Z es asegurar que la distribución resultante sobre Yi es de hecho una distribución de probabilidad, es decir, suma 1. Esto significa que Z es simplemente la suma de todas las probabilidades no normalizadas, y dividiendo cada probabilidad por Z, las probabilidades se "normalizan". Eso es:
- Z=eβ β 0⋅ ⋅ Xi+eβ β 1⋅ ⋅ Xi{displaystyle Z=e^{boldsymbol {beta }_{0}cdot mathbf {X} {fnK}+e^{boldsymbol {beta }_{1}cdot mathbf {X}

y las ecuaciones resultantes son
- Pr()Yi=0)=eβ β 0⋅ ⋅ Xieβ β 0⋅ ⋅ Xi+eβ β 1⋅ ⋅ XiPr()Yi=1)=eβ β 1⋅ ⋅ Xieβ β 0⋅ ⋅ Xi+eβ β 1⋅ ⋅ Xi.{displaystyle {begin{aligned} Pr(Y_{i}=0) {beta }_{0}cdot mathbf {X} {fn} {fnMicrosoft} {fnMicrosoft}} {fnK}} {fnMicrosoft} {fnK}}} {fnK}} {fnK}} {fnK}} {f}}} {f}}}}} {fnKf}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} {p}}}}}} {p}}}}} {p}}}}} {p}}}}}}}}}}}}}}}}}} {p} {p}}} {p}}}} {m}}}} {p}} {p}}}}}}}}}}}}}}} {p}}}}}}}}}}}}}}}}}}}}}}}}}}}} {beta }_{0}cdot mathbf {X} {fnK}+e^{boldsymbol {beta }_{1}cdot mathbf {X} {f}}[5pt]Pr(Y_{i}=1) {beta }_{1}cdot mathbf {X} {fn} {fnMicrosoft} {fnMicrosoft}} {fnK}} {fnMicrosoft} {fnK}}} {fnK}} {fnK}} {fnK}} {f}}} {f}}}}} {fnKf}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} {p}}}}}} {p}}}}} {p}}}}} {p}}}}}}}}}}}}}}}}}} {p} {p}}} {p}}}} {m}}}} {p}} {p}}}}}}}}}}}}}}} {p}}}}}}}}}}}}}}}}}}}}}}}}}}}} {beta }_{0}cdot mathbf {X} {fnK}+e^{boldsymbol {beta }_{1}cdot mathbf {X} {fn}} {fnMicrosoft}} {fnMicrosoft}} {fnMicrosoft}} {f}} {fnK}}}} {fnK}}} {fnK}} {f}}}}}}}}}}} {f}}}} {f}}}}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} {f}}} {f}}}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}} {f}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}
![{displaystyle {begin{aligned}Pr(Y_{i}=0)&={frac {e^{{boldsymbol {beta }}_{0}cdot mathbf {X} _{i}}}{e^{{boldsymbol {beta }}_{0}cdot mathbf {X} _{i}}+e^{{boldsymbol {beta }}_{1}cdot mathbf {X} _{i}}}}\[5pt]Pr(Y_{i}=1)&={frac {e^{{boldsymbol {beta }}_{1}cdot mathbf {X} _{i}}}{e^{{boldsymbol {beta }}_{0}cdot mathbf {X} _{i}}+e^{{boldsymbol {beta }}_{1}cdot mathbf {X} _{i}}}}.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1fa489d73be139142872ddccccecd567635525d5)
O generalmente:
- Pr()Yi=c)=eβ β c⋅ ⋅ Xi.. heβ β h⋅ ⋅ Xi{displaystyle Pr(Y_{i}=c)={frac {e^{boldsymbol {beta }_{c}cdot mathbf {X} {fn} {fnMicrosoft}} {fnMicrosoft}} {fnMicrosoft}} {fn}} {fnK}}}}} {fnK}}}}} {fnK}}}}} {f}} {f}}}}}}}}} {f}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}} {f}}} {f}}}}}}}}} {f}}}}}}}}}}}}}} {f}}}}}}}}}}}}}} {f}}}}}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}} { ¿Qué? {beta }_{h}cdot mathbf {X}

Esto muestra claramente cómo generalizar esta formulación a más de dos resultados, como en logit multinomial. Tenga en cuenta que esta formulación general es exactamente la función softmax como en
- Pr()Yi=c)=softmax ()c,β β 0⋅ ⋅ Xi,β β 1⋅ ⋅ Xi,...... ).{displaystyle Pr(Y_{i}=c)=operatorname {softmax} (c,{boldsym {bolbeta }_{0}cdot mathbf {X} _{i},{boldsymbol {beta }_{1}cdot mathbf {X} _{i},dots).}

Para demostrar que esto es equivalente al modelo anterior, tenga en cuenta que el modelo anterior es sobreespejado, en que Pr()Yi=0){displaystyle Pr(Y_{i}=0)} y Pr()Yi=1){displaystyle Pr(Y_{i}=1)} no puede ser especificado independientemente: más bien Pr()Yi=0)+Pr()Yi=1)=1{displaystyle Pr(Y_{i}=0)+ Pr(Y_{i}=1)=1} así que conocer uno determina automáticamente el otro. Como resultado, el modelo no es identificable, en que múltiples combinaciones de β0 y β1 producirá las mismas probabilidades para todas las variables explicativas posibles. De hecho, se puede ver que añadir cualquier vector constante a ambos producirá las mismas probabilidades:



- Pr()Yi=1)=e()β β 1+C)⋅ ⋅ Xie()β β 0+C)⋅ ⋅ Xi+e()β β 1+C)⋅ ⋅ Xi=eβ β 1⋅ ⋅ XieC⋅ ⋅ Xieβ β 0⋅ ⋅ XieC⋅ ⋅ Xi+eβ β 1⋅ ⋅ XieC⋅ ⋅ Xi=eC⋅ ⋅ Xieβ β 1⋅ ⋅ XieC⋅ ⋅ Xi()eβ β 0⋅ ⋅ Xi+eβ β 1⋅ ⋅ Xi)=eβ β 1⋅ ⋅ Xieβ β 0⋅ ⋅ Xi+eβ β 1⋅ ⋅ Xi.{displaystyle {begin{aligned}Pr(Y_{i}=1) ventaja={frac {e^{boldsymbol {beta }_{1}+mathbf {C})cdot mathbf {fnK} {f} {fnK}} {fnK}} {f}} {f}} {f}} {f}}}} {f}}}} {f}}}}}} {f}}} {f}}}} {f}}}}} {f}}}}}} {f}}}}}} {f}}}}}}}}}}}}}} {p}}}}} {p}}}}}} {p}}}} {p} {p} {f}} {p}}}}}}}}}}}}}}}}}}}} {p} {f}} {p}}}} {p}}}}} {ppppp}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} }_{0}+mathbf {C})cdot mathbf {X} {fn}+e^{boldsymbol {beta} }_{1}+mathbf {C})cdot mathbf {X} {fn}}[5pt] {cHFF} {beta }_{1}cdot mathbf {X} {fn}e}e^ {fnMitbf} {C} cdot mathbf {X} {fn} {fnMicrosoft} {fnMicrosoft}} {fnK}} {fnMicrosoft} {fnK}}} {fnK}} {fnK}} {fnK}} {f}}} {f}}}}} {fnKf}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} {p}}}}}} {p}}}}} {p}}}}} {p}}}}}}}}}}}}}}}}}} {p} {p}}} {p}}}} {m}}}} {p}} {p}}}}}}}}}}}}}}} {p}}}}}}}}}}}}}}}}}}}}}}}}}}}} {beta }_{0}cdot mathbf {X} {fn}e}e^ {fnMitbf} {C} cdot mathbf {X} {fnK}+e^{boldsymbol {beta }_{1}cdot mathbf {X} {fn}e}e^ {fnMitbf} {C} cdot mathbf {X} {fn}}[5pt] {C} cdot mathbf {X} {fn}e}e^{fncipi} {beta }_{1}cdot mathbf {X} {fn} {fnMitbf} {fnK}} {f}} {f}} {f}} {f}}} {f}}} {f}}}}}} {f}}}}} {f} {f} {f}}}} {f}}}}}}}}} {f}}}} {f}}}}}}}}}}}}}}}}}}}}}} {f}}}}} {f}}}}} {f}}}} {f}}} {f} {f}}}}}}} {f}}}}}}}}} {f}}}} {f}}}} {f}}} {f}}}}}}}}}} {f} {f} {f} {f}} {f}}}}}}}}}}}}}}}}}}}}} {C} cdot mathbf {X} {fn} {fnMicrosoft} {fnMicrosoft} {fnMicrosoft} }_{0}cdot mathbf {X} {fnK}+e^{boldsymbol {beta }_{1}cdot mathbf {X} {fnK}}[5pt] {cHFF} {beta }_{1}cdot mathbf {X} {fn} {fnMicrosoft} {fnMicrosoft}} {fnK}} {fnMicrosoft} {fnK}}} {fnK}} {fnK}} {fnK}} {f}}} {f}}}}} {fnKf}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} {p}}}}}} {p}}}}} {p}}}}} {p}}}}}}}}}}}}}}}}}} {p} {p}}} {p}}}} {m}}}} {p}} {p}}}}}}}}}}}}}}} {p}}}}}}}}}}}}}}}}}}}}}}}}}}}} {beta }_{0}cdot mathbf {X} {fnK}+e^{boldsymbol {beta }_{1}cdot mathbf {X} {fn}} {fnMicrosoft}} {fnMicrosoft}} {fnMicrosoft}} {f}} {fnK}}}} {fnK}}} {fnK}} {f}}}}}}}}}}} {f}}}} {f}}}}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} {f}}} {f}}}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}} {f}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}
![{displaystyle {begin{aligned}Pr(Y_{i}=1)&={frac {e^{({boldsymbol {beta }}_{1}+mathbf {C})cdot mathbf {X} _{i}}}{e^{({boldsymbol {beta }}_{0}+mathbf {C})cdot mathbf {X} _{i}}+e^{({boldsymbol {beta }}_{1}+mathbf {C})cdot mathbf {X} _{i}}}}\[5pt]&={frac {e^{{boldsymbol {beta }}_{1}cdot mathbf {X} _{i}}e^{mathbf {C} cdot mathbf {X} _{i}}}{e^{{boldsymbol {beta }}_{0}cdot mathbf {X} _{i}}e^{mathbf {C} cdot mathbf {X} _{i}}+e^{{boldsymbol {beta }}_{1}cdot mathbf {X} _{i}}e^{mathbf {C} cdot mathbf {X} _{i}}}}\[5pt]&={frac {e^{mathbf {C} cdot mathbf {X} _{i}}e^{{boldsymbol {beta }}_{1}cdot mathbf {X} _{i}}}{e^{mathbf {C} cdot mathbf {X} _{i}}(e^{{boldsymbol {beta }}_{0}cdot mathbf {X} _{i}}+e^{{boldsymbol {beta }}_{1}cdot mathbf {X} _{i}})}}\[5pt]&={frac {e^{{boldsymbol {beta }}_{1}cdot mathbf {X} _{i}}}{e^{{boldsymbol {beta }}_{0}cdot mathbf {X} _{i}}+e^{{boldsymbol {beta }}_{1}cdot mathbf {X} _{i}}}}.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4f545a36890435f35e006242acda552c8f62dcd0)
Como resultado, podemos simplificar los asuntos y restaurar la identificación, escogiendo un valor arbitrario para uno de los dos vectores. Elegimos establecer β β 0=0.{displaystyle {boldsymbol {beta ♪♪♪♪♪ {0} Entonces,

- eβ β 0⋅ ⋅ Xi=e0⋅ ⋅ Xi=1{displaystyle e^{boldsymbol {beta }_{0}cdot mathbf {X} {fn}=e} {fnMitbf} {0} cdot mathbf {X}}=1}

y así
- Pr()Yi=1)=eβ β 1⋅ ⋅ Xi1+eβ β 1⋅ ⋅ Xi=11+e− − β β 1⋅ ⋅ Xi=pi{displaystyle Pr(Y_{i}=1)={frac {e^{boldsymbol {beta }_{1}cdot mathbf {X} {fn}{1+e^{boldsymbol {beta }_{1}cdot mathbf {X} {fn}}={fnMic} {1}{1+e^{-{boldsymbol {beta }_{1}cdot mathbf {X} ♪♪

lo que demuestra que esta formulación es en efecto equivalente a la formulación anterior. (Como en la formulación variable latente bidireccional, cualquier configuración donde β β =β β 1− − β β 0{displaystyle {boldsymbol {beta }={boldsymbol {beta }_{1}-{boldsymbol {beta } producirá resultados equivalentes.)
Tenga en cuenta que la mayoría de los tratamientos del modelo logit multinomial comienzan extendiendo el "log-lineal" presentada aquí o la formulación de variable latente bidireccional presentada anteriormente, ya que ambas muestran claramente la forma en que el modelo podría extenderse a resultados multidireccionales. En general, la presentación con variables latentes es más común en econometría y ciencia política, donde reinan los modelos de elección discreta y la teoría de la utilidad, mientras que la "log-lineal" la formulación aquí es más común en informática, p. Aprendizaje automático y procesamiento de lenguaje natural.
Como perceptrón de una sola capa
El modelo tiene una formulación equivalente
- pi=11+e− − ()β β 0+β β 1x1,i+⋯ ⋯ +β β kxk,i).{displaystyle ¿Por qué? ##{1}x_{1,i}+cdots +beta.

Esta forma funcional se denomina comúnmente perceptrón de una sola capa o red neuronal artificial de una sola capa. Una red neuronal de una sola capa calcula una salida continua en lugar de una función de paso. La derivada de pi con respecto a X = (x1,..., xk) se calcula a partir de la forma general:
- Sí.=11+e− − f()X){displaystyle y={frac {1}{1+e^{-f(X)}}}}

donde f(X) es una función analítica en X. Con esta elección, la red neuronal de una sola capa es idéntica al modelo de regresión logística. Esta función tiene una derivada continua, lo que permite su uso en backpropagation. También se prefiere esta función porque su derivada se calcula fácilmente:
- dSí.dX=Sí.()1− − Sí.)dfdX.{displaystyle {frac {mathrm}}{mathrm {}}=y(1-y){frac {mathrm {d} f}{mathrm {d} {d} #

En términos de datos binomiales
Un modelo estrechamente relacionado asume que cada i no está asociado con un único ensayo de Bernoulli sino con ni ensayos independientes distribuidos de forma idéntica, donde la observación Yi es el número de éxitos observados (la suma de las variables aleatorias individuales distribuidas por Bernoulli), y por lo tanto sigue una distribución binomial:
- Yi♪ ♪ Bin ()ni,pi),parai=1,...... ,n{displaystyle Y_{i},sim operatorname {Bin} (n_{i},p_{i}),{text{ for }i=1,dotsn}

Un ejemplo de esta distribución es la fracción de semillas (pi) que germinan después de ni están plantados.
En términos de valores esperados, este modelo se expresa de la siguiente manera:
- pi=E [YiniSilencioXi],{displaystyle p_{i}=operatorname {mathbb {E} left[left.{frac {Y_{i} {fn},derecha a la vida,fnMitbf ¿Qué?
![{displaystyle p_{i}=operatorname {mathbb {E} } left[left.{frac {Y_{i}}{n_{i}}},right|,mathbf {X} _{i}right],,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e2b159f2ac064c09122cc087d3d9e8d3bbb415f9)
para que
- logit ()E [YiniSilencioXi])=logit ()pi)=In ()pi1− − pi)=β β ⋅ ⋅ Xi,{displaystyle operatorname {logit} left(operatorname) # Mathbb {E} left[left.{frac {Y_{i} {fn},derecha a la vida,fnMitbf [X} _{i}right]right)=operatorname {logit} (p_{i})=ln left({frac] {fnK}{1-p_{i}}right)={boldsymbol {beta}cdot mathbf {X}
![{displaystyle operatorname {logit} left(operatorname {mathbb {E} } left[left.{frac {Y_{i}}{n_{i}}},right|,mathbf {X} _{i}right]right)=operatorname {logit} (p_{i})=ln left({frac {p_{i}}{1-p_{i}}}right)={boldsymbol {beta }}cdot mathbf {X} _{i},,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4629c0d5675907b48d10f5173bbc338f262e540a)
O de manera equivalente:
- Pr()Yi=Sí.▪ ▪ Xi)=()niSí.)piSí.()1− − pi)ni− − Sí.=()niSí.)()11+e− − β β ⋅ ⋅ Xi)Sí.()1− − 11+e− − β β ⋅ ⋅ Xi)ni− − Sí..{displaystyle Pr(Y_{i}=ymid mathbf {X} _{i}={n_{i} ################################################################################################################################################################################################################################################################ choose y}left({1}{1+e^{-{-{boldsymbol {beta }cdot mathbf Está bien. {1}{1+e^{-{boldsymbol {beta }cdot mathbf Bueno...

Este modelo se puede ajustar utilizando los mismos tipos de métodos que el modelo más básico anterior.
Ajuste del modelo
Estimación de máxima verosimilitud (MLE)
Los coeficientes de regresión generalmente se estiman utilizando la estimación de máxima verosimilitud. A diferencia de la regresión lineal con residuos normalmente distribuidos, no es posible encontrar una expresión de forma cerrada para los valores de los coeficientes que maximicen la función de verosimilitud, por lo que se debe usar un proceso iterativo en su lugar; por ejemplo el método de Newton. Este proceso comienza con una solución tentativa, la revisa ligeramente para ver si se puede mejorar y repite esta revisión hasta que no se realizan más mejoras, en cuyo punto se dice que el proceso ha convergido.
En algunos casos, es posible que el modelo no alcance la convergencia. La no convergencia de un modelo indica que los coeficientes no son significativos porque el proceso iterativo no pudo encontrar soluciones apropiadas. Una falla en la convergencia puede ocurrir por varias razones: tener una gran proporción de predictores a casos, multicolinealidad, escasez o separación completa.
- Tener una gran proporción de variables a casos resulta en una estadística Wald demasiado conservadora (discutida abajo) y puede conducir a la no convergencia. La regresión logística regularizada está específicamente destinada a ser utilizada en esta situación.
- Multicollinearidad se refiere a correlaciones inaceptablemente altas entre predictores. A medida que aumenta la multicollinearidad, los coeficientes siguen siendo imparciales pero aumentan los errores estándar y disminuye la probabilidad de convergencia modelo. Para detectar la multicollinearidad entre los predictores, se puede realizar un análisis de regresión lineal con los predictores de interés con el único propósito de examinar la estadística de tolerancia utilizada para evaluar si la multicollinearidad es inaceptablemente alta.
- La escasez en los datos se refiere a tener una gran proporción de células vacías (células con cero recuentos). Los recuentos de células cero son particularmente problemáticos con predictores categóricos. Con predictores continuos, el modelo puede inferir valores para los recuentos de células cero, pero este no es el caso con predictores categóricos. El modelo no convergerá con los recuentos de células cero para los predictores categóricos porque el logaritmo natural de cero es un valor indefinido para que no pueda alcanzarse la solución final al modelo. Para remediar este problema, los investigadores pueden colapsar categorías de manera teóricamente significativa o añadir una constante a todas las células.
- Otro problema numérico que puede llevar a una falta de convergencia es la separación completa, que se refiere a la instancia en la que los predictores predicen perfectamente el criterio – todos los casos se clasifican con precisión y la probabilidad se maximiza con coeficientes infinitos. En tales casos, uno debe volver a examinar los datos, ya que puede haber algún tipo de error.
- También se pueden adoptar enfoques semiparamétricos o no paramétricos, por ejemplo, mediante métodos de probabilidad local o de probabilidad cuasimétrica no paramétrica, que evitan las suposiciones de una forma paramétrica para la función índice y es robusta para la elección de la función de enlace (por ejemplo, probit o logit).
Mínimos cuadrados reponderados iterativamente (IRLS)
Regresión logística binariaSí.=0{displaystyle y=0} o Sí.=1{displaystyle y=1}) puede, por ejemplo, ser calculado utilizando iterativamente re ponderado menos cuadrados (IRLS), que equivale a maximizar la probabilidad de registro de un proceso distribuido Bernoulli utilizando el método de Newton. Si el problema está escrito en forma de matriz vectorial, con parámetros wT=[β β 0,β β 1,β β 2,...... ]{displaystyle mathbf {} {beta _{0},beta _{1},beta _{2},ldots}, variables explicativas x()i)=[1,x1()i),x2()i),...... ]T{displaystyle mathbf {x} (i)=[1,x_{1}(i),x_{2}(i),ldots ]^{T} y el valor esperado de la distribución Bernoulli μ μ ()i)=11+e− − wTx()i){displaystyle mu (i)={1}{1+e^{-mathbf {} }mathbf {x}}}}, los parámetros w{displaystyle mathbf {w} se puede encontrar utilizando el siguiente algoritmo iterativo:

![{displaystyle mathbf {w} ^{T}=[beta _{0},beta _{1},beta _{2},ldots ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/daccbf84c2c936e0559016491efe98eaf0eca430)
![{displaystyle mathbf {x} (i)=[1,x_{1}(i),x_{2}(i),ldots ]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c8fc5f11bdd42f672417a3f4e44b3a4e5be28faa)


- wk+1=()XTSkX)− − 1XT()SkXwk+Sí.− − μ μ k){displaystyle mathbf {w} ¿Por qué? {X} {T}mathbf {fnMicrosoft Sans Serif} {X} right)^{-1}mathbf [X] ^{T}left(mathbf {fnMicrosoft Sans Serif} {X} mathbf {w} _{k}+mathbf {y} -mathbf {boldsymbol {mu } _{k}right)}

Donde S=diag ()μ μ ()i)()1− − μ μ ()i))){displaystyle mathbf {S} =operatorname {diag} (mu (i)(1-mu (i))}} es una matriz diagonal de ponderación, μ μ =[μ μ ()1),μ μ ()2),...... ]{displaystyle {boldsymbol {mu }=[mu (1),mu (2),ldots ]} el vector de los valores esperados,

![{displaystyle {boldsymbol {mu }}=[mu (1),mu (2),ldots ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/800927e9be36f4cac166a68862c04234cffd67b8)
- X=[1x1()1)x2()1)...... 1x1()2)x2()2)...... ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ]{displaystyle mathbf {X} ={begin{bmatrix}1 implicax_{1}(1) implicax_{2}(1)ldots \1 implicax_{1}(2) conllevax_{2}(2) limitldots \\vdots >vdots end{bmatrix}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} {X}=

La matriz de regresión y Sí.()i)=[Sí.()1),Sí.()2),...... ]T{displaystyle mathbf {y} (i)=[y(1),y(2),ldots ]^{T} el vector de variables de respuesta. En la literatura se pueden encontrar más detalles.
![{displaystyle mathbf {y} (i)=[y(1),y(2),ldots ]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/33cbd315328b6ccfc7f216d65e39f92a8ec48694)
Bayesiano



En un contexto de estadísticas bayesianas, las distribuciones previas normalmente se colocan en los coeficientes de regresión, por ejemplo, en forma de distribuciones gaussianas. No hay un previo conjugado de la función de verosimilitud en la regresión logística. Cuando la inferencia bayesiana se realizó analíticamente, esto hizo que la distribución posterior fuera difícil de calcular excepto en dimensiones muy pequeñas. Ahora, sin embargo, el software automático como OpenBUGS, JAGS, PyMC3, Stan o Turing.jl permite que estos posteriores se calculen mediante simulación, por lo que la falta de conjugación no es una preocupación. Sin embargo, cuando el tamaño de la muestra o el número de parámetros es grande, la simulación bayesiana completa puede ser lenta, y las personas suelen utilizar métodos aproximados, como los métodos bayesianos variacionales y la propagación de expectativas.
"Regla de diez"
Una regla de pulgar ampliamente utilizada, la "una en diez reglas", afirma que los modelos de regresión logística dan valores estables para las variables explicativas si se basan en un mínimo de 10 eventos por variable explicativa (EPV); donde evento denota los casos pertenecientes a la categoría menos frecuente en la variable dependiente. Así un estudio diseñado para usar k{displaystyle k} variables explicativas para un evento (por ejemplo, infarto de miocardio) se espera que ocurra en una proporción p{displaystyle p} de los participantes en el estudio requerirá un total de 10k/p{displaystyle 10k/p} participantes. Sin embargo, hay un debate considerable sobre la fiabilidad de esta norma, que se basa en estudios de simulación y carece de un fundamento teórico seguro. Según algunos autores, la regla es excesivamente conservadora en algunas circunstancias, con los autores afirmando, "Si consideramos (algo subjetivamente) la cobertura del intervalo de confianza menos del 93 por ciento, error tipo I mayor del 7 por ciento, o sesgo relativo superior al 15 por ciento como problemático, nuestros resultados indican que los problemas son bastante frecuentes con 2-4 EPV, poco común con 5-9 EPV, y todavía observado con 10-16 EPV. Las peores instancias de cada problema no fueron severas con 5-9 EPV y generalmente comparables a las de 10-16 EPV".



Otros han encontrado resultados que no son consistentes con los anteriores, utilizando criterios diferentes. Un criterio útil es si se espera que el modelo ajustado logre la misma discriminación predictiva en una nueva muestra que parecía lograr en la muestra de desarrollo del modelo. Para ese criterio, se pueden requerir 20 eventos por variable candidata. Además, se puede argumentar que solo se necesitan 96 observaciones para estimar la intersección del modelo con la suficiente precisión como para que el margen de error en las probabilidades predichas sea de ±0,1 con un nivel de confianza de 0,95.
Error y significado del ajuste
Prueba de desviación y razón de verosimilitud: un caso simple
En cualquier procedimiento de ajuste, la adición de otro parámetro de ajuste a un modelo (por ejemplo, los parámetros beta en un modelo de regresión logística) casi siempre mejorará la capacidad del modelo para predecir los resultados medidos. Esto será cierto incluso si el término adicional no tiene valor predictivo, ya que el modelo simplemente estará "sobreajustado" al ruido en los datos. Surge la pregunta de si la mejora obtenida por la adición de otro parámetro de ajuste es lo suficientemente significativa como para recomendar la inclusión del término adicional, o si la mejora es simplemente la que se puede esperar del sobreajuste.
En resumen, para la regresión logística, se define una estadística conocida como desviación, que es una medida del error entre el ajuste del modelo logístico y los datos de resultado. En el límite de un gran número de puntos de datos, la desviación se distribuye chi-cuadrado, lo que permite implementar una prueba de chi-cuadrado para determinar la significación de las variables explicativas.
La regresión lineal y la regresión logística tienen muchas similitudes. Por ejemplo, en simple regresión lineal, un conjunto de K puntos de datos (xk, Sí.k) se ajustan a una función modelo propuesta de la forma Sí.=b0+b1x{displaystyle Y=b_{0}+b_{1}x}. El ajuste se obtiene eligiendo el b parámetros que minimizan la suma de los cuadrados de los residuos (el término de error cuadrado) para cada punto de datos:

- ε ε 2=.. k=1K()b0+b1xk− − Sí.k)2.{displaystyle epsilon ^{2}=sum ¿Por qué?

El valor mínimo que constituye el ajuste será denotado por ε ε ^ ^ 2{displaystyle {hat {epsilon } {2}

Se puede introducir la idea de un modelo nulo, en el que se supone que la variable x no sirve para predecir los resultados de yk: Los puntos de datos se ajustan a una función modelo nula de la forma y=b0 con un término de error al cuadrado:
- ε ε 2=.. k=1K()b0− − Sí.k)2.{displaystyle epsilon ^{2}=sum ¿Qué?

El proceso de fijación consiste en elegir un valor de b0 que minimiza ε ε 2{displaystyle epsilon ^{2} del ajuste al modelo nulo, denotado por ε ε φ φ 2{displaystyle epsilon _{varphi }{2} Donde φ φ {displaystyle varphi } subscript denota el modelo nulo. Se ve que el modelo null es optimizado por b0=Sí.̄ ̄ {displaystyle - Sí. Donde Sí.̄ ̄ {displaystyle {bis}}} es la media del Sí.k valores, y el optimizado ε ε φ φ 2{displaystyle epsilon _{varphi }{2} es:





- ε ε ^ ^ φ φ 2=.. k=1K()Sí.̄ ̄ − − Sí.k)2{displaystyle {hat {epsilon.. ¿Qué? {y}-y_{k} {2}

que es proporcional al cuadrado de la desviación estándar de la muestra (sin corregir) de los puntos de datos yk.
Podemos imaginar un caso en el que los puntos de datos yk se asignan aleatoriamente a los diversos xk, y luego ajustado utilizando el modelo propuesto. Específicamente, podemos considerar los ajustes del modelo propuesto a cada permutación de los resultados yk. Se puede demostrar que el error optimizado de cualquiera de estos ajustes nunca será menor que el error óptimo del modelo nulo, y que la diferencia entre estos errores mínimos seguirá una distribución chi-cuadrado, con grados de libertad iguales a los del modelo nulo. modelo propuesto menos los del modelo nulo que, en este caso, serán 2-1=1. Usando la prueba de chi-cuadrado, podemos estimar cuántos de estos conjuntos permutados de yk producirán un error mínimo menor o igual que el error mínimo usando el original yk, y así podemos estimar qué tan significativa es la mejora que da la inclusión de la variable x en el modelo propuesto.
Para la regresión logística, la medida de bondad de beneficio es la función de probabilidad L, o su logaritmo, la probabilidad de registro l. La función de probabilidad L es análogo al ε ε 2{displaystyle epsilon ^{2} en el caso de regresión lineal, excepto que la probabilidad se maximiza en lugar de minimizar. Denota la probabilidad de registro máxima del modelo propuesto por l l ^ ^ {displaystyle {hat {ell }}.

En el caso de la regresión logística binaria simple, el conjunto de puntos de datos K se ajustan en un sentido probabilístico a una función de la forma:
- p()x)=11+e− − t{displaystyle p(x)={1}{1+e^{-t}}

Donde p()x){displaystyle p(x)} es la probabilidad de que Sí.=1{displaystyle y=1}. Los log-odds son dados por:
- t=β β 0+β β 1x{displaystyle t=beta ¿Qué?
y el log-verosimilitud es:
- l l =.. k=1K()Sí.kIn ()p()xk))+()1− − Sí.k)In ()1− − p()xk))){displaystyle ell =sum _{k=1} {K}left(y_{k}ln(p(x_{k})+(1-y_{k})ln(1-p(x_{k})right)}

Para el modelo nulo, la probabilidad de que Sí.=1{displaystyle y=1} es dado por:
- pφ φ ()x)=11+e− − tφ φ {displaystyle p_{varphi }(x)={frac {1}{1+e^{-t_{varphi }

Las probabilidades logarítmicas para el modelo nulo están dadas por:
- tφ φ =β β 0{displaystyle. ¿Qué?

y el log-verosimilitud es:
- l l φ φ =.. k=1K()Sí.kIn ()pφ φ )+()1− − Sí.k)In ()1− − pφ φ )){displaystyle ell _{varphi }=sum ¿Por qué?

Desde que tenemos pφ φ =Sí.̄ ̄ {displaystyle P_{varphi }={overline {y}} al máximo L, la probabilidad máxima de registro para el modelo null es

- l l ^ ^ φ φ =K()Sí.̄ ̄ In ()Sí.̄ ̄ )+()1− − Sí.̄ ̄ )In ()1− − Sí.̄ ̄ )){fnMicrosoft {fnfnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {fnfnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {f}fnfnMicrosoft {fnMicrosoft {f}f}fnf}fnfnfnfnfn\fnfnfnfnfnfnfnfnfnfn\\fnfnfnfnfnfn\\fnfnfnfnfn\fnfnfnfn\fnfn\fn\\fnfnfn\\\\\\fn\\fn\ {fnMicrosoft Sans Serif})+(1-{overline {y}})})}})}

El óptimo β β 0{displaystyle beta ¿Qué? es:
- β β 0=In ()Sí.̄ ̄ 1− − Sí.̄ ̄ ){displaystyle beta ¿Por qué?

Donde Sí.̄ ̄ {displaystyle {bis}}} es otra vez la media del Sí.k valores. De nuevo, podemos considerar conceptualmente el ajuste del modelo propuesto a cada permutación de la Sí.k y se puede demostrar que la probabilidad máxima de registro de estos ajustes de permutación nunca será más pequeña que la del modelo nulo:
- l l ^ ^ ≥ ≥ l l ^ ^ φ φ {fnMicrosoft Sans Serif} {fnfnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnfn}fnf}fnfnfnfnfnfnfnfnf}fnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnKfnfnfnfnfnfnfnfnfnfnfnfn\fnfnfnfnK}fnfn } {varphi }

Además, como análogo al error del caso de regresión lineal, podemos definir la desviación de un ajuste de regresión logística como:
- D=In ()L^ ^ 2L^ ^ φ φ 2)=2()l l ^ ^ − − l l ^ ^ φ φ ){displaystyle D=ln left({frac {fnK} {fnfn} {fnK}}}}derecha)=2({hat {ell }-{hat {fn}}_ {fnfnfnfn}} {fnfnfn}}} {fnf}}}}} {fnfnf}}}}} {f}}}}}}}}}}}}}}}} {f}}}}}}} {f}}}}}}}}}}}}}} {f}}}} {f}}}}}}}}}}}}}}} {f}}}}}}} {f}}}}}}}} {f}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}

que siempre será positivo o cero. El motivo de esta elección es que la desviación no solo es una buena medida de la bondad del ajuste, sino que también tiene una distribución chi-cuadrada aproximada, y la aproximación mejora a medida que aumenta el número de puntos de datos (K) aumenta, convirtiéndose exactamente en chi-cuadrado distribuido en el límite de un número infinito de puntos de datos. Como en el caso de la regresión lineal, podemos usar este hecho para estimar la probabilidad de que un conjunto aleatorio de puntos de datos proporcione un mejor ajuste que el obtenido por el modelo propuesto, y así estimar cuán significativamente mejora el modelo incluyendo los puntos de datos xk en el modelo propuesto.
Para el modelo simple de puntajes de prueba de estudiantes descritos anteriormente, el valor máximo de la probabilidad de registro del modelo null es l l ^ ^ φ φ =− − 13.8629...{fnMicrosoft {fnfnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {fnfnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {f}fnfnMicrosoft {fnMicrosoft {f}f}fnf}\fnfnfnfnfnfnfnfnfnfnfnfnfnfnfn\\fnfnfnfn\fnfn\\fnfnfnfnfn\fnfnfnfnfnfn\fn\\fn\fnfn\\\\\fn\\fn\. }=-13.8629...} El valor máximo de la probabilidad de registro para el modelo simple es l l ^ ^ =− − 8.02988...{fnMicrosoft {fnfnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {fnfnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {f}fnfnMicrosoft {fnMicrosoft {f}f}fnf}\fnfnfnfnfnfnfnfnfnfnfnfnfnfnfn\\fnfnfnfn\fnfn\\fnfnfnfnfn\fnfnfnfnfnfn\fn\\fn\fnfn\\\\\fn\\fn\ }=-8.02988...} para que la desviación sea D=2()l l ^ ^ − − l l ^ ^ φ φ )=11.6661...{displaystyle D=2({hat {ell }-{hat {ell 11.661...



Utilizando la prueba de significación chi-cuadrado, la integral de la distribución chi-cuadrado con un grado de libertad desde 11,6661... hasta el infinito es igual a 0,00063649...
Esto significa efectivamente que alrededor de 6 de un 10.000 encaja al azar Sí.k se puede esperar que tenga un mejor ajuste (desviance menor) que el dado Sí.k y así podemos concluir que la inclusión de la x variable y datos en el modelo propuesto es una mejora muy significativa sobre el modelo nulo. En otras palabras, rechazamos la hipótesis nula con 1− − D.. 99.94% % {displaystyle 1-Dapprox 99.94%} confianza.

Resumen de bondad de ajuste
La bondad de ajuste en los modelos de regresión lineal generalmente se mide mediante R2. Dado que esto no tiene un análogo directo en la regresión logística, en su lugar se pueden usar varios métodos, incluidos los siguientes.
Pruebas de desviación y razón de verosimilitud
En el análisis de regresión lineal, uno se ocupa de dividir la varianza a través de los cálculos de la suma de los cuadrados: la varianza en el criterio se divide esencialmente en la varianza explicada por los predictores y la varianza residual. En el análisis de regresión logística, la desviación se utiliza en lugar de los cálculos de suma de cuadrados. La desviación es análoga a los cálculos de suma de cuadrados en la regresión lineal y es una medida de la falta de ajuste a los datos en un modelo de regresión logística. Cuando un "saturado" disponible (un modelo con un ajuste teóricamente perfecto), la desviación se calcula comparando un modelo dado con el modelo saturado. Este cálculo da la prueba de razón de verosimilitud:
- D=− − 2In probabilidad del modelo ajustadoprobabilidad del modelo saturado.{displaystyle D=-2ln {text{likelihood of the equipped model}}{text{likelihood of the saturated model}}}}}}

En la ecuación anterior, D representa la desviación e ln representa el logaritmo natural. El logaritmo de esta relación de verosimilitud (la relación entre el modelo ajustado y el modelo saturado) producirá un valor negativo, de ahí la necesidad de un signo negativo. Se puede demostrar que D sigue una distribución aproximada de chi-cuadrado. Los valores más pequeños indican un mejor ajuste ya que el modelo ajustado se desvía menos del modelo saturado. Cuando se evalúan según una distribución de chi-cuadrado, los valores de chi-cuadrado no significativos indican muy poca variación no explicada y, por lo tanto, un buen ajuste del modelo. Por el contrario, un valor significativo de chi-cuadrado indica que una cantidad significativa de la varianza no se explica.
Cuando el modelo saturado no está disponible (un caso común), la desviación se calcula simplemente como −2·(verosimilitud logarítmica del modelo ajustado), y la referencia a la verosimilitud logarítmica del modelo saturado se puede eliminar de todo lo que sigue sin daño.
Dos medidas de desviación son particularmente importantes en la regresión logística: el desvío nulo y la desviación modelo. La desviación nula representa la diferencia entre un modelo con sólo la interceptación (que significa "no predictores") y el modelo saturado. La desviación modelo representa la diferencia entre un modelo con al menos un predictor y el modelo saturado. A este respecto, el modelo nulo proporciona una base de referencia para comparar los modelos predictores. Dado que la desviación es una medida de la diferencia entre un modelo dado y el modelo saturado, los valores más pequeños indican mejor ajuste. Por lo tanto, para evaluar la contribución de un predictor o conjunto de predictores, se puede restar la desviación modelo de la desviación nula y evaluar la diferencia en un χ χ s− − p2,{displaystyle chi ¿Qué? distribución de chi-cuadrón con grados de libertad igual a la diferencia en el número de parámetros estimados.

Dejar
- Dnulo=− − 2In probabilidad de modelo nuloprobabilidad del modelo saturadoDequipada=− − 2In probabilidad de modelo ajustadoprobabilidad del modelo saturado.{displaystyle {begin{aligned}D_{text{null}} {=-2ln {frac {text{likelihood of null model}}}{text{likelihood of the saturated model}}[6pt]D_{text{fitted}}}}} {cccH00}}} {frac {text{likelihood of equipped model}}{text{likelihood of the saturated model}}}end{aligned}}}
![{displaystyle {begin{aligned}D_{text{null}}&=-2ln {frac {text{likelihood of null model}}{text{likelihood of the saturated model}}}\[6pt]D_{text{fitted}}&=-2ln {frac {text{likelihood of fitted model}}{text{likelihood of the saturated model}}}.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d85ab8f60a3e7685815b132b3a80d03d26d9745a)
Entonces la diferencia de ambos es:
- Dnulo− − Dequipada=− − 2()In probabilidad de modelo nuloprobabilidad del modelo saturado− − In probabilidad de modelo ajustadoprobabilidad del modelo saturado)=− − 2In ()probabilidad de modelo nuloprobabilidad del modelo saturado)()probabilidad de modelo ajustadoprobabilidad del modelo saturado)=− − 2In probabilidad del modelo nuloprobabilidad de modelo ajustado.{displaystyle {begin{aligned}D_{text{null}-D_{text{fitted} {begin{aligned}d_{text{null}-d_{text{fitted} {begin{begin{aligned}d_}d_{text{f} {f} {f} {f}f}}f}f}f}}fnf}fnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfnfn {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fn} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif} {fnMicrosoft Sans Serif}
![{displaystyle {begin{aligned}D_{text{null}}-D_{text{fitted}}&=-2left(ln {frac {text{likelihood of null model}}{text{likelihood of the saturated model}}}-ln {frac {text{likelihood of fitted model}}{text{likelihood of the saturated model}}}right)\[6pt]&=-2ln {frac {left({dfrac {text{likelihood of null model}}{text{likelihood of the saturated model}}}right)}{left({dfrac {text{likelihood of fitted model}}{text{likelihood of the saturated model}}}right)}}\[6pt]&=-2ln {frac {text{likelihood of the null model}}{text{likelihood of fitted model}}}.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bd851b7e234a5483dbb21da9fff7d9d2419e3e3e)
Si la desviación del modelo es significativamente menor que la desviación nula, se puede concluir que el predictor o el conjunto de predictores mejoran significativamente el ajuste del modelo. Esto es análogo a la prueba F utilizada en el análisis de regresión lineal para evaluar la importancia de la predicción.
Pseudo-R-cuadrada
(feminine)En la regresión lineal, la correlación múltiple al cuadrado, R2 se utiliza para evaluar la bondad del ajuste ya que representa la proporción de varianza en el criterio que es explicada por los predictores. En el análisis de regresión logística, no existe una medida análoga acordada, pero hay varias medidas en competencia, cada una con limitaciones.
En esta página se examinan cuatro de los índices más utilizados y uno menos utilizado:
- Tasa de probabilidad R2L
- Cox y Snell R2CS
- Nagelkerke R2N
- McFadden R2McF
- Tjur R2T
Prueba de Hosmer-Lemeshow
La prueba Hosmer-Lemeshow utiliza una estadística de prueba que asintóticamente sigue a un χ χ 2{displaystyle chi ^{2} distribución evaluar si las tasas de eventos observadas coinciden con las tasas de eventos previstas en subgrupos de la población modelo. Esta prueba se considera obsoleta por algunos estadísticos debido a su dependencia del atar arbitrario de probabilidades predichas y el bajo poder relativo.

Coeficiente de importancia
Después de ajustar el modelo, es probable que los investigadores quieran examinar la contribución de los predictores individuales. Para hacerlo, querrán examinar los coeficientes de regresión. En la regresión lineal, los coeficientes de regresión representan el cambio en el criterio para cada unidad de cambio en el predictor. Sin embargo, en la regresión logística, los coeficientes de regresión representan el cambio en el logit para cada unidad de cambio en el predictor. Dado que el logit no es intuitivo, es probable que los investigadores se concentren en el efecto de un predictor sobre la función exponencial del coeficiente de regresión: la razón de probabilidades (ver definición). En la regresión lineal, la importancia de un coeficiente de regresión se evalúa calculando una prueba t. En la regresión logística, hay varias pruebas diferentes diseñadas para evaluar la importancia de un predictor individual, más notablemente la prueba de razón de verosimilitud y la estadística de Wald.
Prueba de razón de verosimilitud
La prueba de razón de verosimilitud analizada anteriormente para evaluar el ajuste del modelo también es el procedimiento recomendado para evaluar la contribución de los "predictores" a un modelo dado. En el caso de un modelo predictor único, uno simplemente compara la desviación del modelo predictor con la del modelo nulo en una distribución chi-cuadrado con un solo grado de libertad. Si el modelo predictor tiene una desviación significativamente menor (cf. chi-cuadrado usando la diferencia en grados de libertad de los dos modelos), entonces se puede concluir que existe una asociación significativa entre el "predictor" y el resultado Aunque algunos paquetes estadísticos comunes (por ejemplo, SPSS) proporcionan estadísticas de prueba de razón de verosimilitud, sin esta prueba computacionalmente intensiva sería más difícil evaluar la contribución de los predictores individuales en el caso de regresión logística múltiple. Para evaluar la contribución de los predictores individuales, se pueden ingresar los predictores jerárquicamente, comparando cada nuevo modelo con el anterior para determinar la contribución de cada predictor. Existe cierto debate entre los estadísticos sobre la idoneidad de los llamados "paso a paso" procedimientos. El temor es que no conserven las propiedades estadísticas nominales y se vuelvan engañosas.
Estadística de Wald
Alternativamente, al evaluar la contribución de predictores individuales en un modelo determinado, se puede examinar la importancia de la estadística de Wald. La estadística de Wald, análoga a la prueba t en la regresión lineal, se utiliza para evaluar la importancia de los coeficientes. La estadística de Wald es la relación entre el cuadrado del coeficiente de regresión y el cuadrado del error estándar del coeficiente y se distribuye asintóticamente como una distribución de chi-cuadrado.
- Wj=β β j2SEβ β j2{displaystyle W_{j}={frac {beta ¿Qué? - Sí.

Aunque varios paquetes estadísticos (por ejemplo, SPSS, SAS) informan la estadística de Wald para evaluar la contribución de predictores individuales, la estadística de Wald tiene limitaciones. Cuando el coeficiente de regresión es grande, el error estándar del coeficiente de regresión también tiende a ser mayor, lo que aumenta la probabilidad de error de tipo II. La estadística de Wald también tiende a estar sesgada cuando los datos son escasos.
Muestreo de casos y controles
Supongamos que los casos son raros. Entonces podríamos desear muestrearlos con más frecuencia que su prevalencia en la población. Por ejemplo, supongamos que hay una enfermedad que afecta a 1 persona de cada 10.000 y para recopilar nuestros datos necesitamos hacer un examen físico completo. Puede ser demasiado costoso hacer miles de exámenes físicos de personas sanas para obtener datos de solo unas pocas personas enfermas. Por lo tanto, podemos evaluar más individuos enfermos, quizás todos los resultados raros. Esto también es un muestreo retrospectivo o, de manera equivalente, se denomina datos no balanceados. Como regla general, el muestreo de controles a una tasa de cinco veces el número de casos producirá suficientes datos de control.
La regresión logística es única porque se puede estimar en datos desequilibrados, en lugar de datos de muestreo aleatorio, y aún así producir cálculos coeficientes correctos de los efectos de cada variable independiente en el resultado. Es decir, si formamos un modelo logístico de tales datos, si el modelo es correcto en la población general, el β β j{displaystyle beta _{j}} todos los parámetros son correctos excepto β β 0{displaystyle beta ¿Qué?. Podemos corregir β β 0{displaystyle beta ¿Qué? si conocemos la verdadera prevalencia como sigue:
- β β ^ ^ 0Alternativa Alternativa =β β ^ ^ 0+log π π 1− − π π − − log π π ~ ~ 1− − π π ~ ~ {displaystyle {widehat {beta {fnMicrosoft Sans {fnMicrosoft Sans Serif} }_{0}+log {frac {pi} }{1-pi }- 'log {{tilde {pi} over {1-{tilde {pi }

Donde π π {displaystyle pi} es la verdadera prevalencia y π π ~ ~ {displaystyle {fnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {\fnMicrosoft {fnMicrosoft {fnMicrosoft {\fnMicrosoft {\fnMicrosoft {fnMicrosoft {\\\\\fnMicrosoft {\fnMicrosoft {fnMicrosoft {\fnMicrosoft {fnMicrosoft {\\fnMicrosoft {\\\\\\\\\\\\\\\\\\\\\\\fnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {\\\\\\\\\\\\\\\ } es la prevalencia en la muestra.


Discusión
Al igual que otras formas de análisis de regresión, la regresión logística utiliza una o más variables predictoras que pueden ser continuas o categóricas. Sin embargo, a diferencia de la regresión lineal ordinaria, la regresión logística se usa para predecir variables dependientes que pertenecen a una de un número limitado de categorías (tratando la variable dependiente en el caso binomial como el resultado de un ensayo de Bernoulli) en lugar de un resultado continuo. Dada esta diferencia, se violan los supuestos de la regresión lineal. En particular, los residuos no pueden distribuirse normalmente. Además, la regresión lineal puede hacer predicciones sin sentido para una variable dependiente binaria. Lo que se necesita es una forma de convertir una variable binaria en una variable continua que pueda tomar cualquier valor real (negativo o positivo). Para hacer eso, la regresión logística binomial primero calcula las probabilidades de que ocurra el evento para diferentes niveles de cada variable independiente y luego toma su logaritmo para crear un criterio continuo como una versión transformada de la variable dependiente. El logaritmo de las probabilidades es el logit de la probabilidad, el logit se define de la siguiente manera:
Aunque la variable dependiente en la regresión logística es Bernoulli, el logit está en una escala sin restricciones. La función logit es la función de enlace en este tipo de modelo lineal generalizado, es decir

Y es la variable de respuesta distribuida por Bernoulli y x es la variable predictora; los valores β son los parámetros lineales.
El logit de la probabilidad de éxito se ajusta a los predictores. El valor pronosticado del logit se vuelve a convertir en probabilidades pronosticadas, a través del inverso del logaritmo natural: la función exponencial. Por lo tanto, aunque la variable dependiente observada en la regresión logística binaria es una variable 0 o 1, la regresión logística estima las probabilidades, como variable continua, de que la variable dependiente sea un "éxito". En algunas aplicaciones, las probabilidades son todo lo que se necesita. En otros, se necesita una predicción específica de sí o no para saber si la variable dependiente es o no un 'éxito'; esta predicción categórica se puede basar en las probabilidades de éxito calculadas, y las probabilidades pronosticadas por encima de algún valor de corte elegido se traducen en una predicción de éxito.
Máxima entropía
De todas las formas funcionales utilizadas para estimar las probabilidades de un resultado categórico particular que optimizan el ajuste al maximizar la función de verosimilitud (p. ej., regresión probit, regresión de Poisson, etc.), la solución de regresión logística es única porque es una Solución de máxima entropía. Este es un caso de una propiedad general: una familia exponencial de distribuciones maximiza la entropía, dado un valor esperado. En el caso del modelo logístico, la función logística es el parámetro natural de la distribución de Bernoulli (está en "forma canónica", y la función logística es la función de enlace canónica), mientras que otras funciones sigmoideas no lo son. -funciones de enlace canónico; esto subyace a su elegancia matemática y facilidad de optimización. Consulte Familia exponencial § Derivación de entropía máxima para obtener más detalles.
Prueba
Para mostrar esto, usamos el método de los multiplicadores de Lagrange. El Lagrangiano es igual a la entropía más la suma de los productos de los multiplicadores de Lagrange por varias expresiones de restricción. Se considerará el caso multinomial general, ya que la demostración no se simplifica mucho al considerar casos más simples. Igualando la derivada del Lagrangiano con respecto a las diversas probabilidades a cero, se obtiene una forma funcional para esas probabilidades que corresponde a las utilizadas en la regresión logística.
Como en la sección anterior sobre regresión logística multinomial, consideraremos M+1{displaystyle M+1} variables explicativas denotadas xm{displaystyle x_{m} y que incluyen x0=1{displaystyle x_{0}=1}. Habrá un total de K puntos de datos, indexados por k={}1,2,...... ,K}{displaystyle k={1,2,dotsK}}, y los puntos de datos son dados por xmk{displaystyle x_{mk} y Sí.k{displaystyle y_{k}. El xmk también estará representado como ()M+1){displaystyle (M+1)}-dimensional vector xk={}x0k,x1k,...... ,xMk}{displaystyle {boldsymbol {x}={x_{0k},x_{1k},dotsx_{Mk}}. Habrá N+1{displaystyle N+1} valores posibles de la variable categórica Sí. desde 0 a N.




Vamos pn()x) ser la probabilidad, dado vector variable explicativo x, que el resultado será Sí.=n{displaystyle y=n}. Define pnk=pn()xk){displaystyle ¿Qué? que es la probabilidad de que k-a medida, el resultado categórico es n.


El Lagrangiano se expresará en función de las probabilidades pnk y se minimizará igualando a cero las derivadas del Lagrangiano con respecto a estas probabilidades. Un punto importante es que las probabilidades se tratan por igual y el hecho de que sumen la unidad es parte de la formulación lagrangiana, en lugar de asumirse desde el principio.
La primera contribución al Lagrangiano es la entropía:
- Lent=− − .. k=1K.. n=0NpnkIn ()pnk){displaystyle {mathcal {}_{ent}=-sum ¿Qué? ¿Qué?

La probabilidad logarítmica es:
- l l =.. k=1K.. n=0NΔ Δ ()n,Sí.k)In ()pnk){displaystyle ell =sum ¿Qué? ¿Por qué?

Asumiendo la función logística multinomial, se encontró que la derivada del log-verosimilitud con respecto a los coeficientes beta es:
- ∂ ∂ l l ∂ ∂ β β nm=.. k=1K()pnkxmk− − Δ Δ ()n,Sí.k)xmk){displaystyle {frac {partial ell }{partial beta ¿Qué? ¿Qué? Delta (n,y_{k})x_{mk})}

Un punto muy importante aquí es que esta expresión (notablemente) no es una función explícita de los coeficientes beta. Es solo una función de las probabilidades pnk y los datos. En lugar de ser específico para el supuesto caso logístico multinomial, se toma como una declaración general de la condición en la que se maximiza la probabilidad logarítmica y no hace referencia a la forma funcional de pnk. Hay entonces (M+1)(N+1) restricciones de ajuste y el término de restricción de ajuste en el Lagrangiano es entonces:
- Lfit=.. n=0N.. m=0Mλ λ nm.. k=1K()pnkxmk− − Δ Δ ()n,Sí.k)xmk){displaystyle {fnMitcal {fnK}} {fnMicrosoft}=fnMicrosoft} ¿Qué? ################################################################################################################################################################################################################################################################ ¿Qué? ¿Qué? Delta (n,y_{k})x_{mk})}

donde λnm son los multiplicadores de Lagrange apropiados. Hay restricciones de normalización K que se pueden escribir:
- .. n=0Npnk=1{displaystyle sum _{n=0}{N}p_{nk}=1}

para que el término de normalización en el Lagrangiano sea:
- Lnorm=.. k=1Kα α k()1− − .. n=1Npnk){fnMicrosoft Sans Serif} ### {k=1} {K}alpha ¿Qué? ¿Por qué?

donde αk son los multiplicadores de Lagrange apropiados. El Lagrangiano es entonces la suma de los tres términos anteriores:
- L=Lent+Lfit+Lnorm{displaystyle {fnMitcal}={fnMitcal {L}_{ent}+{ mathcal {fnK} {fnMitcal {fnh}}

Al establecer la derivada del Lagrangiano con respecto a una de las probabilidades a cero, se obtiene:
- ∂ ∂ L∂ ∂ pn.k.=0=− − In ()pn.k.)− − 1+.. m=0M()λ λ n.mxmk.)− − α α k.{fnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {fnMicrosoft {\fnMicrosoft} {fnMitcal {} {fnMitcal}} {fnMitcal} {fnh}} {fnMitcal} {f}}}} {fnMitcal}}}} {fnMitcal {f}}}} {f}}}}} {b}}}}}} {b}}}}}}}}}}}}}} { P_{n'k '}=0=-ln(p_{n'k)-1+sum ¿Por qué? ¿Qué?

Usando la notación vectorial más condensada:
- .. m=0Mλ λ nmxmk=λ λ n⋅ ⋅ xk{displaystyle sum ################################################################################################################################################################################################################################################################ # {nm}x_{mk}={boldsymbol {fnMicrode }_{n}cdot {boldsymbol {x}_{k}

y dejar caer los mejores en el n y k índices, y luego resolver para pnk{displaystyle P_{nk} rendimientos:

- pnk=eλ λ n⋅ ⋅ xk/Zk{displaystyle ¿Qué? {fnMicrode }_{n}cdot {boldsymbol {x}_{k}/Z_{k}

donde:
- Zk=e1+α α k{displaystyle Z_{k}=e^{1+alpha ¿Qué?

Imponiendo la restricción de normalización, podemos resolver para Zk y escribir las probabilidades como:
- pnk=eλ λ n⋅ ⋅ xk.. u=0Neλ λ u⋅ ⋅ xk{displaystyle ¿Qué? {fnMicrode }_{n}cdot {boldsymbol {fnK}} {fnK}} {fnK}}} {fnK}}} {f}} {fn}}} {fn}}} {fnK}}}}}}}}} {fn}}}} {f}}} {f}}}}}}}} {f}}}}}}}}}}}}}}}} {f}} {f}}}}}}}}}}}}} {f}}}}}}}}}}}} {f}}}}}}}}}}}} {f}}}}}}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}} {f}}}}}}}}}}}} {f}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}} { ¿Qué? {fnMicrode ♪♪♪♪♪ {fnK}}}

El λ λ n{displaystyle {boldsymbol {lambda ♪♪ no todos son independientes. Podemos añadir cualquier constante ()M+1){displaystyle (M+1)}- vector dimensional a cada uno de los λ λ n{displaystyle {boldsymbol {lambda ♪♪ sin cambiar el valor del pnk{displaystyle P_{nk} probabilidades de que sólo haya N en lugar de N+1{displaystyle N+1} independiente λ λ n{displaystyle {boldsymbol {lambda ♪♪. En la sección de regresión logística multinomial anterior, la λ λ 0{displaystyle {boldsymbol {lambda } fue restringida de cada λ λ n{displaystyle {boldsymbol {lambda ♪♪ que establece el término exponencial λ λ 0{displaystyle {boldsymbol {lambda } a la unidad, y los coeficientes beta fueron dados por β β n=λ λ n− − λ λ 0{displaystyle {boldsymbol {beta ♪♪♪ {n}={boldsymbol {fnMicrode }_{n}-{boldsymbol {fnMicrode }.



Otros enfoques
En las aplicaciones de aprendizaje automático donde se usa la regresión logística para la clasificación binaria, el MLE minimiza la función de pérdida de entropía cruzada.
La regresión logística es un importante algoritmo de aprendizaje automático. El objetivo es modelar la probabilidad de una variable aleatoria Y{displaystyle Sí. ser 0 o 1 da datos experimentales.
Considere una función modelo lineal generalizada parametrizada por Silencio Silencio {displaystyle theta },

- hSilencio Silencio ()X)=11+e− − Silencio Silencio TX=Pr()Y=1▪ ▪ X;Silencio Silencio ){displaystyle h_{theta }(X)={frac {1}{1+e^{-theta ^{T}X}}=Pr(Y=1mid X;theta)}

Por lo tanto,
- Pr()Y=0▪ ▪ X;Silencio Silencio )=1− − hSilencio Silencio ()X){displaystyle Pr(Y=0mid X;theta)=1-h_{theta }(X)}

y desde Y▪ ▪ {}0,1}{displaystyle Yin {0,1}, vemos que Pr()Sí.▪ ▪ X;Silencio Silencio ){displaystyle Pr(ymid X;theta)} es dado por Pr()Sí.▪ ▪ X;Silencio Silencio )=hSilencio Silencio ()X)Sí.()1− − hSilencio Silencio ()X))()1− − Sí.).{displaystyle Pr(ymid X;theta)=h_{theta }(X)^{y}(1-h_{theta }(X)}{(1-y)}.} Ahora calculamos la función de probabilidad asumiendo que todas las observaciones de la muestra están distribuidas de forma independiente Bernoulli,



- L()Silencio Silencio ▪ ▪ Sí.;x)=Pr()Y▪ ▪ X;Silencio Silencio )=∏ ∏ iPr()Sí.i▪ ▪ xi;Silencio Silencio )=∏ ∏ ihSilencio Silencio ()xi)Sí.i()1− − hSilencio Silencio ()xi))()1− − Sí.i){displaystyle {begin{aligned}L(theta mid y;x) reducida=Pr(Ymid X;theta)\\fnunció=prod ¿Por qué? x_{i};theta)\ ¿Por qué?

Normalmente, la probabilidad de registro se maximiza,
- N− − 1log L()Silencio Silencio ▪ ▪ Sí.;x)=N− − 1.. i=1Nlog Pr()Sí.i▪ ▪ xi;Silencio Silencio ){displaystyle N^{-1}log L(theta mid y;x)=N^{-1}sum ¿Por qué?

que se maximiza mediante técnicas de optimización como el descenso de gradiente.
Asumiendo el ()x,Sí.){displaystyle (x,y)} los pares se dibujan uniformemente de la distribución subyacente, luego en el límite de grandeN,

- limN→ → +JUEGO JUEGO N− − 1.. i=1Nlog Pr()Sí.i▪ ▪ xi;Silencio Silencio )=.. x▪ ▪ X.. Sí.▪ ▪ YPr()X=x,Y=Sí.)log Pr()Y=Sí.▪ ▪ X=x;Silencio Silencio )=.. x▪ ▪ X.. Sí.▪ ▪ YPr()X=x,Y=Sí.)()− − log Pr()Y=Sí.▪ ▪ X=x)Pr()Y=Sí.▪ ▪ X=x;Silencio Silencio )+log Pr()Y=Sí.▪ ▪ X=x))=− − DKL()Y∥ ∥ YSilencio Silencio )− − H()Y▪ ▪ X){displaystyle {begin{aligned} golpelim limits _{Nrightarrow +infty }N^{-1}sum _{i=1} {N}log Pr(y_{i}mid x_{i};theta)=sum _{xin {mathcal {X}}sum _{yin {fnMithcal} {Y}}Pr(X=x,Y=y)log Pr(Y=ymid X=x;theta)\[6pt]={} limitsum _{xin {mathcal {X}}sum _{yin {fnMithcal} {Y}}Pr(X=x,Y=y)left(-log {frac {Pr(Y=ymid X=x)}{pr(Y=ymid X=x;theta)}+log Pr(Y=ymid X=x)right)[6pt]={y}{y}{y}} {}}}}} {f}}}}}}}}}}}}}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}f}fn
![{displaystyle {begin{aligned}&lim limits _{Nrightarrow +infty }N^{-1}sum _{i=1}^{N}log Pr(y_{i}mid x_{i};theta)=sum _{xin {mathcal {X}}}sum _{yin {mathcal {Y}}}Pr(X=x,Y=y)log Pr(Y=ymid X=x;theta)\[6pt]={}&sum _{xin {mathcal {X}}}sum _{yin {mathcal {Y}}}Pr(X=x,Y=y)left(-log {frac {Pr(Y=ymid X=x)}{Pr(Y=ymid X=x;theta)}}+log Pr(Y=ymid X=x)right)\[6pt]={}&-D_{text{KL}}(Yparallel Y_{theta })-H(Ymid X)end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9b300972d40831096c1ab7bdf34338a71eca96d9)
Donde H()Y▪ ▪ X){displaystyle H(Ymid X)} es la entropía condicional y DKL{displaystyle D_{text{KL}} es la divergencia Kullback-Leibler. Esto conduce a la intuición de que al maximizar la probabilidad de registro de un modelo, usted está minimizando la divergencia KL de su modelo de la distribución de entropía máxima. Intuitivamente buscando el modelo que hace las pocas suposiciones en sus parámetros.


Comparación con regresión lineal
La regresión logística se puede ver como un caso especial del modelo lineal generalizado y por lo tanto análogo a la regresión lineal. El modelo de regresión logística, sin embargo, se basa en hipótesis muy diferentes (sobre la relación entre las variables dependientes e independientes) de las de regresión lineal. En particular, las diferencias clave entre estos dos modelos se pueden ver en las siguientes dos características de regresión logística. Primero, la distribución condicional Sí.▪ ▪ x{displaystyle ymid x} es una distribución Bernoulli en lugar de una distribución Gaussiana, porque la variable dependiente es binaria. En segundo lugar, los valores predicho son probabilidades y se limitan a (0,1) a través de la función de distribución logística porque la regresión logística predice probabilidad de resultados particulares en lugar de los mismos resultados.

Alternativas
Una alternativa común al modelo logístico (modelo logit) es el modelo probit, como sugieren los nombres relacionados. Desde la perspectiva de los modelos lineales generalizados, estos difieren en la elección de la función de enlace: el modelo logístico usa la función logit (función logística inversa), mientras que el modelo probit usa la función probit (función de error inversa). De manera equivalente, en las interpretaciones de variables latentes de estos dos métodos, el primero asume una distribución logística estándar de errores y el segundo una distribución normal estándar de errores. En su lugar, se pueden utilizar otras funciones sigmoideas o distribuciones de error.
La regresión logística es una alternativa al método de Fisher de 1936, el análisis discriminante lineal. Si se cumplen los supuestos del análisis discriminante lineal, el condicionamiento se puede revertir para producir una regresión logística. Sin embargo, lo contrario no es cierto porque la regresión logística no requiere el supuesto normal multivariado del análisis discriminante.
La suposición de los efectos del predictor lineal se puede relajar fácilmente mediante técnicas como las funciones spline.
Historia
Cramer (2002) proporciona una historia detallada de la regresión logística. La función logística se desarrolló como un modelo de crecimiento de la población y se denominó "logística" por Pierre François Verhulst en las décadas de 1830 y 1840, bajo la dirección de Adolphe Quetelet; consulte Función logística § Historial para obtener más detalles. En su primer artículo (1838), Verhulst no especificó cómo ajustaba las curvas a los datos. En su artículo más detallado (1845), Verhulst determinó los tres parámetros del modelo haciendo que la curva pasara por tres puntos observados, lo que arrojó malas predicciones.
La función logística se desarrolló de forma independiente en química como modelo de autocatálisis (Wilhelm Ostwald, 1883). Una reacción autocatalítica es aquella en la que uno de los productos es en sí mismo un catalizador para la misma reacción, mientras que el suministro de uno de los reactivos es fijo. Naturalmente, esto da lugar a la ecuación logística por la misma razón que el crecimiento de la población: la reacción se refuerza a sí misma pero está restringida.
La función logística fue redescubierta de forma independiente como modelo de crecimiento de la población en 1920 por Raymond Pearl y Lowell Reed, publicado como Pearl & Reed (1920), lo que condujo a su uso en las estadísticas modernas. Inicialmente desconocían el trabajo de Verhulst y presumiblemente lo aprendieron de L. Gustave du Pasquier, pero le dieron poco crédito y no adoptaron su terminología. Se reconoció la prioridad de Verhulst y el término "logística" revivido por Udny Yule en 1925 y ha sido seguido desde entonces. Pearl y Reed primero aplicaron el modelo a la población de los Estados Unidos y también inicialmente ajustaron la curva haciéndola pasar por tres puntos; al igual que con Verhulst, esto nuevamente arrojó malos resultados.
En la década de 1930, el modelo probit fue desarrollado y sistematizado por Chester Ittner Bliss, quien acuñó el término "probit" en Bliss (1934) harvtxt error: no target: CITEREFBliss1934 (ayuda), y por John Gaddum en Gaddum (1933) harvtxt error: no target: CITEREFGaddum1933 (ayuda), y el modelo se ajusta al máximo estimación de probabilidad por Ronald A. Fisher en Fisher (1935) harvtxt error: no target: CITEREFFisher1935 (ayuda), como una adición al trabajo de Bliss. El modelo probit se utilizó principalmente en bioensayos y había sido precedido por trabajos anteriores que datan de 1860; ver Modelo Probit § Historia. El modelo probit influyó en el desarrollo posterior del modelo logit y estos modelos competían entre sí.
Es probable que Edwin Bidwell Wilson y su alumna Jane Worcester utilizaran por primera vez el modelo logístico como alternativa al modelo probit en bioensayos en Wilson & Worcester (1943). Sin embargo, el desarrollo del modelo logístico como una alternativa general al modelo probit se debió principalmente al trabajo de Joseph Berkson durante muchas décadas, comenzando con Berkson (1944), donde acuñó "logit", por analogía con "probit", y continuando con Berkson (1951) harvtxt error: no target: CITEREFBerkson1951 (ayuda) y los años siguientes. El modelo logit se descartó inicialmente como inferior al modelo probit, pero "gradualmente logró un equilibrio con el logit", particularmente entre 1960 y 1970. En 1970, el modelo logit logró la paridad con el modelo probit en uso. en las revistas de estadística y, a partir de entonces, lo superó. Esta relativa popularidad se debió a la adopción del logit fuera del bioensayo, en lugar de desplazar al probit dentro del bioensayo, y su uso informal en la práctica; La popularidad del modelo logit se atribuye a la simplicidad computacional, las propiedades matemáticas y la generalidad del modelo logit, lo que permite su uso en diversos campos.
Durante ese tiempo se produjeron varios refinamientos, especialmente por parte de David Cox, como en Cox (1958).
El modelo logit multinomial se introdujo de forma independiente en Cox (1966) y Theil (1969), lo que aumentó considerablemente el ámbito de aplicación y la popularidad del modelo logit. En 1973, Daniel McFadden vinculó el logit multinomial con la teoría de la elección discreta, específicamente el axioma de elección de Luce, mostrando que el logit multinomial se derivaba del supuesto de independencia de las alternativas irrelevantes e interpretando las probabilidades de las alternativas como preferencias relativas; esto dio una base teórica para la regresión logística.
Extensiones
Hay un gran número de extensiones:
- regresión logística multinomial (o logit multinomial) maneja el caso de una variable dependiente multi-way (con valores no ordenados, también llamada "clasificación"). Tenga en cuenta que el caso general de tener variables dependientes con más de dos valores se denomina regresión politópica.
- Regresión logística ordenada (o logit ordenado) maneja variables dependientes ordinal (valores ordenados).
- logit mixto es una extensión de logit multinomial que permite correlaciones entre las opciones de la variable dependiente.
- Una extensión del modelo logístico a conjuntos de variables interdependientes es el campo aleatorio condicional.
- Los mangos de regresión logística condicional coinciden o estratifican datos cuando los estratos son pequeños. Se utiliza principalmente en el análisis de estudios observacionales.
Software
La mayoría del software estadístico puede realizar una regresión logística binaria.
- SPSS
- [1] para regresión logística básica.
- Stata
- SAS
- PROC LOGISTIC para la regresión logística básica.
- PROC CATMOD cuando todas las variables son categóricas.
- PROC GLIMMIX para regresión logística modelo multinivel.
- R
- glm en el paquete de estadísticas (usando familia = binomial)
lrmen el paquete rms- Paquete GLMNET para una regresión logística regularizada de aplicación eficiente
- Imer para la regresión logística de efectos mixtos
- Comando de paquete Rfast
gm_logisticpara cálculos rápidos y pesados con datos de gran escala. - paquete de brazo para regresión logística bayesiana
- Python
- Inicia sesión en el módulo Statsmodels.
- LogisticRegression in the scikit-learn module.
- LogisticRegressor en el módulo TensorFlow.
- Ejemplo completo de regresión logística en el tutorial Theano [2]
- Regresión logística bayesiana con código anterior ARD, tutorial
- Regreso Logístico de Bahías Variacionales con tutorial de código ARD
- Bayesian Logistic Regression code, tutorial
- NCSS
- Regresión logística en NCSS
- Matlab
mnrfiten la Caja de Herramientas de Aprendizaje de Estadísticas y Máquinas (con "incorrecto" codificado como 2 en lugar de 0)fminunc/fmincon, fitglm, mnrfit, fitclinear, mletodos pueden hacer regresión logística.
- Java (JVM)
- LibLinear
- Apache Flink
- Apache Spark
- SparkML apoya la regresión logística
- FPGA
- Logistic Regresesion IP core en HLS para FPGA.
Notablemente, el paquete de extensión de estadísticas de Microsoft Excel no lo incluye.