
Puntuación
Puntuación (o, a veces, interpunción) es el uso de espacios, signos convencionales (llamados signos de puntuación) y ciertos dispositivos tipográficos como ayuda a la comprensión y lectura correcta del texto escrito, ya sea leído en silencio o en voz alta. Otra descripción es: "Es la práctica, acción o sistema de insertar puntos u otras marcas pequeñas en los textos para ayudar a la interpretación; división del texto en oraciones, cláusulas, etc., por medio de dichas marcas."
En inglés escrito, la puntuación es fundamental para eliminar la ambigüedad del significado de las oraciones. Por ejemplo: "la mujer, sin su hombre, no es nada" (enfatizando la importancia del hombre para la mujer), y "mujer: sin ella, el hombre no es nada" (enfatizando la importancia de las mujeres para los hombres) tienen significados muy diferentes; al igual que "come brotes y hojas" (lo que significa que el sujeto consume crecimientos de plantas) y "come, dispara y deja" (lo que significa que el sujeto come primero, luego dispara un arma y luego abandona la escena). Las marcadas diferencias de significado se producen por las simples diferencias de puntuación dentro de los pares de ejemplo, especialmente el último.
Las reglas de puntuación varían según el idioma, la ubicación, el registro y la hora, y están en constante evolución. Ciertos aspectos de la puntuación son estilísticos y, por lo tanto, son elección del autor (o del editor), o formas de lenguaje taquigráfico (taquigrafía), como las que se usan en chats en línea y mensajes de texto.
Historia
Los primeros sistemas de escritura eran logográficos o silábicos; por ejemplo, escritura china y maya, que no necesariamente requieren puntuación, especialmente espaciado. Esto se debe a que todo el morfema o la palabra generalmente se agrupa en un solo glifo, por lo que el espaciado no ayuda mucho a distinguir dónde termina una palabra y dónde comienza la otra. La desambiguación y el énfasis se pueden comunicar fácilmente sin puntuación mediante el empleo de una forma escrita separada distinta de la forma hablada del idioma que utiliza una fraseología ligeramente diferente. Incluso hoy en día, el inglés escrito difiere sutilmente del inglés hablado porque no es posible transmitir todo el énfasis y la desambiguación en forma impresa, incluso con puntuación.
Los textos clásicos chinos antiguos se transmitían sin puntuación. Sin embargo, muchos textos de bambú del período de los Reinos Combatientes contienen los símbolos ⟨└⟩ y ⟨▄⟩ que indican el final de un capítulo y el punto final, respectivamente. Durante la dinastía Song, la adición de puntuación a los textos por parte de los eruditos para ayudar a la comprensión se volvió común.
La escritura alfabética más antigua (fenicia, hebrea y otras de la misma familia) no tenía mayúsculas, espacios, vocales (ver abjad) y pocos signos de puntuación. Esto funcionó siempre que el tema se restringiera a una gama limitada de temas (por ejemplo, la escritura utilizada para registrar transacciones comerciales). La puntuación es históricamente una ayuda para leer en voz alta.
El documento más antiguo conocido que usa puntuación es la Mesha Stele (siglo IX a. C.). Esto emplea puntos entre las palabras y trazos horizontales entre la sección de sentido como puntuación.
Antigüedad occidental
La mayoría de los textos todavía estaban escritos en scriptura continua, es decir, sin separación entre palabras. Sin embargo, los griegos usaban esporádicamente signos de puntuación que consistían en puntos dispuestos verticalmente, generalmente dos (dicolon) o tres (tricolon), alrededor del siglo V a. C. como ayuda en la entrega oral de textos. Los dramaturgos griegos como Eurípides y Aristófanes usaron símbolos para distinguir los finales de las frases en el drama escrito: esto ayudó esencialmente al elenco de la obra a saber cuándo hacer una pausa. Después del 200 a. C., los griegos utilizaron el sistema de Aristófanes de Bizancio (llamado théseis) de un solo punto (punctus) colocado a diferentes alturas para marcar hasta discursos en divisiones retóricas:
- hipostigma - un bajo punctus sobre la base para marcar una komma (Unidad menor que una cláusula);
- stigmḕ mésē – a punctus a media hora para marcar una cláusula (kōlon); y
- stigmḕ teleía - un alto punctus para marcar una sentencia (periodos).
Además, los griegos usaban los párrafos (o gamma) para marcar el comienzo de las oraciones, los diples marginales para marcar las citas y un koronis para indicar el final de las secciones principales.
Los romanos (c. siglo I a. C.) también usaban ocasionalmente símbolos para indicar pausas, pero el griego théseis—bajo el nombre distinctiones— prevaleció en el siglo IV dC según lo informado por Aelius Donatus e Isidoro de Sevilla (siglo VII). Además, los textos a veces se presentaban per capitula, donde cada oración tenía su propia línea separada. Se utilizaron diples, pero en el período tardío estos a menudo degeneraron en marcas en forma de coma.
En la página, la puntuación realiza su función gramática, pero en la mente del lector hace más que eso. Le dice al lector cómo humedecer la melodía.
Lynn Truss, Come, Dispara y Hojas.
Medieval
La puntuación se desarrolló dramáticamente cuando comenzaron a producirse grandes cantidades de copias de la Biblia. Estos fueron diseñados para leerse en voz alta, por lo que los copistas comenzaron a introducir una variedad de marcas para ayudar al lector, incluida la sangría, varios signos de puntuación (diple, paragraphos, ductus simple), y una versión temprana de mayúsculas iniciales (litterae notabiliores). Jerome y sus colegas, que hicieron una traducción de la Biblia al latín, la Vulgata (c. AD 400), empleó un sistema de diseño basado en prácticas establecidas para enseñar los discursos de Demóstenes y Cicerón. Bajo su diseño per cola et commata, cada unidad de sentido estaba sangrada y tenía su propia línea. Este diseño se usó únicamente para manuscritos bíblicos durante los siglos V al IX, pero se abandonó en favor de la puntuación.
En los siglos VII y VIII, los escribas irlandeses y anglosajones, cuyos idiomas nativos no se derivaban del latín, agregaron más señales visuales para hacer que los textos fueran más inteligibles. Los escribas irlandeses introdujeron la práctica de la separación de palabras. Del mismo modo, los escribas insulares adoptaron el sistema distinctiones mientras lo adaptaban para escritura minúscula (así para que sea más prominente) utilizando no una altura diferente, sino un número diferente de marcas, alineadas horizontalmente (o, a veces, triangularmente), para indicar el valor de una pausa: una marca para una pausa menor, dos para una mediana, y tres para un mayor. Los más comunes fueron el punctus, una marca en forma de coma y una marca en forma de 7 (coma positura), a menudo se usa en combinación. Las mismas marcas podrían usarse en el margen para marcar las citas.
A finales del siglo VIII, surgió un sistema diferente en Francia bajo la dinastía carolingia. Indicando originalmente cómo se debe modular la voz al cantar la liturgia, el positurae migró a cualquier texto destinado a ser leído en voz alta, y luego a todos los manuscritos. Positurae llegó a Inglaterra por primera vez a fines del siglo X, probablemente durante el movimiento de reforma benedictina, pero no se adoptó hasta después la conquista normanda. Las positurae eran las punctus, punctus elevatus, punctus versus y punctus interrogativus, pero un quinto símbolo, el punctus flexus, se añadió en el siglo X para indicar una pausa de un valor entre punctus y punctus elevatus. A finales del siglo XI y principios del siglo XII, el punctus versus desapareció y fue absorbido por el simple punctus (ahora con dos valores distintos).
La Baja Edad Media vio la adición de la virgula suspensiva (barra o barra con un punto medio) que a menudo se usaba junto con el punctus para diferentes tipos de pausas. Las citas directas estaban marcadas con diples marginales, como en la Antigüedad, pero desde al menos el siglo XII los escribas también comenzaron a ingresar diples (a veces dobles) dentro de la columna de texto.
Era de la imprenta
La cantidad de material impreso y sus lectores comenzaron a aumentar después de la invención de los tipos móviles en Europa en la década de 1450. Como explicó la escritora y editora Lynne Truss, "El auge de la imprenta en los siglos XIV y XV significó que se requería con urgencia un sistema estándar de puntuación". Los libros impresos, cuyas letras eran uniformes, podían leerse mucho más rápidamente que los manuscritos. La lectura rápida, o la lectura en voz alta, no les dio tiempo para analizar las estructuras de las oraciones. Este aumento de la velocidad condujo a un mayor uso y finalmente a la estandarización de la puntuación, que mostraba las relaciones de las palabras entre sí: dónde termina una oración y comienza otra, por ejemplo.
La introducción de un sistema estándar de puntuación también se ha atribuido a los impresores venecianos Aldus Manutius y su nieto. Se les atribuye la popularización de la práctica de terminar las oraciones con dos puntos o un punto (punto), la invención del punto y coma, el uso ocasional de paréntesis y la creación de la coma moderna bajando la virgula. Hacia 1566, Aldus Manutius the Younger pudo afirmar que el objeto principal de la puntuación era la clarificación de la sintaxis.
Para el siglo XIX, la puntuación en el mundo occidental había evolucionado "para clasificar las marcas jerárquicamente, en términos de peso". El poema de Cecil Hartley identifica sus valores relativos:
La parada señala, con la verdad, el tiempo de pausa
Una frase requiere en la cláusula ev'ry.
En ev'ry coma, pare mientras uno cuenta;
En el semilón, dos. es la cantidad;
Un colon requiere el tiempo tres;
Período 4Como los hombres aprendidos están de acuerdo.
El uso de la puntuación no se estandarizó hasta después de la invención de la imprenta. Según la edición de 1885 de The American Printer, la importancia de la puntuación se señaló en varios dichos de niños como
Charles el Primero caminó y habló
Media hora después de que le cortaron la cabeza.
Con un punto y coma y una coma, se lee de la siguiente manera:
Carlos el Primero caminaba y hablaba;
Media hora después, le cortaron la cabeza.
En un manual de tipografía del siglo XIX, Thomas MacKellar escribe:
Poco después de la invención de la impresión, la necesidad de paradas o pausas en oraciones por la guía del lector produjo el colon y punto completo. En proceso de tiempo, se añadió la coma, que era entonces simplemente una línea perpendicular, proporcionada al cuerpo de la carta. Estos tres puntos fueron los únicos utilizados hasta la clausura del siglo XV, cuando Aldo Manuccio dio una mejor forma a la coma, y añadió el ymicolón; la coma que denota la pausa más corta, el ymicolón siguiente, luego el colon, y el punto completo que termina la sentencia. Las marcas de interrogatorio y admiración fueron introducidas muchos años después.
Máquinas de escribir y comunicación electrónica
La introducción de la telegrafía eléctrica con un conjunto limitado de códigos de transmisión y máquinas de escribir con un conjunto limitado de teclas influyó sutilmente en la puntuación. Por ejemplo, las comillas curvas y los apóstrofes se colapsaron en dos caracteres (' y "). El guión, el signo menos y los guiones de varios anchos se han colapsado en un solo carácter (-), a veces repetido para representar un guión largo. Los espacios de diferentes anchos disponibles para los tipógrafos profesionales generalmente fueron reemplazados por un solo espacio de ancho de carácter completo, con tipos de letra monoespaciados. En algunos casos, el teclado de una máquina de escribir no incluía un signo de exclamación (!), pero esto se construyó superponiendo un apóstrofe y un punto; el código Morse original no tenía un signo de exclamación.
Estas simplificaciones se han trasladado a la escritura digital, con teleimpresoras y el juego de caracteres ASCII esencialmente admitiendo los mismos caracteres que las máquinas de escribir. El tratamiento de los espacios en blanco en HTML desalentó la práctica (en prosa inglesa) de poner dos espacios completos después de un punto, ya que un espacio simple o doble aparecería igual en la pantalla. (Algunas guías de estilo ahora desalientan los espacios dobles, y algunas herramientas de escritura electrónica, incluido el software de Wikipedia, colapsan automáticamente los espacios dobles en uno solo). procesadores A pesar de la adopción generalizada de conjuntos de caracteres como Unicode que admiten la puntuación de la composición tipográfica tradicional, los formularios de escritura, como los mensajes de texto, tienden a utilizar el estilo de puntuación ASCII simplificado, con la adición de nuevos caracteres que no son de texto, como emoji. El lenguaje de texto informal tiende a eliminar la puntuación cuando no es necesaria, incluidas algunas formas que se considerarían errores en una escritura más formal.
En la era de las computadoras, los caracteres de puntuación se reciclaron para su uso en lenguajes de programación y direcciones URL. Debido a su uso en los identificadores de correo electrónico y Twitter, el signo de arroba (@) ha pasado de ser un carácter oscuro utilizado principalmente por los vendedores de productos básicos a granel (10 libras a $ 2,00 por libra), a un carácter muy común de uso común tanto para enrutamiento técnico y una abreviatura de "at". La tilde (~), en tipos móviles solo se usa en combinación con vocales, por razones mecánicas terminó como una tecla separada en las máquinas de escribir mecánicas y, como @, se le ha dado usos completamente nuevos.
En inglés
Hay dos estilos principales de puntuación en inglés: británico o estadounidense. Estos dos estilos difieren principalmente en la forma en que manejan las comillas, particularmente en conjunto con otros signos de puntuación. En inglés británico, los signos de puntuación como puntos y comas se colocan dentro de las comillas solo si son parte de lo que se cita, y se colocan fuera de las comillas de cierre si forman parte de la oración contenedora. En inglés americano, sin embargo, dicha puntuación generalmente se coloca dentro de las comillas de cierre independientemente. Esta regla varía para otros signos de puntuación; por ejemplo, el inglés americano sigue la regla del inglés británico cuando se trata de punto y coma, dos puntos, signos de interrogación y de exclamación. La coma serial se usa con mucha más frecuencia en los Estados Unidos que en Inglaterra.
Otros idiomas
Otros idiomas de Europa utilizan prácticamente la misma puntuación que el inglés. La similitud es tan fuerte que las pocas variaciones pueden confundir a un lector nativo de inglés. Las comillas son particularmente variables entre los idiomas europeos. Por ejemplo, en francés y ruso, las comillas aparecerían como: «Je suis fatigué.» (en francés, cada "puntuación doble", como el guillemet, requiere un espacio de no separación; en ruso no lo requiere).
En francés de Francia y Bélgica, los signos : ; ? y ! siempre van precedidos de un espacio delgado que no se rompe. En francés canadiense, este es solo el caso de :.
En griego, el signo de interrogación se escribe como punto y coma en inglés, mientras que las funciones de los dos puntos y el punto y coma se realizan mediante un punto elevado ⟨·⟩, conocido como ano teleia (άνω τελεία).
En georgiano, los tres puntos, ⟨჻⟩, se usaban anteriormente como separadores de oraciones o párrafos. Todavía se usa a veces en caligrafía.
El español y el asturiano (ambas lenguas romances utilizadas en España) utilizan un signo de interrogación invertido ⟨¿⟩ al principio de una pregunta y el signo de interrogación normal al final, así como un signo de exclamación invertido ⟨¡⟩ al el comienzo de una exclamación y el signo de exclamación normal al final.
El armenio usa varios signos de puntuación propios. El punto final se representa con dos puntos y viceversa; el signo de exclamación está representado por una diagonal similar a una tilde ⟨~⟩, mientras que el signo de interrogación ⟨՞⟩ se parece a un círculo sin cerrar colocado después de la última vocal de la palabra.
El árabe, el urdu y el persa (escritos de derecha a izquierda) usan un signo de interrogación invertido: ⟨؟⟩ y una coma invertida: ⟨،⟩. Esta es una innovación moderna; El árabe premoderno no usaba puntuación. El hebreo, que también se escribe de derecha a izquierda, usa los mismos caracteres que en inglés, ⟨,⟩ y ⟨?⟩.
Originalmente, el sánscrito no tenía puntuación. En el siglo XVII, el sánscrito y el marathi, ambos escritos en devanagari, comenzaron a usar la barra vertical ⟨।⟩ para terminar una línea de prosa y barras verticales dobles ⟨॥⟩ en verso.
La puntuación no se usó en la escritura Chu Nom china, japonesa, coreana y vietnamita hasta la adopción de la puntuación de Occidente a finales del siglo XIX y principios del XX. En los textos sin puntuación, la estructura gramatical de las oraciones en la escritura clásica se deduce del contexto. La mayoría de los signos de puntuación en chino, japonés y coreano modernos tienen funciones similares a sus contrapartes en inglés; sin embargo, a menudo se ven diferentes y tienen diferentes reglas consuetudinarias.
En el subcontinente indio, ⟨:-⟩ se usa a veces en lugar de dos puntos o después de un subtítulo. Su origen no está claro, pero podría ser un remanente del Raj británico. Otra puntuación común en el subcontinente indio para escribir cantidades monetarias es el uso de ⟨/-⟩ o ⟨/=⟩ después del número. Por ejemplo, Rs. 20/- o Rs. 20/= implica 20 rupias enteras.
Los tailandeses, los jemeres, los laosianos y los birmanos no usaron la puntuación hasta que se adoptaron en Occidente en el siglo XX. Los espacios en blanco son más frecuentes que los puntos o comas.
Novedosos signos de puntuación
Interrobang
En 1962, el ejecutivo de publicidad estadounidense Martin K. Speckter propuso el interrobang (‽), una combinación del signo de interrogación y exclamación, para marcar preguntas retóricas o formuladas con un tono de incredulidad. Aunque el nuevo signo de puntuación fue ampliamente discutido en la década de 1960, no logró un uso generalizado.
"Punto de amor" y marcas similares
En 1966, el autor francés Hervé Bazin propuso una serie de seis signos de puntuación innovadores en su libro Plumons l'Oiseau ("Vamos a desplumar el pájaro", 1966). Éstas eran:
- el "punto de la puerta" o "marca de la puerta" (punto d'ironie:
 )
) - el "punto del amor"punto d'amour:
 )
) - el "punto de condena" (punto de convicción:
 Un punto de amor, o "punto de amor".
Un punto de amor, o "punto de amor". )
) - el "punto de autoría"punto d'autorité:
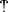 )
) - el "punto de aclamación"punto d'acclamation:
 )
) - el "punto de duda" (point de doute:
 )
)
_%E2%80%93_variant.svg)
"Coma de pregunta", "coma de exclamación"

Se presentó una solicitud de patente internacional y se publicó en 1992 con el número WO9219458 de la Organización Mundial de la Propiedad Intelectual (OMPI) para dos nuevos signos de puntuación: la "coma de pregunta" y la "coma de exclamación". La coma de pregunta tiene una coma en lugar del punto en la parte inferior de un signo de interrogación, mientras que la coma de exclamación tiene una coma en lugar del punto en la parte inferior de un signo de exclamación. Marcos. Estos estaban destinados a usarse como signos de interrogación y exclamación dentro de una oración, una función para la que también se pueden usar los signos de interrogación y exclamación normales, pero que puede considerarse obsoleto. La solicitud de patente entró en la fase nacional únicamente en Canadá. Se anunció como caducado en Australia el 27 de enero de 1994 y en Canadá el 6 de noviembre de 1995.
Signos de puntuación en Unicode
| Por Unicode General CategoryP' |
| § Pd, dash |
| § Ps-Pe, start-end (entre corchetes de cierre abierto) |
| § Pi-Pf, presupuesto inicial–final |
| § Pc, conector |
| § Po, otro |
| Mark | Name | Code point | General Category | Script | |
|---|---|---|---|---|---|
| Pd, dash | |||||
| - | HYPHEN-MINUS | U+002D | Pd, dash | Common | |
| ‐ | HYPHEN | U+2010 | Pd, dash | Common | |
| ‑ | NON-BREAKING HYPHEN | U+2011 | Pd, dash | Common | |
| ‒ | FIGURE DASH | U+2012 | Pd, dash | Common | |
| – | EN DASH | U+2013 | Pd, dash | Common | |
| — | EM DASH | U+2014 | Pd, dash | Common | |
| ― | HORIZONTAL BAR | U+2015 | Pd, dash | Common | |
| ⸗ | DOUBLE OBLIQUE HYPHEN | U+2E17 | Pd, dash | Common | |
| ⸚ | HYPHEN WITH DIAERESIS | U+2E1A | Pd, dash | Common | |
| ⸺ | TWO-EM DASH | U+2E3A | Pd, dash | Common | |
| ⸻ | THREE-EM DASH | U+2E3B | Pd, dash | Common | |
| ⹀ | DOUBLE HYPHEN | U+2E40 | Pd, dash | Common | |
| 〜 | WAVE DASH | U+301C | Pd, dash | Common | |
| 〰 | WAVY DASH | U+3030 | Pd, dash | Common | |
| ゠ | KATAKANA-HIRAGANA DOUBLE HYPHEN | U+30A0 | Pd, dash | Common | |
| ︱ | PRESENTATION FORM FOR VERTICAL EM DASH | U+FE31 | Pd, dash | Common | |
| ︲ | PRESENTATION FORM FOR VERTICAL EN DASH | U+FE32 | Pd, dash | Common | |
| ﹘ | SMALL EM DASH | U+FE58 | Pd, dash | Common | |
| ﹣ | SMALL HYPHEN-MINUS | U+FE63 | Pd, dash | Common | |
| - | FULLWIDTH HYPHEN-MINUS | U+FF0D | Pd, dash | Common | |
| ֊ | ARMENIAN HYPHEN | U+058A | Pd, dash | Armenian | |
| ᐀ | CANADIAN SYLLABICS HYPHEN | U+1400 | Pd, dash | Canadian Aboriginal | |
| ־ | HEBREW PUNCTUATION MAQAF | U+05BE | Pd, dash | Hebrew | |
| ᠆ | MONGOLIAN TODO SOFT HYPHEN | U+1806 | Pd, dash | Mongolian | |
| 𐺭 | YEZIDI HYPHENATION MARK | U+10EAD | Pd, dash | Yezidi | |
| Pi-Pf, initial–final quote | |||||
| « » |
|
|
|
Common | |
| ‘ ’ |
|
|
|
Common | |
| ‛ | SINGLE HIGH-REVERSED-9 QUOTATION MARK | U+201B | Pi, initial quote | Common | |
| “ ” |
|
|
|
Common | |
| ‟ | DOUBLE HIGH-REVERSED-9 QUOTATION MARK | U+201F | Pi, initial quote | Common | |
| ‹ › |
|
|
|
Common | |
| ⸂ ⸃ |
|
|
|
Common | |
| ⸄ ⸅ |
|
|
|
Common | |
| ⸉ ⸊ |
|
|
|
Common | |
| ⸌ ⸍ |
|
|
|
Common | |
| ⸜ ⸝ |
|
|
|
Common | |
| ⸠ ⸡ |
|
|
|
Common | |
| Ps-Pe, open–close (brackets) | |||||
| () |
|
|
|
Common | |
| [ ] |
|
|
|
Common | |
| { } |
|
|
|
Common | |
| ‚ | SINGLE LOW-9 QUOTATION MARK | U+201A | Ps, open | Common | |
| „ | DOUBLE LOW-9 QUOTATION MARK | U+201E | Ps, open | Common | |
| ⁅ ⁆ |
|
|
|
Common | |
| ⁽ ⁾ |
|
|
|
Common | |
| ₍ ₎ |
|
|
|
Common | |
| ⌈ ⌉ |
|
|
|
Common | |
| ⌊ ⌋ |
|
|
|
Common | |
| 〈 〉 |
|
|
|
Common | |
| ❨ ❩ |
|
|
|
Common | |
| ❪ ❫ |
|
|
|
Common | |
| ❬ ❭ |
|
|
|
Common | |
| ❮ ❯ |
|
|
|
Common | |
| ❰ ❱ |
|
|
|
Common | |
| ❲ ❳ |
|
|
|
Common | |
| ❴ ❵ |
|
|
|
Common | |
| ⟅ ⟆ |
|
|
|
Common | |
| ⟦ ⟧ |
|
|
|
Common | |
| ⟨ ⟩ |
|
|
|
Common | |
| ⟪ ⟫ |
|
|
|
Common | |
| ⟬ ⟭ |
|
|
|
Common | |
| ⟮ ⟯ |
|
|
|
Common | |
| ⦃ ⦄ |
|
|
|
Common | |
| ⦅ ⦆ |
|
|
|
Common | |
| ⦇ ⦈ |
|
|
|
Common | |
| ⦉ ⦊ |
|
|
|
Common | |
| ⦋ ⦌ |
|
|
|
Common | |
| ⦍ ⦎ |
|
|
|
Common | |
| ⦏ ⦐ |
|
|
|
Common | |
| ⦑ ⦒ |
|
|
|
Common | |
| ⦓ ⦔ |
|
|
|
Common | |
| ⦕ ⦖ |
|
|
|
Common | |
| ⦗ ⦘ |
|
|
|
Common | |
| ⧘ ⧙ |
|
|
|
Common | |
| ⧚ ⧛ |
|
|
|
Common | |
| ⧼ ⧽ |
|
|
|
Common | |
| ⸢ ⸣ |
|
|
|
Common | |
| ⸤ ⸥ |
|
|
|
Common | |
| ⸦ ⸧ |
|
|
|
Common | |
| ⸨ ⸩ |
|
|
|
Common | |
| ⹂ | DOUBLE LOW-REVERSED-9 QUOTATION MARK | U+2E42 | Ps, open | Common | |
| 〈 〉 |
|
|
|
Common | |
| 《 》 |
|
|
|
Common | |
| 「 」 |
|
|
|
Common | |
| 『 』 |
|
|
|
Common | |
| 【 】 |
|
|
|
Common | |
| 〔 〕 |
|
|
|
Common | |
| 〖 〗 |
|
|
|
Common | |
| 〘 〙 |
|
|
|
Common | |
| 〚 〛 |
|
|
|
Common | |
| 〝 〞 |
|
|
|
Common | |
| 〟 | LOW DOUBLE PRIME QUOTATION MARK | U+301F | Pe, close | Common | |
| ﴿ | ORNATE RIGHT PARENTHESIS | U+FD3F | Ps, open | Common | |
| ︗ ︘ |
|
|
|
Common | |
| ︵ ︶ |
|
|
|
Common | |
| ︷ ︸ |
|
|
|
Common | |
| ︹ ︺ |
|
|
|
Common | |
| ︻ ︼ |
|
|
|
Common | |
| ︽ ︾ |
|
|
|
Common | |
| ︿ ﹀ |
|
|
|
Common | |
| ﹁ ﹂ |
|
|
|
Common | |
| ﹃ ﹄ |
|
|
|
Common | |
| ﹇ ﹈ |
|
|
|
Common | |
| ﹙ ﹚ |
|
|
|
Common | |
| ﹛ ﹜ |
|
|
|
Common | |
| ﹝ ﹞ |
|
|
|
Common | |
| ( ) |
|
|
|
Common | |
| [ ] |
|
|
|
Common | |
| { } |
|
|
|
Common | |
| ⦅ ⦆ |
|
|
|
Common | |
| 「 」 |
|
|
|
Common | |
| ᚛ ᚜ |
|
|
|
Ogham | |
| ༺ ༻ |
|
|
|
Tibetan | |
| ༼ ༽ |
|
|
|
Tibetan | |
| Pc, connector | |||||
| _ | LOW LINE | U+005F | Pc, connector | Common | |
| ‿ | UNDERTIE | U+203F | Pc, connector | Common | |
| ⁀ | CHARACTER TIE | U+2040 | Pc, connector | Common | |
| ⁔ | INVERTED UNDERTIE | U+2054 | Pc, connector | Common | |
| ︳ | PRESENTATION FORM FOR VERTICAL LOW LINE | U+FE33 | Pc, connector | Common | |
| ︴ | PRESENTATION FORM FOR VERTICAL WAVY LOW LINE | U+FE34 | Pc, connector | Common | |
| ﹍ | DASHED LOW LINE | U+FE4D | Pc, connector | Common | |
| ﹎ | CENTRELINE LOW LINE | U+FE4E | Pc, connector | Common | |
| ﹏ | WAVY LOW LINE | U+FE4F | Pc, connector | Common | |
| _ | FULLWIDTH LOW LINE | U+FF3F | Pc, connector | Common | |
| Po, other | |||||
| ! | EXCLAMATION MARK | U+0021 | Po, other | Common | |
| " | QUOTATION MARK | U+0022 | Po, other | Common | |
| # | NUMBER SIGN | U+0023 | Po, other | Common | |
| % | PERCENT SIGN | U+0025 | Po, other | Common | |
| & | AMPERSAND | U+0026 | Po, other | Common | |
| ' | APOSTROPHE | U+0027 | Po, other | Common | |
| * | ASTERISK | U+002A | Po, other | Common | |
| , | COMMA | U+002C | Po, other | Common | |
| . | FULL STOP | U+002E | Po, other | Common | |
| / | SOLIDUS | U+002F | Po, other | Common | |
| : | COLON | U+003A | Po, other | Common | |
| ; | SEMICOLON | U+003B | Po, other | Common | |
| ? | QUESTION MARK | U+003F | Po, other | Common | |
| @ | COMMERCIAL AT | U+0040 | Po, other | Common | |
| REVERSE SOLIDUS | U+005C | Po, other | Common | ||
| ¡ | INVERTED EXCLAMATION MARK | U+00A1 | Po, other | Common | |
| § | SECTION SIGN | U+00A7 | Po, other | Common | |
| ¶ | PILCROW SIGN | U+00B6 | Po, other | Common | |
| · | MIDDLE DOT | U+00B7 | Po, other | Common | |
| ¿ | INVERTED QUESTION MARK | U+00BF | Po, other | Common | |
| ; | GREEK QUESTION MARK | U+037E | Po, other | Common | |
| · | GREEK ANO TELEIA | U+0387 | Po, other | Common | |
| ، | ARABIC COMMA | U+060C | Po, other | Common | |
| ؛ | ARABIC SEMICOLON | U+061B | Po, other | Common | |
| ؟ | ARABIC QUESTION MARK | U+061F | Po, other | Common | |
| । | DEVANAGARI DANDA | U+0964 | Po, other | Common | |
| ॥ | DEVANAGARI DOUBLE DANDA | U+0965 | Po, other | Common | |
| ჻ | GEORGIAN PARAGRAPH SEPARATOR | U+10FB | Po, other | Common | |
| ᛫ | RUNIC SINGLE PUNCTUATION | U+16EB | Po, other | Common | |
| ᛬ | RUNIC MULTIPLE PUNCTUATION | U+16EC | Po, other | Common | |
| ᛭ | RUNIC CROSS PUNCTUATION | U+16ED | Po, other | Common | |
| ᜵ | PHILIPPINE SINGLE PUNCTUATION | U+1735 | Po, other | Common | |
| ᜶ | PHILIPPINE DOUBLE PUNCTUATION | U+1736 | Po, other | Common | |
| ᠂ | MONGOLIAN COMMA | U+1802 | Po, other | Common | |
| ᠃ | MONGOLIAN FULL STOP | U+1803 | Po, other | Common | |
| ᠅ | MONGOLIAN FOUR DOTS | U+1805 | Po, other | Common | |
| ᳓ | VEDIC SIGN NIHSHVASA | U+1CD3 | Po, other | Common | |
| ‖ | DOUBLE VERTICAL LINE | U+2016 | Po, other | Common | |
| ‗ | DOUBLE LOW LINE | U+2017 | Po, other | Common | |
| † | DAGGER | U+2020 | Po, other | Common | |
| ‡ | DOUBLE DAGGER | U+2021 | Po, other | Common | |
| • | BULLET | U+2022 | Po, other | Common | |
| ‣ | TRIANGULAR BULLET | U+2023 | Po, other | Common | |
| ․ | ONE DOT LEADER | U+2024 | Po, other | Common | |
| ‥ | TWO DOT LEADER | U+2025 | Po, other | Common | |
| … | HORIZONTAL ELLIPSIS | U+2026 | Po, other | Common | |
| ‧ | HYPHENATION POINT | U+2027 | Po, other | Common | |
| ‰ | PER MILLE SIGN | U+2030 | Po, other | Common | |
| ‱ | PER TEN THOUSAND SIGN | U+2031 | Po, other | Common | |
| ′ | PRIME | U+2032 | Po, other | Common | |
| ″ | DOUBLE PRIME | U+2033 | Po, other | Common | |
| ‴ | TRIPLE PRIME | U+2034 | Po, other | Common | |
| ‵ | REVERSED PRIME | U+2035 | Po, other | Common | |
| ‶ | REVERSED DOUBLE PRIME | U+2036 | Po, other | Common | |
| ‷ | REVERSED TRIPLE PRIME | U+2037 | Po, other | Common | |
| ‸ | CARET | U+2038 | Po, other | Common | |
| ※ | REFERENCE MARK | U+203B | Po, other | Common | |
| ‼ | DOUBLE EXCLAMATION MARK | U+203C | Po, other | Common | |
| ‽ | INTERROBANG | U+203D | Po, other | Common | |
| ‾ | OVERLINE | U+203E | Po, other | Common | |
| ⁁ | CARET INSERTION POINT | U+2041 | Po, other | Common | |
| ⁂ | ASTERISM | U+2042 | Po, other | Common | |
| ⁃ | HYPHEN BULLET | U+2043 | Po, other | Common | |
| ⁇ | DOUBLE QUESTION MARK | U+2047 | Po, other | Common | |
| ⁈ | QUESTION EXCLAMATION MARK | U+2048 | Po, other | Common | |
| ⁉ | EXCLAMATION QUESTION MARK | U+2049 | Po, other | Common | |
| ⁊ | TIRONIAN SIGN ET | U+204A | Po, other | Common | |
| ⁋ | REVERSED PILCROW SIGN | U+204B | Po, other | Common | |
| ⁌ | BLACK LEFTWARDS BULLET | U+204C | Po, other | Common | |
| ⁍ | BLACK RIGHTWARDS BULLET | U+204D | Po, other | Common | |
| ⁎ | LOW ASTERISK | U+204E | Po, other | Common | |
| ⁏ | REVERSED SEMICOLON | U+204F | Po, other | Common | |
| ⁐ | CLOSE UP | U+2050 | Po, other | Common | |
| ⁑ | TWO ASTERISKS ALIGNED VERTICALLY | U+2051 | Po, other | Common | |
| ⁓ | SWUNG DASH | U+2053 | Po, other | Common | |
| ⁕ | FLOWER PUNCTUATION MARK | U+2055 | Po, other | Common | |
| ⁖ | THREE DOT PUNCTUATION | U+2056 | Po, other | Common | |
| ⁗ | QUADRUPLE PRIME | U+2057 | Po, other | Common | |
| ⁘ | FOUR DOT PUNCTUATION | U+2058 | Po, other | Common | |
| ⁙ | FIVE DOT PUNCTUATION | U+2059 | Po, other | Common | |
| ⁚ | TWO DOT PUNCTUATION | U+205A | Po, other | Common | |
| ⁛ | FOUR DOT MARK | U+205B | Po, other | Common | |
| ⁜ | DOTTED CROSS | U+205C | Po, other | Common | |
| ⁝ | TRICOLON | U+205D | Po, other | Common | |
| ⁞ | VERTICAL FOUR DOTS | U+205E | Po, other | Common | |
| ⸀ | RIGHT ANGLE SUBSTITUTION MARKER | U+2E00 | Po, other | Common | |
| ⸁ | RIGHT ANGLE DOTTED SUBSTITUTION MARKER | U+2E01 | Po, other | Common | |
| ⸆ | RAISED INTERPOLATION MARKER | U+2E06 | Po, other | Common | |
| ⸇ | RAISED DOTTED INTERPOLATION MARKER | U+2E07 | Po, other | Common | |
| ⸈ | DOTTED TRANSPOSITION MARKER | U+2E08 | Po, other | Common | |
| ⸋ | RAISED SQUARE | U+2E0B | Po, other | Common | |
| ⸎ | EDITORIAL CORONIS | U+2E0E | Po, other | Common | |
| ⸏ | PARAGRAPHOS | U+2E0F | Po, other | Common | |
| ⸐ | FORKED PARAGRAPHOS | U+2E10 | Po, other | Common | |
| ⸑ | REVERSED FORKED PARAGRAPHOS | U+2E11 | Po, other | Common | |
| ⸒ | HYPODIASTOLE | U+2E12 | Po, other | Common | |
| ⸓ | DOTTED OBELOS | U+2E13 | Po, other | Common | |
| ⸔ | DOWNWARDS ANCORA | U+2E14 | Po, other | Common | |
| ⸕ | UPWARDS ANCORA | U+2E15 | Po, other | Common | |
| ⸖ | DOTTED RIGHT-POINTING ANGLE | U+2E16 | Po, other | Common | |
| ⸘ | INVERTED INTERROBANG | U+2E18 | Po, other | Common | |
| ⸙ | PALM BRANCH | U+2E19 | Po, other | Common | |
| ⸛ | TILDE WITH RING ABOVE | U+2E1B | Po, other | Common | |
| ⸞ | TILDE WITH DOT ABOVE | U+2E1E | Po, other | Common | |
| ⸟ | TILDE WITH DOT BELOW | U+2E1F | Po, other | Common | |
| ⸪ | TWO DOTS OVER ONE DOT PUNCTUATION | U+2E2A | Po, other | Common | |
| ⸫ | ONE DOT OVER TWO DOTS PUNCTUATION | U+2E2B | Po, other | Common | |
| ⸬ | SQUARED FOUR DOT PUNCTUATION | U+2E2C | Po, other | Common | |
| ⸭ | FIVE DOT MARK | U+2E2D | Po, other | Common | |
| ⸮ | REVERSED QUESTION MARK | U+2E2E | Po, other | Common | |
| ⸰ | RING POINT | U+2E30 | Po, other | Common | |
| ⸱ | WORD SEPARATOR MIDDLE DOT | U+2E31 | Po, other | Common | |
| ⸲ | TURNED COMMA | U+2E32 | Po, other | Common | |
| ⸳ | RAISED DOT | U+2E33 | Po, other | Common | |
| ⸴ | RAISED COMMA | U+2E34 | Po, other | Common | |
| ⸵ | TURNED SEMICOLON | U+2E35 | Po, other | Common | |
| ⸶ | DAGGER WITH LEFT GUARD | U+2E36 | Po, other | Common | |
| ⸷ | DAGGER WITH RIGHT GUARD | U+2E37 | Po, other | Common | |
| ⸸ | TURNED DAGGER | U+2E38 | Po, other | Common | |
| ⸹ | TOP HALF SECTION SIGN | U+2E39 | Po, other | Common | |
| ⸼ | STENOGRAPHIC FULL STOP | U+2E3C | Po, other | Common | |
| ⸽ | VERTICAL SIX DOTS | U+2E3D | Po, other | Common | |
| ⸾ | WIGGLY VERTICAL LINE | U+2E3E | Po, other | Common | |
| ⸿ | CAPITULUM | U+2E3F | Po, other | Common | |
| ⹁ | REVERSED COMMA | U+2E41 | Po, other | Common | |
| ⹃ | DASH WITH LEFT UPTURN | U+2E43 | Po, other | Common | |
| ⹄ | DOUBLE SUSPENSION MARK | U+2E44 | Po, other | Common | |
| ⹅ | INVERTED LOW KAVYKA | U+2E45 | Po, other | Common | |
| ⹆ | INVERTED LOW KAVYKA WITH KAVYKA ABOVE | U+2E46 | Po, other | Common | |
| ⹇ | LOW KAVYKA | U+2E47 | Po, other | Common | |
| ⹈ | LOW KAVYKA WITH DOT | U+2E48 | Po, other | Common | |
| ⹉ | DOUBLE STACKED COMMA | U+2E49 | Po, other | Common | |
| ⹊ | DOTTED SOLIDUS | U+2E4A | Po, other | Common | |
| ⹋ | TRIPLE DAGGER | U+2E4B | Po, other | Common | |
| ⹌ | MEDIEVAL COMMA | U+2E4C | Po, other | Common | |
| ⹍ | PARAGRAPHUS MARK | U+2E4D | Po, other | Common | |
| ⹎ | PUNCTUS ELEVATUS MARK | U+2E4E | Po, other | Common | |
| ⹏ | CORNISH VERSE DIVIDER | U+2E4F | Po, other | Common | |
| ⹒ | TIRONIAN SIGN CAPITAL ET | U+2E52 | Po, other | Common | |
| 、 | IDEOGRAPHIC COMMA | U+3001 | Po, other | Common | |
| 。 | IDEOGRAPHIC FULL STOP | U+3002 | Po, other | Common | |
| 〃 | DITTO MARK | U+3003 | Po, other | Common | |
| 〽 | PART ALTERNATION MARK | U+303D | Po, other | Common | |
| ・ | KATAKANA MIDDLE DOT | U+30FB | Po, other | Common | |
| ꤮ | KAYAH LI SIGN CWI | U+A92E | Po, other | Common | |
| ︐ | PRESENTATION FORM FOR VERTICAL COMMA | U+FE10 | Po, other | Common | |
| ︑ | PRESENTATION FORM FOR VERTICAL IDEOGRAPHIC COMMA | U+FE11 | Po, other | Common | |
| ︒ | PRESENTATION FORM FOR VERTICAL IDEOGRAPHIC FULL STOP | U+FE12 | Po, other | Common | |
| ︓ | PRESENTATION FORM FOR VERTICAL COLON | U+FE13 | Po, other | Common | |
| ︔ | PRESENTATION FORM FOR VERTICAL SEMICOLON | U+FE14 | Po, other | Common | |
| ︕ | PRESENTATION FORM FOR VERTICAL EXCLAMATION MARK | U+FE15 | Po, other | Common | |
| ︖ | PRESENTATION FORM FOR VERTICAL QUESTION MARK | U+FE16 | Po, other | Common | |
| ︙ | PRESENTATION FORM FOR VERTICAL HORIZONTAL ELLIPSIS | U+FE19 | Po, other | Common | |
| ︰ | PRESENTATION FORM FOR VERTICAL TWO DOT LEADER | U+FE30 | Po, other | Common | |
| ﹅ | SESAME DOT | U+FE45 | Po, other | Common | |
| ﹆ | WHITE SESAME DOT | U+FE46 | Po, other | Common | |
| ﹉ | DASHED OVERLINE | U+FE49 | Po, other | Common | |
| ﹊ | CENTRELINE OVERLINE | U+FE4A | Po, other | Common | |
| ﹋ | WAVY OVERLINE | U+FE4B | Po, other | Common | |
| ﹌ | DOUBLE WAVY OVERLINE | U+FE4C | Po, other | Common | |
| ﹐ | SMALL COMMA | U+FE50 | Po, other | Common | |
| ﹑ | SMALL IDEOGRAPHIC COMMA | U+FE51 | Po, other | Common | |
| ﹒ | SMALL FULL STOP | U+FE52 | Po, other | Common | |
| ﹔ | SMALL SEMICOLON | U+FE54 | Po, other | Common | |
| ﹕ | SMALL COLON | U+FE55 | Po, other | Common | |
| ﹖ | SMALL QUESTION MARK | U+FE56 | Po, other | Common | |
| ﹗ | SMALL EXCLAMATION MARK | U+FE57 | Po, other | Common | |
| ﹟ | SMALL NUMBER SIGN | U+FE5F | Po, other | Common | |
| ﹠ | SMALL AMPERSAND | U+FE60 | Po, other | Common | |
| ﹡ | SMALL ASTERISK | U+FE61 | Po, other | Common | |
| ﹨ | SMALL REVERSE SOLIDUS | U+FE68 | Po, other | Common | |
| ﹪ | SMALL PERCENT SIGN | U+FE6A | Po, other | Common | |
| ﹫ | SMALL COMMERCIAL AT | U+FE6B | Po, other | Common | |
| ! | FULLWIDTH EXCLAMATION MARK | U+FF01 | Po, other | Common | |
| " | FULLWIDTH QUOTATION MARK | U+FF02 | Po, other | Common | |
| # | FULLWIDTH NUMBER SIGN | U+FF03 | Po, other | Common | |
| % | FULLWIDTH PERCENT SIGN | U+FF05 | Po, other | Common | |
| & | FULLWIDTH AMPERSAND | U+FF06 | Po, other | Common | |
| ' | FULLWIDTH APOSTROPHE | U+FF07 | Po, other | Common | |
| * | FULLWIDTH ASTERISK | U+FF0A | Po, other | Common | |
| , | FULLWIDTH COMMA | U+FF0C | Po, other | Common | |
| . | FULLWIDTH FULL STOP | U+FF0E | Po, other | Common | |
| / | FULLWIDTH SOLIDUS | U+FF0F | Po, other | Common | |
| : | FULLWIDTH COLON | U+FF1A | Po, other | Common | |
| ; | FULLWIDTH SEMICOLON | U+FF1B | Po, other | Common | |
| ? | FULLWIDTH QUESTION MARK | U+FF1F | Po, other | Common | |
| @ | FULLWIDTH COMMERCIAL AT | U+FF20 | Po, other | Common | |
| \ | FULLWIDTH REVERSE SOLIDUS | U+FF3C | Po, other | Common | |
| 。 | HALFWIDTH IDEOGRAPHIC FULL STOP | U+FF61 | Po, other | Common | |
| 、 | HALFWIDTH IDEOGRAPHIC COMMA | U+FF64 | Po, other | Common | |
| ・ | HALFWIDTH KATAKANA MIDDLE DOT | U+FF65 | Po, other | Common | |
| 𐄀 | AEGEAN WORD SEPARATOR LINE | U+10100 | Po, other | Common | |
| 𐄁 | AEGEAN WORD SEPARATOR DOT | U+10101 | Po, other | Common | |
| 𐄂 | AEGEAN CHECK MARK | U+10102 | Po, other | Common | |
| 𖿢 | OLD CHINESE HOOK MARK | U+16FE2 | Po, other | Common | |
| 𞥞 | ADLAM INITIAL EXCLAMATION MARK | U+1E95E | Po, other | Adlam | |
| 𞥟 | ADLAM INITIAL QUESTION MARK | U+1E95F | Po, other | Adlam | |
| ՚ | ARMENIAN APOSTROPHE | U+055A | Po, other | Armenian | |
| ՛ | ARMENIAN EMPHASIS MARK | U+055B | Po, other | Armenian | |
| ՜ | ARMENIAN EXCLAMATION MARK | U+055C | Po, other | Armenian | |
| ՝ | ARMENIAN COMMA | U+055D | Po, other | Armenian | |
| ՞ | ARMENIAN QUESTION MARK | U+055E | Po, other | Armenian | |
| ՟ | ARMENIAN ABBREVIATION MARK | U+055F | Po, other | Armenian | |
| ։ | ARMENIAN FULL STOP | U+0589 | Po, other | Armenian | |
| ؉ | ARABIC-INDIC PER MILLE SIGN | U+0609 | Po, other | Arabic | |
| ؊ | ARABIC-INDIC PER TEN THOUSAND SIGN | U+060A | Po, other | Arabic | |
| ؍ | ARABIC DATE SEPARATOR | U+060D | Po, other | Arabic | |
| ؞ | ARABIC TRIPLE DOT PUNCTUATION MARK | U+061E | Po, other | Arabic | |
| ٪ | ARABIC PERCENT SIGN | U+066A | Po, other | Arabic | |
| ٫ | ARABIC DECIMAL SEPARATOR | U+066B | Po, other | Arabic | |
| ٬ | ARABIC THOUSANDS SEPARATOR | U+066C | Po, other | Arabic | |
| ٭ | ARABIC FIVE POINTED STAR | U+066D | Po, other | Arabic | |
| ۔ | ARABIC FULL STOP | U+06D4 | Po, other | Arabic | |
| 𑜼 | AHOM SIGN SMALL SECTION | U+1173C | Po, other | Ahom | |
| 𑜽 | AHOM SIGN SECTION | U+1173D | Po, other | Ahom | |
| 𑜾 | AHOM SIGN RULAI | U+1173E | Po, other | Ahom | |
| 𐬹 | AVESTAN ABBREVIATION MARK | U+10B39 | Po, other | Avestan | |
| 𐬺 | TINY TWO DOTS OVER ONE DOT PUNCTUATION | U+10B3A | Po, other | Avestan | |
| 𐬻 | SMALL TWO DOTS OVER ONE DOT PUNCTUATION | U+10B3B | Po, other | Avestan | |
| 𐬼 | LARGE TWO DOTS OVER ONE DOT PUNCTUATION | U+10B3C | Po, other | Avestan | |
| 𐬽 | LARGE ONE DOT OVER TWO DOTS PUNCTUATION | U+10B3D | Po, other | Avestan | |
| 𐬾 | LARGE TWO RINGS OVER ONE RING PUNCTUATION | U+10B3E | Po, other | Avestan | |
| 𐬿 | LARGE ONE RING OVER TWO RINGS PUNCTUATION | U+10B3F | Po, other | Avestan | |
| ᭚ | BALINESE PANTI | U+1B5A | Po, other | Balinese | |
| ᭛ | BALINESE PAMADA | U+1B5B | Po, other | Balinese | |
| ᭜ | BALINESE WINDU | U+1B5C | Po, other | Balinese | |
| ᭝ | BALINESE CARIK PAMUNGKAH | U+1B5D | Po, other | Balinese | |
| ᭞ | BALINESE CARIK SIKI | U+1B5E | Po, other | Balinese | |
| ᭟ | BALINESE CARIK PAREREN | U+1B5F | Po, other | Balinese | |
| ᭠ | BALINESE PAMENENG | U+1B60 | Po, other | Balinese | |
| ꛲ | BAMUM NJAEMLI | U+A6F2 | Po, other | Bamum | |
| ꛳ | BAMUM FULL STOP | U+A6F3 | Po, other | Bamum | |
| ꛴ | BAMUM COLON | U+A6F4 | Po, other | Bamum | |
| ꛵ | BAMUM COMMA | U+A6F5 | Po, other | Bamum | |
| ꛶ | BAMUM SEMICOLON | U+A6F6 | Po, other | Bamum | |
| ꛷ | BAMUM QUESTION MARK | U+A6F7 | Po, other | Bamum | |
| 𖫵 | BASSA VAH FULL STOP | U+16AF5 | Po, other | Bassa Vah | |
| ᯼ | BATAK SYMBOL BINDU NA METEK | U+1BFC | Po, other | Batak | |
| ᯽ | BATAK SYMBOL BINDU PINARBORAS | U+1BFD | Po, other | Batak | |
| ᯾ | BATAK SYMBOL BINDU JUDUL | U+1BFE | Po, other | Batak | |
| ᯿ | BATAK SYMBOL BINDU PANGOLAT | U+1BFF | Po, other | Batak | |
| ৽ | BENGALI ABBREVIATION SIGN | U+09FD | Po, other | Bengali | |
| 𑱁 | BHAIKSUKI DANDA | U+11C41 | Po, other | Bhaiksuki | |
| 𑱂 | BHAIKSUKI DOUBLE DANDA | U+11C42 | Po, other | Bhaiksuki | |
| 𑱃 | BHAIKSUKI WORD SEPARATOR | U+11C43 | Po, other | Bhaiksuki | |
| 𑱄 | BHAIKSUKI GAP FILLER-1 | U+11C44 | Po, other | Bhaiksuki | |
| 𑱅 | BHAIKSUKI GAP FILLER-2 | U+11C45 | Po, other | Bhaiksuki | |
| 𑁇 | BRAHMI DANDA | U+11047 | Po, other | Brahmi | |
| 𑁈 | BRAHMI DOUBLE DANDA | U+11048 | Po, other | Brahmi | |
| 𑁉 | BRAHMI PUNCTUATION DOT | U+11049 | Po, other | Brahmi | |
| 𑁊 | BRAHMI PUNCTUATION DOUBLE DOT | U+1104A | Po, other | Brahmi | |
| 𑁋 | BRAHMI PUNCTUATION LINE | U+1104B | Po, other | Brahmi | |
| 𑁌 | BRAHMI PUNCTUATION CRESCENT BAR | U+1104C | Po, other | Brahmi | |
| 𑁍 | BRAHMI PUNCTUATION LOTUS | U+1104D | Po, other | Brahmi | |
| ᨞ | BUGINESE PALLAWA | U+1A1E | Po, other | Buginese | |
| ᨟ | BUGINESE END OF SECTION | U+1A1F | Po, other | Buginese | |
| ᙮ | CANADIAN SYLLABICS FULL STOP | U+166E | Po, other | Canadian Aboriginal | |
| 𑅀 | CHAKMA SECTION MARK | U+11140 | Po, other | Chakma | |
| 𑅁 | CHAKMA DANDA | U+11141 | Po, other | Chakma | |
| 𑅂 | CHAKMA DOUBLE DANDA | U+11142 | Po, other | Chakma | |
| 𑅃 | CHAKMA QUESTION MARK | U+11143 | Po, other | Chakma | |
| ꩜ | CHAM PUNCTUATION SPIRAL | U+AA5C | Po, other | Cham | |
| ꩝ | CHAM PUNCTUATION DANDA | U+AA5D | Po, other | Cham | |
| ꩞ | CHAM PUNCTUATION DOUBLE DANDA | U+AA5E | Po, other | Cham | |
| ꩟ | CHAM PUNCTUATION TRIPLE DANDA | U+AA5F | Po, other | Cham | |
| ⳹ | COPTIC OLD NUBIAN FULL STOP | U+2CF9 | Po, other | Coptic | |
| ⳺ | COPTIC OLD NUBIAN DIRECT QUESTION MARK | U+2CFA | Po, other | Coptic | |
| ⳻ | COPTIC OLD NUBIAN INDIRECT QUESTION MARK | U+2CFB | Po, other | Coptic | |
| ⳼ | COPTIC OLD NUBIAN VERSE DIVIDER | U+2CFC | Po, other | Coptic | |
| ⳾ | COPTIC FULL STOP | U+2CFE | Po, other | Coptic | |
| ⳿ | COPTIC MORPHOLOGICAL DIVIDER | U+2CFF | Po, other | Coptic | |
| 𒑰 | CUNEIFORM PUNCTUATION SIGN OLD ASSYRIAN WORD DIVIDER | U+12470 | Po, other | Cuneiform | |
| 𒑱 | CUNEIFORM PUNCTUATION SIGN VERTICAL COLON | U+12471 | Po, other | Cuneiform | |
| 𒑲 | CUNEIFORM PUNCTUATION SIGN DIAGONAL COLON | U+12472 | Po, other | Cuneiform | |
| 𒑳 | CUNEIFORM PUNCTUATION SIGN DIAGONAL TRICOLON | U+12473 | Po, other | Cuneiform | |
| 𒑴 | CUNEIFORM PUNCTUATION SIGN DIAGONAL QUADCOLON | U+12474 | Po, other | Cuneiform | |
| ꙳ | SLAVONIC ASTERISK | U+A673 | Po, other | Cyrillic | |
| ꙾ | CYRILLIC KAVYKA | U+A67E | Po, other | Cyrillic | |
| 𐕯 | CAUCASIAN ALBANIAN CITATION MARK | U+1056F | Po, other | Caucasian Albanian | |
| ॰ | DEVANAGARI ABBREVIATION SIGN | U+0970 | Po, other | Devanagari | |
| ꣸ | DEVANAGARI SIGN PUSHPIKA | U+A8F8 | Po, other | Devanagari | |
| ꣹ | DEVANAGARI GAP FILLER | U+A8F9 | Po, other | Devanagari | |
| ꣺ | DEVANAGARI CARET | U+A8FA | Po, other | Devanagari | |
| ꣼ | DEVANAGARI SIGN SIDDHAM | U+A8FC | Po, other | Devanagari | |
| 𑥄 | DIVES AKURU DOUBLE DANDA | U+11944 | Po, other | Dives Akuru | |
| 𑥅 | DIVES AKURU GAP FILLER | U+11945 | Po, other | Dives Akuru | |
| 𑥆 | DIVES AKURU END OF TEXT MARK | U+11946 | Po, other | Dives Akuru | |
| 𑠻 | DOGRA ABBREVIATION SIGN | U+1183B | Po, other | Dogra | |
| 𛲟 | DUPLOYAN PUNCTUATION CHINOOK FULL STOP | U+1BC9F | Po, other | Duployan | |
| ፠ | ETHIOPIC SECTION MARK | U+1360 | Po, other | Ethiopic | |
| ፡ | ETHIOPIC WORDSPACE | U+1361 | Po, other | Ethiopic | |
| ። | ETHIOPIC FULL STOP | U+1362 | Po, other | Ethiopic | |
| ፣ | ETHIOPIC COMMA | U+1363 | Po, other | Ethiopic | |
| ፤ | ETHIOPIC SEMICOLON | U+1364 | Po, other | Ethiopic | |
| ፥ | ETHIOPIC COLON | U+1365 | Po, other | Ethiopic | |
| ፦ | ETHIOPIC PREFACE COLON | U+1366 | Po, other | Ethiopic | |
| ፧ | ETHIOPIC QUESTION MARK | U+1367 | Po, other | Ethiopic | |
| ፨ | ETHIOPIC PARAGRAPH SEPARATOR | U+1368 | Po, other | Ethiopic | |
| ੶ | GURMUKHI ABBREVIATION SIGN | U+0A76 | Po, other | Gurmukhi | |
| ૰ | GUJARATI ABBREVIATION SIGN | U+0AF0 | Po, other | Gujarati | |
| ׀ | HEBREW PUNCTUATION PASEQ | U+05C0 | Po, other | Hebrew | |
| ׃ | HEBREW PUNCTUATION SOF PASUQ | U+05C3 | Po, other | Hebrew | |
| ׆ | HEBREW PUNCTUATION NUN HAFUKHA | U+05C6 | Po, other | Hebrew | |
| ׳ | HEBREW PUNCTUATION GERESH | U+05F3 | Po, other | Hebrew | |
| ״ | HEBREW PUNCTUATION GERSHAYIM | U+05F4 | Po, other | Hebrew | |
| 𐡗 | IMPERIAL ARAMAIC SECTION SIGN | U+10857 | Po, other | Imperial Aramaic | |
| ꧁ | JAVANESE LEFT RERENGGAN | U+A9C1 | Po, other | Javanese | |
| ꧂ | JAVANESE RIGHT RERENGGAN | U+A9C2 | Po, other | Javanese | |
| ꧃ | JAVANESE PADA ANDAP | U+A9C3 | Po, other | Javanese | |
| ꧄ | JAVANESE PADA MADYA | U+A9C4 | Po, other | Javanese | |
| ꧅ | JAVANESE PADA LUHUR | U+A9C5 | Po, other | Javanese | |
| ꧆ | JAVANESE PADA WINDU | U+A9C6 | Po, other | Javanese | |
| ꧇ | JAVANESE PADA PANGKAT | U+A9C7 | Po, other | Javanese | |
| ꧈ | JAVANESE PADA LINGSA | U+A9C8 | Po, other | Javanese | |
| ꧉ | JAVANESE PADA LUNGSI | U+A9C9 | Po, other | Javanese | |
| ꧊ | JAVANESE PADA ADEG | U+A9CA | Po, other | Javanese | |
| ꧋ | JAVANESE PADA ADEG ADEG | U+A9CB | Po, other | Javanese | |
| ꧌ | JAVANESE PADA PISELEH | U+A9CC | Po, other | Javanese | |
| ꧍ | JAVANESE TURNED PADA PISELEH | U+A9CD | Po, other | Javanese | |
| ꧞ | JAVANESE PADA TIRTA TUMETES | U+A9DE | Po, other | Javanese | |
| ꧟ | JAVANESE PADA ISEN-ISEN | U+A9DF | Po, other | Javanese | |
| 𑂻 | KAITHI ABBREVIATION SIGN | U+110BB | Po, other | Kaithi | |
| 𑂼 | KAITHI ENUMERATION SIGN | U+110BC | Po, other | Kaithi | |
| 𑂾 | KAITHI SECTION MARK | U+110BE | Po, other | Kaithi | |
| 𑂿 | KAITHI DOUBLE SECTION MARK | U+110BF | Po, other | Kaithi | |
| 𑃀 | KAITHI DANDA | U+110C0 | Po, other | Kaithi | |
| 𑃁 | KAITHI DOUBLE DANDA | U+110C1 | Po, other | Kaithi | |
| ಄ | KANNADA SIGN SIDDHAM | U+0C84 | Po, other | Kannada | |
| ꤯ | KAYAH LI SIGN SHYA | U+A92F | Po, other | Kayah Li | |
| 𐩐 | KHAROSHTHI PUNCTUATION DOT | U+10A50 | Po, other | Kharoshthi | |
| 𐩑 | KHAROSHTHI PUNCTUATION SMALL CIRCLE | U+10A51 | Po, other | Kharoshthi | |
| 𐩒 | KHAROSHTHI PUNCTUATION CIRCLE | U+10A52 | Po, other | Kharoshthi | |
| 𐩓 | KHAROSHTHI PUNCTUATION CRESCENT BAR | U+10A53 | Po, other | Kharoshthi | |
| 𐩔 | KHAROSHTHI PUNCTUATION MANGALAM | U+10A54 | Po, other | Kharoshthi | |
| 𐩕 | KHAROSHTHI PUNCTUATION LOTUS | U+10A55 | Po, other | Kharoshthi | |
| 𐩖 | KHAROSHTHI PUNCTUATION DANDA | U+10A56 | Po, other | Kharoshthi | |
| 𐩗 | KHAROSHTHI PUNCTUATION DOUBLE DANDA | U+10A57 | Po, other | Kharoshthi | |
| 𐩘 | KHAROSHTHI PUNCTUATION LINES | U+10A58 | Po, other | Kharoshthi | |
| ។ | KHMER SIGN KHAN | U+17D4 | Po, other | Khmer | |
| ៕ | KHMER SIGN BARIYOOSAN | U+17D5 | Po, other | Khmer | |
| ៖ | KHMER SIGN CAMNUC PII KUUH | U+17D6 | Po, other | Khmer | |
| ៘ | KHMER SIGN BEYYAL | U+17D8 | Po, other | Khmer | |
| ៙ | KHMER SIGN PHNAEK MUAN | U+17D9 | Po, other | Khmer | |
| ៚ | KHMER SIGN KOOMUUT | U+17DA | Po, other | Khmer | |
| 𑈸 | KHOJKI DANDA | U+11238 | Po, other | Khojki | |
| 𑈹 | KHOJKI DOUBLE DANDA | U+11239 | Po, other | Khojki | |
| 𑈺 | KHOJKI WORD SEPARATOR | U+1123A | Po, other | Khojki | |
| 𑈻 | KHOJKI SECTION MARK | U+1123B | Po, other | Khojki | |
| 𑈼 | KHOJKI DOUBLE SECTION MARK | U+1123C | Po, other | Khojki | |
| 𑈽 | KHOJKI ABBREVIATION SIGN | U+1123D | Po, other | Khojki | |
| ᰻ | LEPCHA PUNCTUATION TA-ROL | U+1C3B | Po, other | Lepcha | |
| ᰼ | LEPCHA PUNCTUATION NYET THYOOM TA-ROL | U+1C3C | Po, other | Lepcha | |
| ᰽ | LEPCHA PUNCTUATION CER-WA | U+1C3D | Po, other | Lepcha | |
| ᰾ | LEPCHA PUNCTUATION TSHOOK CER-WA | U+1C3E | Po, other | Lepcha | |
| ᰿ | LEPCHA PUNCTUATION TSHOOK | U+1C3F | Po, other | Lepcha | |
| ᥄ | LIMBU EXCLAMATION MARK | U+1944 | Po, other | Limbu | |
| ᥅ | LIMBU QUESTION MARK | U+1945 | Po, other | Limbu | |
| ꓾ | LISU PUNCTUATION COMMA | U+A4FE | Po, other | Lisu | |
| ꓿ | LISU PUNCTUATION FULL STOP | U+A4FF | Po, other | Lisu | |
| 𐤿 | LYDIAN TRIANGULAR MARK | U+1093F | Po, other | Lydian | |
| 𑅴 | MAHAJANI ABBREVIATION SIGN | U+11174 | Po, other | Mahajani | |
| 𑅵 | MAHAJANI SECTION MARK | U+11175 | Po, other | Mahajani | |
| 𑻷 | MAKASAR PASSIMBANG | U+11EF7 | Po, other | Makasar | |
| 𑻸 | MAKASAR END OF SECTION | U+11EF8 | Po, other | Makasar | |
| 𐫰 | MANICHAEAN PUNCTUATION STAR | U+10AF0 | Po, other | Manichaean | |
| 𐫱 | MANICHAEAN PUNCTUATION FLEURON | U+10AF1 | Po, other | Manichaean | |
| 𐫲 | MANICHAEAN PUNCTUATION DOUBLE DOT WITHIN DOT | U+10AF2 | Po, other | Manichaean | |
| 𐫳 | MANICHAEAN PUNCTUATION DOT WITHIN DOT | U+10AF3 | Po, other | Manichaean | |
| 𐫴 | MANICHAEAN PUNCTUATION DOT | U+10AF4 | Po, other | Manichaean | |
| 𐫵 | MANICHAEAN PUNCTUATION TWO DOTS | U+10AF5 | Po, other | Manichaean | |
| 𐫶 | MANICHAEAN PUNCTUATION LINE FILLER | U+10AF6 | Po, other | Manichaean | |
| 𑱰 | MARCHEN HEAD MARK | U+11C70 | Po, other | Marchen | |
| 𑱱 | MARCHEN MARK SHAD | U+11C71 | Po, other | Marchen | |
| 𖺗 | MEDEFAIDRIN COMMA | U+16E97 | Po, other | Medefaidrin | |
| 𖺘 | MEDEFAIDRIN FULL STOP | U+16E98 | Po, other | Medefaidrin | |
| 𖺙 | MEDEFAIDRIN SYMBOL AIVA | U+16E99 | Po, other | Medefaidrin | |
| 𖺚 | MEDEFAIDRIN EXCLAMATION OH | U+16E9A | Po, other | Medefaidrin | |
| ꫰ | MEETEI MAYEK CHEIKHAN | U+AAF0 | Po, other | Meetei Mayek | |
| ꫱ | MEETEI MAYEK AHANG KHUDAM | U+AAF1 | Po, other | Meetei Mayek | |
| ꯫ | MEETEI MAYEK CHEIKHEI | U+ABEB | Po, other | Meetei Mayek | |
| 𑙁 | MODI DANDA | U+11641 | Po, other | Modi | |
| 𑙂 | MODI DOUBLE DANDA | U+11642 | Po, other | Modi | |
| 𑙃 | MODI ABBREVIATION SIGN | U+11643 | Po, other | Modi | |
| ᠀ | MONGOLIAN BIRGA | U+1800 | Po, other | Mongolian | |
| ᠁ | MONGOLIAN ELLIPSIS | U+1801 | Po, other | Mongolian | |
| ᠄ | MONGOLIAN COLON | U+1804 | Po, other | Mongolian | |
| ᠇ | MONGOLIAN SIBE SYLLABLE BOUNDARY MARKER | U+1807 | Po, other | Mongolian | |
| ᠈ | MONGOLIAN MANCHU COMMA | U+1808 | Po, other | Mongolian | |
| ᠉ | MONGOLIAN MANCHU FULL STOP | U+1809 | Po, other | Mongolian | |
| ᠊ | MONGOLIAN NIRUGU | U+180A | Po, other | Mongolian | |
| 𑙠 | MONGOLIAN BIRGA WITH ORNAMENT | U+11660 | Po, other | Mongolian | |
| 𑙡 | MONGOLIAN ROTATED BIRGA | U+11661 | Po, other | Mongolian | |
| 𑙢 | MONGOLIAN DOUBLE BIRGA WITH ORNAMENT | U+11662 | Po, other | Mongolian | |
| 𑙣 | MONGOLIAN TRIPLE BIRGA WITH ORNAMENT | U+11663 | Po, other | Mongolian | |
| 𑙤 | MONGOLIAN BIRGA WITH DOUBLE ORNAMENT | U+11664 | Po, other | Mongolian | |
| 𑙥 | MONGOLIAN ROTATED BIRGA WITH ORNAMENT | U+11665 | Po, other | Mongolian | |
| 𑙦 | MONGOLIAN ROTATED BIRGA WITH DOUBLE ORNAMENT | U+11666 | Po, other | Mongolian | |
| 𑙧 | MONGOLIAN INVERTED BIRGA | U+11667 | Po, other | Mongolian | |
| 𑙨 | MONGOLIAN INVERTED BIRGA WITH DOUBLE ORNAMENT | U+11668 | Po, other | Mongolian | |
| 𑙩 | MONGOLIAN SWIRL BIRGA | U+11669 | Po, other | Mongolian | |
| 𑙪 | MONGOLIAN SWIRL BIRGA WITH ORNAMENT | U+1166A | Po, other | Mongolian | |
| 𑙫 | MONGOLIAN SWIRL BIRGA WITH DOUBLE ORNAMENT | U+1166B | Po, other | Mongolian | |
| 𑙬 | MONGOLIAN TURNED SWIRL BIRGA WITH DOUBLE ORNAMENT | U+1166C | Po, other | Mongolian | |
| 𖩮 | MRO DANDA | U+16A6E | Po, other | Mro | |
| 𖩯 | MRO DOUBLE DANDA | U+16A6F | Po, other | Mro | |
| 𑊩 | MULTANI SECTION MARK | U+112A9 | Po, other | Multani | |
| ၊ | MYANMAR SIGN LITTLE SECTION | U+104A | Po, other | Myanmar | |
| ။ | MYANMAR SIGN SECTION | U+104B | Po, other | Myanmar | |
| ၌ | MYANMAR SYMBOL LOCATIVE | U+104C | Po, other | Myanmar | |
| ၍ | MYANMAR SYMBOL COMPLETED | U+104D | Po, other | Myanmar | |
| ၎ | MYANMAR SYMBOL AFOREMENTIONED | U+104E | Po, other | Myanmar | |
| ၏ | MYANMAR SYMBOL GENITIVE | U+104F | Po, other | Myanmar | |
| ߷ | NKO SYMBOL GBAKURUNEN | U+07F7 | Po, other | N'Ko | |
| ߸ | NKO COMMA | U+07F8 | Po, other | N'Ko | |
| ߹ | NKO EXCLAMATION MARK | U+07F9 | Po, other | N'Ko | |
| 𑧢 | NANDINAGARI SIGN SIDDHAM | U+119E2 | Po, other | Nandinagari | |
| 𑑋 | NEWA DANDA | U+1144B | Po, other | Newa | |
| 𑑌 | NEWA DOUBLE DANDA | U+1144C | Po, other | Newa | |
| 𑑍 | NEWA COMMA | U+1144D | Po, other | Newa | |
| 𑑎 | NEWA GAP FILLER | U+1144E | Po, other | Newa | |
| 𑑏 | NEWA ABBREVIATION SIGN | U+1144F | Po, other | Newa | |
| 𑑚 | NEWA DOUBLE COMMA | U+1145A | Po, other | Newa | |
| 𑑛 | NEWA PLACEHOLDER MARK | U+1145B | Po, other | Newa | |
| 𑑝 | NEWA INSERTION SIGN | U+1145D | Po, other | Newa | |
| ᱾ | OL CHIKI PUNCTUATION MUCAAD | U+1C7E | Po, other | Ol Chiki | |
| ᱿ | OL CHIKI PUNCTUATION DOUBLE MUCAAD | U+1C7F | Po, other | Ol Chiki | |
| 𐏐 | OLD PERSIAN WORD DIVIDER | U+103D0 | Po, other | Old Persian | |
| 𐩿 | OLD SOUTH ARABIAN NUMERIC INDICATOR | U+10A7F | Po, other | Old South Arabian | |
| 𖬷 | PAHAWH HMONG SIGN VOS THOM | U+16B37 | Po, other | Pahawh Hmong | |
| 𖬸 | PAHAWH HMONG SIGN VOS TSHAB CEEB | U+16B38 | Po, other | Pahawh Hmong | |
| 𖬹 | PAHAWH HMONG SIGN CIM CHEEM | U+16B39 | Po, other | Pahawh Hmong | |
| 𖬺 | PAHAWH HMONG SIGN VOS THIAB | U+16B3A | Po, other | Pahawh Hmong | |
| 𖬻 | PAHAWH HMONG SIGN VOS FEEM | U+16B3B | Po, other | Pahawh Hmong | |
| 𖭄 | PAHAWH HMONG SIGN XAUS | U+16B44 | Po, other | Pahawh Hmong | |
| ꡴ | PHAGS-PA SINGLE HEAD MARK | U+A874 | Po, other | Phags-pa | |
| ꡵ | PHAGS-PA DOUBLE HEAD MARK | U+A875 | Po, other | Phags-pa | |
| ꡶ | PHAGS-PA MARK SHAD | U+A876 | Po, other | Phags-pa | |
| ꡷ | PHAGS-PA MARK DOUBLE SHAD | U+A877 | Po, other | Phags-pa | |
| 𐤟 | PHOENICIAN WORD SEPARATOR | U+1091F | Po, other | Phoenician | |
| 𐮙 | PSALTER PAHLAVI SECTION MARK | U+10B99 | Po, other | Psalter Pahlavi | |
| 𐮚 | PSALTER PAHLAVI TURNED SECTION MARK | U+10B9A | Po, other | Psalter Pahlavi | |
| 𐮛 | PSALTER PAHLAVI FOUR DOTS WITH CROSS | U+10B9B | Po, other | Psalter Pahlavi | |
| 𐮜 | PSALTER PAHLAVI FOUR DOTS WITH DOT | U+10B9C | Po, other | Psalter Pahlavi | |
| ꥟ | REJANG SECTION MARK | U+A95F | Po, other | Rejang | |
| ࠰ | SAMARITAN PUNCTUATION NEQUDAA | U+0830 | Po, other | Samaritan | |
| ࠱ | SAMARITAN PUNCTUATION AFSAAQ | U+0831 | Po, other | Samaritan | |
| ࠲ | SAMARITAN PUNCTUATION ANGED | U+0832 | Po, other | Samaritan | |
| ࠳ | SAMARITAN PUNCTUATION BAU | U+0833 | Po, other | Samaritan | |
| ࠴ | SAMARITAN PUNCTUATION ATMAAU | U+0834 | Po, other | Samaritan | |
| ࠵ | SAMARITAN PUNCTUATION SHIYYAALAA | U+0835 | Po, other | Samaritan | |
| ࠶ | SAMARITAN ABBREVIATION MARK | U+0836 | Po, other | Samaritan | |
| ࠷ | SAMARITAN PUNCTUATION MELODIC QITSA | U+0837 | Po, other | Samaritan | |
| ࠸ | SAMARITAN PUNCTUATION ZIQAA | U+0838 | Po, other | Samaritan | |
| ࠹ | SAMARITAN PUNCTUATION QITSA | U+0839 | Po, other | Samaritan | |
| ࠺ | SAMARITAN PUNCTUATION ZAEF | U+083A | Po, other | Samaritan | |
| ࠻ | SAMARITAN PUNCTUATION TURU | U+083B | Po, other | Samaritan | |
| ࠼ | SAMARITAN PUNCTUATION ARKAANU | U+083C | Po, other | Samaritan | |
| ࠽ | SAMARITAN PUNCTUATION SOF MASHFAAT | U+083D | Po, other | Samaritan | |
| ࠾ | SAMARITAN PUNCTUATION ANNAAU | U+083E | Po, other | Samaritan | |
| ꣎ | SAURASHTRA DANDA | U+A8CE | Po, other | Saurashtra | |
| ꣏ | SAURASHTRA DOUBLE DANDA | U+A8CF | Po, other | Saurashtra | |
| 𑇅 | SHARADA DANDA | U+111C5 | Po, other | Sharada | |
| 𑇆 | SHARADA DOUBLE DANDA | U+111C6 | Po, other | Sharada | |
| 𑇇 | SHARADA ABBREVIATION SIGN | U+111C7 | Po, other | Sharada | |
| 𑇈 | SHARADA SEPARATOR | U+111C8 | Po, other | Sharada | |
| 𑇍 | SHARADA SUTRA MARK | U+111CD | Po, other | Sharada | |
| 𑇛 | SHARADA SIGN SIDDHAM | U+111DB | Po, other | Sharada | |
| 𑇝 | SHARADA CONTINUATION SIGN | U+111DD | Po, other | Sharada | |
| 𑇞 | SHARADA SECTION MARK-1 | U+111DE | Po, other | Sharada | |
| 𑇟 | SHARADA SECTION MARK-2 | U+111DF | Po, other | Sharada | |
| 𑗁 | SIDDHAM SIGN SIDDHAM | U+115C1 | Po, other | Siddham | |
| 𑗂 | SIDDHAM DANDA | U+115C2 | Po, other | Siddham | |
| 𑗃 | SIDDHAM DOUBLE DANDA | U+115C3 | Po, other | Siddham | |
| 𑗄 | SIDDHAM SEPARATOR DOT | U+115C4 | Po, other | Siddham | |
| 𑗅 | SIDDHAM SEPARATOR BAR | U+115C5 | Po, other | Siddham | |
| 𑗆 | SIDDHAM REPETITION MARK-1 | U+115C6 | Po, other | Siddham | |
| 𑗇 | SIDDHAM REPETITION MARK-2 | U+115C7 | Po, other | Siddham | |
| 𑗈 | SIDDHAM REPETITION MARK-3 | U+115C8 | Po, other | Siddham | |
| 𑗉 | SIDDHAM END OF TEXT MARK | U+115C9 | Po, other | Siddham | |
| 𑗊 | SIDDHAM SECTION MARK WITH TRIDENT AND U-SHAPED ORNAMENTS | U+115CA | Po, other | Siddham | |
| 𑗋 | SIDDHAM SECTION MARK WITH TRIDENT AND DOTTED CRESCENTS | U+115CB | Po, other | Siddham | |
| 𑗌 | SIDDHAM SECTION MARK WITH RAYS AND DOTTED CRESCENTS | U+115CC | Po, other | Siddham | |
| 𑗍 | SIDDHAM SECTION MARK WITH RAYS AND DOTTED DOUBLE CRESCENTS | U+115CD | Po, other | Siddham | |
| 𑗎 | SIDDHAM SECTION MARK WITH RAYS AND DOTTED TRIPLE CRESCENTS | U+115CE | Po, other | Siddham | |
| 𑗏 | SIDDHAM SECTION MARK DOUBLE RING | U+115CF | Po, other | Siddham | |
| 𑗐 | SIDDHAM SECTION MARK DOUBLE RING WITH RAYS | U+115D0 | Po, other | Siddham | |
| 𑗑 | SIDDHAM SECTION MARK WITH DOUBLE CRESCENTS | U+115D1 | Po, other | Siddham | |
| 𑗒 | SIDDHAM SECTION MARK WITH TRIPLE CRESCENTS | U+115D2 | Po, other | Siddham | |
| 𑗓 | SIDDHAM SECTION MARK WITH QUADRUPLE CRESCENTS | U+115D3 | Po, other | Siddham | |
| 𑗔 | SIDDHAM SECTION MARK WITH SEPTUPLE CRESCENTS | U+115D4 | Po, other | Siddham | |
| 𑗕 | SIDDHAM SECTION MARK WITH CIRCLES AND RAYS | U+115D5 | Po, other | Siddham | |
| 𑗖 | SIDDHAM SECTION MARK WITH CIRCLES AND TWO ENCLOSURES | U+115D6 | Po, other | Siddham | |
| 𑗗 | SIDDHAM SECTION MARK WITH CIRCLES AND FOUR ENCLOSURES | U+115D7 | Po, other | Siddham | |
| 𝪇 | SIGNWRITING COMMA | U+1DA87 | Po, other | SignWriting | |
| 𝪈 | SIGNWRITING FULL STOP | U+1DA88 | Po, other | SignWriting | |
| 𝪉 | SIGNWRITING SEMICOLON | U+1DA89 | Po, other | SignWriting | |
| 𝪊 | SIGNWRITING COLON | U+1DA8A | Po, other | SignWriting | |
| 𝪋 | SIGNWRITING PARENTHESIS | U+1DA8B | Po, other | SignWriting | |
| ෴ | SINHALA PUNCTUATION KUNDDALIYA | U+0DF4 | Po, other | Sinhala | |
| 𐽕 | SOGDIAN PUNCTUATION TWO VERTICAL BARS | U+10F55 | Po, other | Sogdian | |
| 𐽖 | SOGDIAN PUNCTUATION TWO VERTICAL BARS WITH DOTS | U+10F56 | Po, other | Sogdian | |
| 𐽗 | SOGDIAN PUNCTUATION CIRCLE WITH DOT | U+10F57 | Po, other | Sogdian | |
| 𐽘 | SOGDIAN PUNCTUATION TWO CIRCLES WITH DOTS | U+10F58 | Po, other | Sogdian | |
| 𐽙 | SOGDIAN PUNCTUATION HALF CIRCLE WITH DOT | U+10F59 | Po, other | Sogdian | |
| 𑪚 | SOYOMBO MARK TSHEG | U+11A9A | Po, other | Soyombo | |
| 𑪛 | SOYOMBO MARK SHAD | U+11A9B | Po, other | Soyombo | |
| 𑪜 | SOYOMBO MARK DOUBLE SHAD | U+11A9C | Po, other | Soyombo | |
| 𑪞 | SOYOMBO HEAD MARK WITH MOON AND SUN AND TRIPLE FLAME | U+11A9E | Po, other | Soyombo | |
| 𑪟 | SOYOMBO HEAD MARK WITH MOON AND SUN AND FLAME | U+11A9F | Po, other | Soyombo | |
| 𑪠 | SOYOMBO HEAD MARK WITH MOON AND SUN | U+11AA0 | Po, other | Soyombo | |
| 𑪡 | SOYOMBO TERMINAL MARK-1 | U+11AA1 | Po, other | Soyombo | |
| 𑪢 | SOYOMBO TERMINAL MARK-2 | U+11AA2 | Po, other | Soyombo | |
| ᳀ | SUNDANESE PUNCTUATION BINDU SURYA | U+1CC0 | Po, other | Sundanese | |
| ᳁ | SUNDANESE PUNCTUATION BINDU PANGLONG | U+1CC1 | Po, other | Sundanese | |
| ᳂ | SUNDANESE PUNCTUATION BINDU PURNAMA | U+1CC2 | Po, other | Sundanese | |
| ᳃ | SUNDANESE PUNCTUATION BINDU CAKRA | U+1CC3 | Po, other | Sundanese | |
| ᳄ | SUNDANESE PUNCTUATION BINDU LEU SATANGA | U+1CC4 | Po, other | Sundanese | |
| ᳅ | SUNDANESE PUNCTUATION BINDU KA SATANGA | U+1CC5 | Po, other | Sundanese | |
| ᳆ | SUNDANESE PUNCTUATION BINDU DA SATANGA | U+1CC6 | Po, other | Sundanese | |
| ᳇ | SUNDANESE PUNCTUATION BINDU BA SATANGA | U+1CC7 | Po, other | Sundanese | |
| ܀ | SYRIAC END OF PARAGRAPH | U+0700 | Po, other | Syriac | |
| ܁ | SYRIAC SUPRALINEAR FULL STOP | U+0701 | Po, other | Syriac | |
| ܂ | SYRIAC SUBLINEAR FULL STOP | U+0702 | Po, other | Syriac | |
| ܃ | SYRIAC SUPRALINEAR COLON | U+0703 | Po, other | Syriac | |
| ܄ | SYRIAC SUBLINEAR COLON | U+0704 | Po, other | Syriac | |
| ܅ | SYRIAC HORIZONTAL COLON | U+0705 | Po, other | Syriac | |
| ܆ | SYRIAC COLON SKEWED LEFT | U+0706 | Po, other | Syriac | |
| ܇ | SYRIAC COLON SKEWED RIGHT | U+0707 | Po, other | Syriac | |
| ܈ | SYRIAC SUPRALINEAR COLON SKEWED LEFT | U+0708 | Po, other | Syriac | |
| ܉ | SYRIAC SUBLINEAR COLON SKEWED RIGHT | U+0709 | Po, other | Syriac | |
| ܊ | SYRIAC CONTRACTION | U+070A | Po, other | Syriac | |
| ܋ | SYRIAC HARKLEAN OBELUS | U+070B | Po, other | Syriac | |
| ܌ | SYRIAC HARKLEAN METOBELUS | U+070C | Po, other | Syriac | |
| ܍ | SYRIAC HARKLEAN ASTERISCUS | U+070D | Po, other | Syriac | |
| ᪠ | TAI THAM SIGN WIANG | U+1AA0 | Po, other | Tai Tham | |
| ᪡ | TAI THAM SIGN WIANGWAAK | U+1AA1 | Po, other | Tai Tham | |
| ᪢ | TAI THAM SIGN SAWAN | U+1AA2 | Po, other | Tai Tham | |
| ᪣ | TAI THAM SIGN KEOW | U+1AA3 | Po, other | Tai Tham | |
| ᪤ | TAI THAM SIGN HOY | U+1AA4 | Po, other | Tai Tham | |
| ᪥ | TAI THAM SIGN DOKMAI | U+1AA5 | Po, other | Tai Tham | |
| ᪦ | TAI THAM SIGN REVERSED ROTATED RANA | U+1AA6 | Po, other | Tai Tham | |
| ᪨ | TAI THAM SIGN KAAN | U+1AA8 | Po, other | Tai Tham | |
| ᪩ | TAI THAM SIGN KAANKUU | U+1AA9 | Po, other | Tai Tham | |
| ᪪ | TAI THAM SIGN SATKAAN | U+1AAA | Po, other | Tai Tham | |
| ᪫ | TAI THAM SIGN SATKAANKUU | U+1AAB | Po, other | Tai Tham | |
| ᪬ | TAI THAM SIGN HANG | U+1AAC | Po, other | Tai Tham | |
| ᪭ | TAI THAM SIGN CAANG | U+1AAD | Po, other | Tai Tham | |
| ꫞ | TAI VIET SYMBOL HO HOI | U+AADE | Po, other | Tai Viet | |
| ꫟ | TAI VIET SYMBOL KOI KOI | U+AADF | Po, other | Tai Viet | |
| 𑿿 | TAMIL PUNCTUATION END OF TEXT | U+11FFF | Po, other | Tamil | |
| ౷ | TELUGU SIGN SIDDHAM | U+0C77 | Po, other | Telugu | |
| ๏ | THAI CHARACTER FONGMAN | U+0E4F | Po, other | Thai | |
| ๚ | THAI CHARACTER ANGKHANKHU | U+0E5A | Po, other | Thai | |
| ๛ | THAI CHARACTER KHOMUT | U+0E5B | Po, other | Thai | |
| ༄ | TIBETAN MARK INITIAL YIG MGO MDUN MA | U+0F04 | Po, other | Tibetan | |
| ༅ | TIBETAN MARK CLOSING YIG MGO SGAB MA | U+0F05 | Po, other | Tibetan | |
| ༆ | TIBETAN MARK CARET YIG MGO PHUR SHAD MA | U+0F06 | Po, other | Tibetan | |
| ༇ | TIBETAN MARK YIG MGO TSHEG SHAD MA | U+0F07 | Po, other | Tibetan | |
| ༈ | TIBETAN MARK SBRUL SHAD | U+0F08 | Po, other | Tibetan | |
| ༉ | TIBETAN MARK BSKUR YIG MGO | U+0F09 | Po, other | Tibetan | |
| ༊ | TIBETAN MARK BKA- SHOG YIG MGO | U+0F0A | Po, other | Tibetan | |
| ་ | TIBETAN MARK INTERSYLLABIC TSHEG | U+0F0B | Po, other | Tibetan | |
| ༌ | TIBETAN MARK DELIMITER TSHEG BSTAR | U+0F0C | Po, other | Tibetan | |
| ། | TIBETAN MARK SHAD | U+0F0D | Po, other | Tibetan | |
| ༎ | TIBETAN MARK NYIS SHAD | U+0F0E | Po, other | Tibetan | |
| ༏ | TIBETAN MARK TSHEG SHAD | U+0F0F | Po, other | Tibetan | |
| ༐ | TIBETAN MARK NYIS TSHEG SHAD | U+0F10 | Po, other | Tibetan | |
| ༑ | TIBETAN MARK RIN CHEN SPUNGS SHAD | U+0F11 | Po, other | Tibetan | |
| ༒ | TIBETAN MARK RGYA GRAM SHAD | U+0F12 | Po, other | Tibetan | |
| ༔ | TIBETAN MARK GTER TSHEG | U+0F14 | Po, other | Tibetan | |
| ྅ | TIBETAN MARK PALUTA | U+0F85 | Po, other | Tibetan | |
| ࿐ | TIBETAN MARK BSKA- SHOG GI MGO RGYAN | U+0FD0 | Po, other | Tibetan | |
| ࿑ | TIBETAN MARK MNYAM YIG GI MGO RGYAN | U+0FD1 | Po, other | Tibetan | |
| ࿒ | TIBETAN MARK NYIS TSHEG | U+0FD2 | Po, other | Tibetan | |
| ࿓ | TIBETAN MARK INITIAL BRDA RNYING YIG MGO MDUN MA | U+0FD3 | Po, other | Tibetan | |
| ࿔ | TIBETAN MARK CLOSING BRDA RNYING YIG MGO SGAB MA | U+0FD4 | Po, other | Tibetan | |
| ࿙ | TIBETAN MARK LEADING MCHAN RTAGS | U+0FD9 | Po, other | Tibetan | |
| ࿚ | TIBETAN MARK TRAILING MCHAN RTAGS | U+0FDA | Po, other | Tibetan | |
| ⵰ | TIFINAGH SEPARATOR MARK | U+2D70 | Po, other | Tifinagh | |
| 𑓆 | TIRHUTA ABBREVIATION SIGN | U+114C6 | Po, other | Tirhuta | |
| 𐎟 | UGARITIC WORD DIVIDER | U+1039F | Po, other | Ugaritic | |
| ꘍ | VAI COMMA | U+A60D | Po, other | Vai | |
| ꘎ | VAI FULL STOP | U+A60E | Po, other | Vai | |
| ꘏ | VAI QUESTION MARK | U+A60F | Po, other | Vai | |
| 𑨿 | ZANABAZAR SQUARE INITIAL HEAD MARK | U+11A3F | Po, other | Zanabazar Square | |
| 𑩀 | ZANABAZAR SQUARE CLOSING HEAD MARK | U+11A40 | Po, other | Zanabazar Square | |
| 𑩁 | ZANABAZAR SQUARE MARK TSHEG | U+11A41 | Po, other | Zanabazar Square | |
| 𑩂 | ZANABAZAR SQUARE MARK SHAD | U+11A42 | Po, other | Zanabazar Square | |
| 𑩃 | ZANABAZAR SQUARE MARK DOUBLE SHAD | U+11A43 | Po, other | Zanabazar Square | |
| 𑩄 | ZANABAZAR SQUARE MARK LONG TSHEG | U+11A44 | Po, other | Zanabazar Square | |
| 𑩅 | ZANABAZAR SQUARE INITIAL DOUBLE-LINED HEAD MARK | U+11A45 | Po, other | Zanabazar Square | |
| 𑩆 | ZANABAZAR SQUARE CLOSING DOUBLE-LINED HEAD MARK | U+11A46 | Po, other | Zanabazar Square | |
| ࡞ | MANDAIC PUNCTUATION | U+085E | Po, other | Mandaic | |
Contenido relacionado
Lengua española
Amalarico
Japonés antiguo