
Open Shortest Path First (OSPF)
Open Shortest Path First (OSPF) o castellanizado “abrir primero el camino más corto” es un protocolo de enrutamiento para redes de Protocolo de Internet (IP). Utiliza un algoritmo de enrutamiento de estado de enlace (LSR) y cae en el grupo de protocolos de puerta de enlace interior (IGP), que opera dentro de un solo sistema autónomo (AS).
OSPF recopila información sobre el estado de los enlaces de los enrutadores disponibles y construye un mapa de topología de la red. La topología se presenta como una tabla de enrutamiento a la capa de Internet para enrutar paquetes por su dirección IP de destino. OSPF admite redes de Protocolo de Internet versión 4 (IPv4) y Protocolo de Internet versión 6 (IPv6) y admite el modelo de direccionamiento de enrutamiento entre dominios sin clase (CIDR).
OSPF se usa ampliamente en redes de grandes empresas. IS-IS, otro protocolo basado en LSR, es más común en redes de grandes proveedores de servicios.
Diseñado originalmente en la década de 1980, OSPF está definido para IPv4 en la versión 2 del protocolo por RFC 2328 (1998). Las actualizaciones para IPv6 se especifican como OSPF Versión 3 en RFC 5340 (2008). OSPF admite el modelo de direccionamiento de enrutamiento entre dominios sin clases (CIDR).
Conceptos
OSPF es un protocolo de puerta de enlace interior (IGP) para enrutar paquetes de Protocolo de Internet (IP) dentro de un solo dominio de enrutamiento, como un sistema autónomo. Recopila información de estado de enlace de los enrutadores disponibles y construye un mapa de topología de la red. La topología se presenta como una tabla de enrutamiento a la capa de Internet que enruta los paquetes basándose únicamente en su dirección IP de destino.
OSPF detecta cambios en la topología, como fallas de enlace, y converge en una nueva estructura de enrutamiento sin bucles en segundos. Calcula el árbol de ruta más corta para cada ruta utilizando un método basado en el algoritmo de Dijkstra. Las políticas de enrutamiento OSPF para construir una tabla de enrutamiento se rigen por métricas de enlace asociadas con cada interfaz de enrutamiento. Los factores de costo pueden ser la distancia de un enrutador (tiempo de ida y vuelta), el rendimiento de datos de un enlace o la disponibilidad y confiabilidad del enlace, expresados como números simples sin unidades. Esto proporciona un proceso dinámico de balanceo de carga de tráfico entre rutas de igual costo.
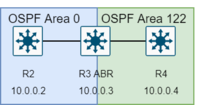
OSPF divide la red en áreas de enrutamiento para simplificar la administración y optimizar el tráfico y la utilización de recursos. Las áreas se identifican mediante números de 32 bits, expresados simplemente en decimal o, a menudo, en la misma notación decimal de puntos basada en octetos que se utiliza para las direcciones IPv4. Por convención, el área 0 (cero), o 0.0.0.0, representa el núcleo o la columna vertebralárea de una red OSPF. Si bien las identificaciones de otras áreas se pueden elegir a voluntad, los administradores a menudo seleccionan la dirección IP de un enrutador principal en un área como identificador de área. Cada área adicional debe tener una conexión con el área de red troncal OSPF. Tales conexiones son mantenidas por un enrutador de interconexión, conocido como enrutador de borde de área (ABR). Un ABR mantiene bases de datos de estado de enlace separadas para cada área a la que sirve y mantiene rutas resumidas para todas las áreas de la red.
OSPF se ejecuta sobre el Protocolo de Internet versión 4 (IPv4) y el Protocolo de Internet versión 6 (IPv6), pero no utiliza un protocolo de transporte, como UDP o TCP. Encapsula sus datos directamente en paquetes IP con el número de protocolo 89. Esto contrasta con otros protocolos de enrutamiento, como el Protocolo de información de enrutamiento (RIP) y el Protocolo de puerta de enlace fronteriza (BGP). OSPF implementa sus propias funciones de detección y corrección de errores de transporte. OSPF utiliza el direccionamiento de multidifusión para distribuir información de rutas dentro de un dominio de difusión. Reserva las direcciones de multidifusión 224.0.0.5 (IPv4) y FF02::5 (IPv6) para todos los enrutadores SPF/link state (AllSPFRouters) y 224.0.0.6 (IPv4) y FF02::6 (IPv6) para todos los enrutadores designados (AllDRouters). Para las redes que no son de transmisión, las disposiciones especiales para la configuración facilitan el descubrimiento de vecinos.Los paquetes IP de multidifusión OSPF nunca atraviesan enrutadores IP, nunca viajan más de un salto. Por lo tanto, el protocolo puede considerarse un protocolo de capa de enlace, pero a menudo también se atribuye a la capa de aplicación en el modelo TCP/IP. Tiene una función de enlace virtual que se puede usar para crear un túnel de adyacencia a través de múltiples saltos. OSPF sobre IPv4 puede operar de forma segura entre enrutadores, utilizando opcionalmente una variedad de métodos de autenticación para permitir que solo los enrutadores confiables participen en el enrutamiento. OSPFv3 (IPv6) se basa en la seguridad estándar del protocolo IPv6 (IPsec) y no tiene métodos de autenticación internos.
Para enrutar el tráfico IP de multidifusión, OSPF admite el protocolo Multicast Open Shortest Path First (MOSPF). Cisco no incluye MOSPF en sus implementaciones OSPF. La multidifusión independiente de protocolo (PIM) junto con OSPF u otros IGP está ampliamente implementada.
OSPF versión 3 introduce modificaciones a la implementación IPv4 del protocolo. A excepción de los enlaces virtuales, todos los intercambios de vecinos utilizan direcciones locales de enlace IPv6 exclusivamente. El protocolo IPv6 se ejecuta por enlace, en lugar de basarse en la subred. Toda la información del prefijo IP se eliminó de los anuncios de estado de enlace y del paquete de descubrimiento de saludo, lo que hace que OSPFv3 sea esencialmente independiente del protocolo. A pesar del direccionamiento IP ampliado a 128 bits en IPv6, las identificaciones de área y enrutador aún se basan en números de 32 bits.
Relaciones de enrutadores
OSPF admite redes complejas con múltiples enrutadores, incluidos enrutadores de respaldo, para equilibrar la carga de tráfico en múltiples enlaces a otras subredes. Los enrutadores vecinos en el mismo dominio de transmisión o en cada extremo de un enlace punto a punto se comunican entre sí a través del protocolo OSPF. Los enrutadores forman adyacencias cuando se han detectado entre sí. Esta detección se inicia cuando un enrutador se identifica a sí mismo en un paquete de protocolo de saludo. Tras el reconocimiento, esto establece un estado bidireccional y la relación más básica. Los enrutadores en una red Ethernet o Frame Relay seleccionan un enrutador designado (DR) y un enrutador designado de respaldo(BDR) que actúan como un concentrador para reducir el tráfico entre enrutadores. OSPF utiliza modos de transmisión de unidifusión y multidifusión para enviar paquetes de "hola" y actualizaciones de estado de enlace.
Como protocolo de enrutamiento de estado de enlace, OSPF establece y mantiene relaciones de vecinos para intercambiar actualizaciones de enrutamiento con otros enrutadores. La tabla de relaciones de vecinos se denomina base de datos de adyacencia.. Dos enrutadores OSPF son vecinos si son miembros de la misma subred y comparten la misma ID de área, máscara de subred, temporizadores y autenticación. En esencia, la vecindad OSPF es una relación entre dos enrutadores que les permite verse y entenderse, pero nada más. Los vecinos OSPF no intercambian ninguna información de enrutamiento: los únicos paquetes que intercambian son paquetes de saludo. Las adyacencias OSPF se forman entre vecinos seleccionados y les permiten intercambiar información de enrutamiento. Dos enrutadores primero deben ser vecinos y solo entonces pueden convertirse en adyacentes. Dos enrutadores se vuelven adyacentes si al menos uno de ellos es un enrutador designado o un enrutador designado de respaldo (en redes de tipo multiacceso), o están interconectados por un tipo de red punto a punto o punto a multipunto. Para formar una relación de vecindad entre, las interfaces utilizadas para formar la relación deben estar en la misma área OSPF. Si bien una interfaz puede configurarse para pertenecer a múltiples áreas, esto generalmente no se practica. Cuando se configura en una segunda área, una interfaz debe configurarse como una interfaz secundaria.
Modos de operación
El OSPF puede tener diferentes modos de operación en las siguientes configuraciones en una interfaz/red:
- Difusión (predeterminado), cada enrutador se anuncia a sí mismo mediante la multidifusión periódica de paquetes de saludo y el uso de enrutadores designados. Uso de multidifusión
- Acceso múltiple sin transmisión, con el uso de enrutadores designados. Puede necesitar una configuración estática. Los paquetes se envían como unidifusión,
- Punto a multipunto, donde OSPF trata a los vecinos como enlaces punto a punto. No se elige ningún enrutador designado. Uso de multidifusión. Se envían paquetes de saludo separados a cada vecino.
- Punto a punto. Cada enrutador se anuncia a sí mismo mediante la multidifusión periódica de paquetes de saludo. No se elige ningún enrutador designado. La interfaz puede ser IP sin numerar (sin asignarle una dirección IP única). Uso de multidifusión.
- Enlaces virtuales, los paquetes se envían como unicast. Solo se puede configurar en un área no troncal (pero no en un área auxiliar). Los puntos finales deben ser ABR, los enlaces virtuales se comportan como conexiones punto a punto no numeradas. El costo de una ruta dentro del área entre los dos enrutadores se agrega al enlace.
- Enlace virtual sobre encapsulación de enrutamiento genérico (GRE). Dado que OSPF no admite enlaces virtuales para otras áreas que no sean la red troncal. Una solución es usar GRE sobre el área de la red troncal. Tenga en cuenta que si se usa la misma IP o ID de enrutador, el enlace crea dos rutas de igual costo hacia el destino.
- Enlace simulado Un enlace que conecta sitios que pertenecen a la misma área OSPF y comparten un enlace de puerta trasera OSPF a través de la red troncal VPN MPLS.
Máquina de estado de adyacencia
Cada enrutador OSPF dentro de una red se comunica con otros enrutadores vecinos en cada interfaz de conexión para establecer los estados de todas las adyacencias. Cada secuencia de comunicación de este tipo es una conversación separada identificada por el par de ID de enrutador de los vecinos que se comunican. RFC 2328 especifica el protocolo para iniciar estas conversaciones (protocolo de saludo) y para establecer adyacencias completas (paquetes de descripción de base de datos, paquetes de solicitud de estado de enlace). Durante su curso, cada conversación del enrutador pasa por un máximo de ocho condiciones definidas por una máquina de estado:
- Inactivo: el estado inactivo representa el estado inicial de una conversación cuando no se ha intercambiado ni retenido información entre los enrutadores con el protocolo Hello.
- Intento: el estado de intento es similar al estado inactivo, excepto que un enrutador está intentando establecer una conversación con otro enrutador, pero solo se usa en redes de acceso múltiple sin transmisión (NBMA).
- Init: el estado init indica que se recibió un paquete de saludo de un vecino, pero el enrutador no ha establecido una conversación bidireccional.
- Bidireccional: el estado bidireccional indica el establecimiento de una conversación bidireccional entre dos enrutadores. Este estado precede inmediatamente al establecimiento de la adyacencia. Este es el estado más bajo de un enrutador que puede considerarse como DR.
- Inicio de intercambio (exstart): el estado de exstart es el primer paso de la adyacencia de dos enrutadores.
- Intercambio: en el estado de intercambio, un enrutador envía su información de base de datos de estado de enlace al vecino adyacente. En este estado, un enrutador puede intercambiar todos los paquetes del protocolo de enrutamiento OSPF.
- Cargando: en el estado de carga, un enrutador solicita los anuncios de estado de enlace (LSA) más recientes de su vecino descubierto en el estado anterior.
- Completo: el estado completo concluye la conversación cuando los enrutadores están completamente adyacentes y el estado aparece en todos los LSA de red y enrutador. Las bases de datos de estado de enlace de los vecinos están completamente sincronizadas.
áreas OSPF
Una red se divide en áreas OSPF que son agrupaciones lógicas de hosts y redes. Un área incluye su enrutador de conexión que tiene una interfaz para cada enlace de red conectado. Cada enrutador mantiene una base de datos de estado de enlace separada para el área cuya información puede ser resumida hacia el resto de la red por el enrutador de conexión. Por lo tanto, la topología de un área se desconoce fuera del área. Esto reduce el tráfico de enrutamiento entre partes de un sistema autónomo.
OSPF puede manejar miles de enrutadores con más preocupación por alcanzar la capacidad de la tabla de base de información de reenvío (FIB) cuando la red contiene muchas rutas y dispositivos de gama baja. Los enrutadores modernos de gama baja tienen un gigabyte completo de RAM que les permite manejar muchos enrutadores en un área 0. Muchos recursos se refieren a las guías OSPF de hace más de 20 años, donde fue impresionante tener 64 MB de RAM.
Las áreas se identifican de forma única con números de 32 bits. Los identificadores de área se escriben comúnmente en la notación decimal de puntos, familiar del direccionamiento IPv4. Sin embargo, no son direcciones IP y pueden duplicar, sin conflicto, cualquier dirección IPv4. Los identificadores de área para implementaciones de IPv6 (OSPFv3) también usan identificadores de 32 bits escritos en la misma notación. Cuando se omite el formato de puntos, la mayoría de las implementaciones expanden el área 1 al identificador de área 0.0.0.1, pero se sabe que algunas lo expanden como 1.0.0.0.
Varios proveedores (Cisco, Allied Telesis, Juniper, Alcatel-Lucent, Huawei, Quagga) implementan áreas totalmente rechonchas y NSSA totalmente rechonchas para áreas rechonchas y no tan rechonchas. Aunque no están cubiertos por los estándares RFC, muchos los consideran características estándar en las implementaciones OSPF.
OSPF define varios tipos de área:
- Columna vertebral
- No troncal/regular
- Talón,
- totalmente rechoncho
- no tan rechoncho
- Totalmente no tan rechoncho
- Tránsito.
área de la columna vertebral

El área de red troncal (también conocida como área 0 o área 0.0.0.0) forma el núcleo de una red OSPF. Todas las demás áreas están conectadas a él, ya sea directamente oa través de otros enrutadores. OSPF requiere esto para evitar bucles de enrutamiento. El enrutamiento entre áreas ocurre a través de enrutadores conectados al área de la red troncal ya sus propias áreas asociadas. Es la estructura lógica y física del 'dominio OSPF' y se adjunta a todas las áreas distintas de cero en el dominio OSPF. Tenga en cuenta que en OSPF el término Enrutador de límite del sistema autónomo (ASBR) es histórico, en el sentido de que muchos dominios OSPF pueden coexistir en el mismo sistema autónomo visible en Internet, RFC 1996.
Todas las áreas OSPF deben conectarse al área de red troncal. Esta conexión, sin embargo, puede ser a través de un enlace virtual. Por ejemplo, suponga que el área 0.0.0.1 tiene una conexión física con el área 0.0.0.0. Suponga además que el área 0.0.0.2 no tiene conexión directa con la red troncal, pero esta área tiene una conexión con el área 0.0.0.1. El área 0.0.0.2 puede usar un enlace virtual a través del área de tránsito 0.0.0.1 para llegar a la red troncal. Para ser un área de tránsito, un área debe tener el atributo de tránsito, por lo que no puede ser stubby de ninguna manera.
área habitual
Un área normal es simplemente un área que no es de red troncal (distinta de cero) sin una función específica, que genera y recibe LSA de resumen y externas. El área de la columna vertebral es un tipo especial de dicha área.
Área de tránsito

Un área de tránsito es un área con dos o más enrutadores de borde OSPF y se utiliza para pasar el tráfico de red de un área adyacente a otra. El área de tránsito no origina este tráfico y no es el destino de dicho tráfico. El área troncal es un tipo especial de área de tránsito.Ejemplos de esto:
- área de la columna vertebral
- En OSPF requiere que todas las áreas estén conectadas directamente al área de la red troncal, de lo contrario, se deben usar enlaces virtuales, y el área que transita se llama área de tránsito.
área de trozo
En los paquetes de saludo, la bandera E no está alta, indicación "Enrutamiento externo: no apto"
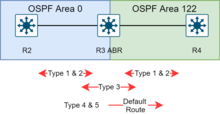
Un área auxiliar es un área que no recibe anuncios de ruta externos al AS y el enrutamiento desde dentro del área se basa completamente en una ruta predeterminada. Un ABR elimina los LSA de tipo 4, 5 de los enrutadores internos, les envía una ruta predeterminada de 0.0.0.0 y se convierte en una puerta de enlace predeterminada. Esto reduce el LSDB y el tamaño de la tabla de enrutamiento para los enrutadores internos.
Los proveedores de sistemas han implementado modificaciones al concepto básico de área stub, como el área totalmente stub (TSA) y el área no tan stub (NSSA), ambas una extensión en el equipo de enrutamiento de Cisco Systems.
Área totalmente rechoncha
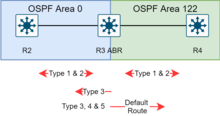
Un área totalmente rechoncha es similar a un área restringida. Sin embargo, esta área no permite rutas sumarias además de no tener rutas externas, es decir, las rutas interáreas (IA) no se resumen en áreas totalmente stubby. La única forma de enrutar el tráfico fuera del área es una ruta predeterminada, que es el único LSA de tipo 3 anunciado en el área. Cuando solo hay una ruta fuera del área, el procesador de ruta debe tomar menos decisiones de enrutamiento, lo que reduce la utilización de recursos del sistema.Ocasionalmente, se dice que una TSA puede tener solo un ABR.
Zona no tan rechoncha

En los paquetes de saludo, la bandera N se establece en alto, indicación "NSSA: compatible"
Un área no tan rechoncha (NSSA) es un tipo de área auxiliar que puede importar rutas externas del sistema autónomo y enviarlas a otras áreas, pero aún así no puede recibir rutas externas AS de otras áreas.NSSA es una extensión de la característica del área de rutas internas que permite la inyección de rutas externas de forma limitada en el área de rutas internas. Un estudio de caso simula una NSSA sorteando el problema del Stub Area de no poder importar direcciones externas. Visualiza las siguientes actividades: el ASBR importa direcciones externas con un LSA tipo 7, el ABR convierte un LSA tipo 7 a tipo 5 y lo inunda a otras áreas, el ABR actúa como un "ASBR" para otras áreas. Los ASBR no toman LSA tipo 5 y luego se convierten a LSA tipo 7 para el área.
Área totalmente no tan rechoncha

Además de la funcionalidad estándar de una NSSA, la NSSA totalmente rechoncha es una NSSA que adquiere los atributos de una TSA, lo que significa que las rutas resumidas de tipo 3 y 4 no se inundan en este tipo de área. También es posible declarar un área tanto totalmente rechoncha como no tan rechoncha, lo que significa que el área recibirá solo la ruta predeterminada del área 0.0.0.0, pero también puede contener un enrutador de límite de sistema autónomo (ASBR) que acepta información de enrutamiento y la inyecta en el área local, y desde el área local en el área 0.0.0.0.La redistribución en un área NSSA crea un tipo especial de LSA conocido como tipo 7, que solo puede existir en un área NSSA. Un NSSA ASBR genera este LSA y un enrutador NSSA ABR lo traduce a LSA tipo 5 que se propaga al dominio OSPF.
Una subsidiaria recién adquirida es un ejemplo de dónde podría ser adecuado que un área sea simultáneamente no tan rechoncha y totalmente rechoncha si el lugar práctico para colocar un ASBR está en el borde de un área totalmente rechoncha. En tal caso, el ASBR envía señales externas al área totalmente rechoncha y están disponibles para los altavoces OSPF dentro de esa área. En la implementación de Cisco, las rutas externas se pueden resumir antes de inyectarlas en el área totalmente rechoncha. En general, el ASBR no debe anunciar el incumplimiento en la TSA-NSSA, aunque esto puede funcionar con un diseño y una operación extremadamente cuidadosos, para los casos especiales limitados en los que dicho anuncio tiene sentido.
Al declarar el área totalmente stubby como NSSA, ninguna ruta externa desde la red troncal, excepto la ruta predeterminada, ingresa al área que se está discutiendo. Los externos llegan al área 0.0.0.0 a través de la TSA-NSSA, pero ninguna ruta distinta de la ruta predeterminada ingresa a la TSA-NSSA. Los enrutadores en TSA-NSSA envían todo el tráfico al ABR, excepto a las rutas anunciadas por el ASBR.
Tipos de enrutadores
OSPF define las siguientes categorías superpuestas de enrutadores:Enrutador interno (IR)Un enrutador interno tiene todas sus interfaces pertenecientes a la misma área.Enrutador de borde de área (ABR)Un enrutador de borde de área es un enrutador que conecta una o más áreas a la red troncal principal. Se considera miembro de todas las áreas a las que está conectado. Un ABR mantiene varias instancias de la base de datos de estado de enlace en la memoria, una para cada área a la que está conectado ese enrutador.Enrutador de red troncal (BR)Un enrutador de red troncal tiene una interfaz con el área de red troncal. Los enrutadores de red troncal también pueden ser enrutadores de área, pero no es necesario que lo sean.Enrutador de límite de sistema autónomo (ASBR)Un enrutador de límite de sistema autónomo es un enrutador que está conectado mediante más de un protocolo de enrutamiento y que intercambia información de enrutamiento con sistemas autónomos de enrutadores. Los ASBR normalmente también ejecutan un protocolo de enrutamiento exterior (por ejemplo, BGP) o usan rutas estáticas, o ambos. Un ASBR se utiliza para distribuir rutas recibidas de otros AS externos a través de su propio sistema autónomo. Un ASBR crea LSA externas para direcciones externas y las inunda en todas las áreas a través de ABR. Los enrutadores en otras áreas usan ABR como próximos saltos para acceder a direcciones externas. Luego, los ABR reenvían paquetes al ASBR que anuncia las direcciones externas.
El tipo de enrutador es un atributo de un proceso OSPF. Un enrutador físico dado puede tener uno o más procesos OSPF. Por ejemplo, un enrutador que está conectado a más de un área y que recibe rutas de un proceso BGP conectado a otro AS, es tanto un enrutador de borde de área como un enrutador de límite de sistema autónomo.
Cada enrutador tiene un identificador, habitualmente escrito en el formato decimal con puntos (por ejemplo, 1.2.3.4) de una dirección IP. Este identificador debe establecerse en cada instancia OSPF. Si no se configura explícitamente, la dirección IP lógica más alta se duplicará como el identificador del enrutador. Sin embargo, dado que el identificador del enrutador no es una dirección IP, no tiene que ser parte de ninguna subred enrutable en la red y, a menudo, no lo es para evitar confusiones.
Red no punto a punto

En redes (misma subred) con más de 2 enrutadores OSPF como sistema de enrutador designado (DR) y enrutador designado de respaldo (BDR), se utiliza para reducir el tráfico de red al proporcionar una fuente para actualizaciones de enrutamiento. Esto se hace usando direcciones de multidifusión:
- 224.0.0.5, todos los enrutadores de la topología escucharán en esa dirección de multidifusión.
- 224.0.0.6, DR y BDR escucharán en esa dirección de multidifusión.
DR y BDR mantienen una tabla de topología completa de la red y envían las actualizaciones a los otros enrutadores a través de multidifusión. Todos los enrutadores en un segmento de red de acceso múltiple formarán una relación esclavo/maestro con el DR y el BDR. Formarán adyacencias únicamente con DR y BDR. Cada vez que un enrutador envía una actualización, la envía a DR y BDR en la dirección de multidifusión 224.0.0.6. El DR luego enviará la actualización a todos los demás enrutadores en el área, a la dirección de multidifusión 224.0.0.5. De esta manera, todos los enrutadores no tienen que actualizarse constantemente entre sí y, en cambio, pueden obtener todas sus actualizaciones de una sola fuente. El uso de multidifusión reduce aún más la carga de la red. Los DR y BDR siempre se configuran/se eligen en las redes de transmisión OSPF. Los DR también se pueden elegir en redes NBMA (Acceso múltiple sin transmisión) como Frame Relay o ATM. Los DR o BDR no se eligen en enlaces punto a punto (como una conexión WAN punto a punto) porque los dos enrutadores a cada lado del enlace deben volverse completamente adyacentes y el ancho de banda entre ellos no se puede optimizar más. Los enrutadores DR y no DR evolucionan de 2 vías a relaciones de adyacencia completa mediante el intercambio de DD, Solicitud y Actualización.
Enrutador designado
Un enrutador designado (DR) es la interfaz de enrutador elegida entre todos los enrutadores en un segmento de red de acceso múltiple en particular, generalmente se supone que es de acceso múltiple de transmisión. Es posible que se necesiten técnicas especiales, a menudo dependientes del proveedor, para admitir la función DR en medios de acceso múltiple que no son de transmisión (NBMA). Por lo general, es aconsejable configurar los circuitos virtuales individuales de una subred NBMA como líneas punto a punto individuales; las técnicas utilizadas dependen de la implementación.
Enrutador designado de respaldo
Un enrutador designado de respaldo (BDR) es un enrutador que se convierte en el enrutador designado si el enrutador designado actual tiene un problema o falla. El BDR es el enrutador OSPF con la segunda prioridad más alta en el momento de la última elección.
Un enrutador determinado puede tener algunas interfaces designadas (DR) y otras designadas de respaldo (BDR) y otras no designadas. Si ningún enrutador es un DR o un BDR en una subred determinada, primero se elige el BDR y luego se lleva a cabo una segunda elección para el DR.
Elección del enrutador designado
El DR se elige en base a los siguientes criterios predeterminados:
- Si la configuración de prioridad en un enrutador OSPF se establece en 0, eso significa que NUNCA puede convertirse en un DR o BDR.
- Cuando un DR falla y el BDR se hace cargo, hay otra elección para ver quién se convierte en el BDR de reemplazo.
- El enrutador que envía los paquetes Hello con la prioridad más alta gana la elección.
- Si dos o más enrutadores se vinculan con la configuración de prioridad más alta, gana el enrutador que envía el saludo con el RID (ID de enrutador) más alto. NOTA: un RID es la dirección IP lógica (bucle invertido) más alta configurada en un enrutador, si no se configura una dirección IP lógica/bucle invertido, entonces el enrutador usa la dirección IP más alta configurada en sus interfaces activas (por ejemplo, 192.168.0.1 sería mayor que 10.1.1.2).
- Por lo general, el enrutador con el segundo número de prioridad más alto se convierte en el BDR.
- Los valores de prioridad oscilan entre 0 y 255, y un valor más alto aumenta las posibilidades de convertirse en DR o BDR.
- Si un enrutador OSPF de mayor prioridad se conecta después de que se haya realizado la elección, no se convertirá en DR o BDR hasta que (al menos) el DR y el BDR fallen.
- Si el DR actual 'baja', el BDR actual se convierte en el nuevo DR y se lleva a cabo una nueva elección para encontrar otro BDR. Si el nuevo DR luego 'cae' y el DR original ahora está disponible, el BDR elegido previamente se convertirá en DR.
Mensajes de protocolo
| 1 | 1 | 2 | 4 | 4 | 2 | 2 | 8 | Variable |
|---|---|---|---|---|---|---|---|---|
| Encabezado de 24 bytes | Datos | |||||||
| Versión 2 | Escribe | Longitud del paquete | Identificación del enrutador | ID de área | Suma de verificación | AuTipo | Autenticación |
| 1 | 1 | 2 | 4 | 4 | 2 | 1 | 1 | Variable |
|---|---|---|---|---|---|---|---|---|
| Encabezado de 16 bytes | Datos | |||||||
| Versión 3 | Escribe | Longitud del paquete | Identificación del enrutador | ID de área | Suma de verificación | ID de instancia | Reservado |
| 1 | 1 | 2 | 4 | 4 | 2 | 2 | 8 | Variable |
|---|---|---|---|---|---|---|---|---|
| Encabezado 24 bytes | Datos | |||||||
| Versión 2 | Escribe | Longitud del paquete | Identificación del enrutador | ID de área | Suma de verificación | AuTipo | Autenticación |
A diferencia de otros protocolos de enrutamiento, OSPF no transporta datos a través de un protocolo de transporte, como el Protocolo de datagramas de usuario (UDP) o el Protocolo de control de transmisión (TCP). En su lugar, OSPF forma datagramas IP directamente, empaquetándolos usando el número de protocolo 89 para el campo Protocolo IP. OSPF define cinco tipos de mensajes diferentes, para varios tipos de comunicación. Se pueden enviar varios paquetes por trama.
OSFP utiliza los siguientes tipos de paquetes 5:
- Hola
- Descripción de la base de datos
- Solicitud de estado de enlace
- Actualización del estado del enlace
- Reconocimiento del estado del enlace
Hola paquete
| 24 | 4 | 2 | 1 | 1 | 4 | 4 | 4 | 4 |
|---|---|---|---|---|---|---|---|---|
| Encabezamiento | ||||||||
| Máscara de red | Intervalo de saludo | Opciones | Prioridad del enrutador | Intervalo muerto del enrutador | ID de enrutador designado | ID de enrutador designado de respaldo | ID de vecino |
Los mensajes de saludo de OSPF se utilizan como una forma de saludo, para permitir que un enrutador descubra otros enrutadores adyacentes en sus enlaces y redes locales. Los mensajes establecen relaciones entre dispositivos vecinos (llamados adyacencias) y comunican parámetros clave sobre cómo se utilizará OSPF en el sistema o área autónomos. Durante el funcionamiento normal, los enrutadores envían mensajes de saludo a sus vecinos a intervalos regulares (el intervalo de saludo); Si un enrutador deja de recibir mensajes de saludo de un vecino, después de un período determinado (el intervalo muerto), el enrutador asumirá que el vecino se ha caído.
Descripción de la base de datos DBD
| 16 o 24 | 2 | 1 | 1 | 1 | 4 | Variable |
|---|---|---|---|---|---|---|
| Encabezamiento | ||||||
| Interfaz MTU | Intervalo de saludo | Opciones | Banderas | Número de secuencia DD | Encabezados LSA |
Los mensajes de descripción de la base de datos contienen descripciones de la topología del sistema o área autónomos. Transmiten el contenido de la base de datos de estado de enlace (LSDB) para el área de un enrutador a otro. La comunicación de una LSDB grande puede requerir el envío de varios mensajes al tener el dispositivo de envío designado como dispositivo maestro y enviar mensajes en secuencia, con el esclavo (destinatario de la información de la LSDB) respondiendo con reconocimientos.
Paquetes de estado de enlace
Solicitud de estado de enlace (LSR)Los mensajes de solicitud de estado de enlace son utilizados por un enrutador para solicitar información actualizada sobre una parte de la LSDB de otro enrutador. El mensaje especifica los enlaces para los cuales el dispositivo solicitante desea información más actualizada.
Actualización del estado del enlace (LSU)Los mensajes de actualización del estado de los enlaces contienen información actualizada sobre el estado de ciertos enlaces en la LSDB. Se envían en respuesta a un mensaje de solicitud de estado de enlace, y también se transmiten o multidifunden mediante enrutadores de forma regular. Su contenido se utiliza para actualizar la información en los LSDB de los enrutadores que los reciben.
Reconocimiento del estado del enlace (LSAck)Los mensajes de reconocimiento de estado de enlace brindan confiabilidad al proceso de intercambio de estado de enlace, al reconocer explícitamente la recepción de un mensaje de actualización de estado de enlace.
| tipo LS | nombre de LS | Generado por | Descripción |
|---|---|---|---|
| 1 | Enrutador-LSA | Cada enrutador interno dentro de un área | 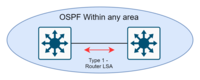 El ID de estado de enlace del LSA de tipo 1 es el ID del enrutador de origen. Enrutadores-LSA, describa los siguientes tipos de interfaces:Conexión punto a punto a otro routerConexión a una red de tránsitoConexión a una red stub (Reservado en v3)enlace virtual El ID de estado de enlace del LSA de tipo 1 es el ID del enrutador de origen. Enrutadores-LSA, describa los siguientes tipos de interfaces:Conexión punto a punto a otro routerConexión a una red de tránsitoConexión a una red stub (Reservado en v3)enlace virtual |
| 2 | LSA de red | El doctor |  Originado para transmisiones y redes NBMA por el enrutador designado. Este LSA contiene la lista de enrutadores conectados a la red. El ID de estado de enlace del LSA de tipo 2 es la dirección de interfaz IP del DR. Originado para transmisiones y redes NBMA por el enrutador designado. Este LSA contiene la lista de enrutadores conectados a la red. El ID de estado de enlace del LSA de tipo 2 es la dirección de interfaz IP del DR. |
| 3 | Resumen-LSA | El ABR |  Los LSA de resumen de tipo 3 describen rutas a redes.Para informar a otras áreas sobre enrutadores entre áreas. Estas rutas también se pueden resumir. Los LSA de resumen de tipo 3 describen rutas a redes.Para informar a otras áreas sobre enrutadores entre áreas. Estas rutas también se pueden resumir. |
| 4 | ASBR-resumen | El ABR | El tipo 4 describe rutas a enrutadores de límite AS más allá de su área.El enrutador de borde de área (ABR) genera este LSA para informar a otros enrutadores en el dominio OSPF, que el enrutador coincidente es un enrutador de límite de sistema autónomo (ASBR), de modo que los LSA externos (Tipo 5/Tipo 7) que envió pueden ser correctamente resuelto fuera de su propia área. |
| 5 | AS-externo-LSA | El ASBR |  Tipo 5 Estos describen rutas anunciadas por ASBR.Los LSA contienen información importada a OSPF desde otros procesos de enrutamiento. Junto con el Tipo 4 describen su camino hacia una ruta externa. Tipo 5 Estos describen rutas anunciadas por ASBR.Los LSA contienen información importada a OSPF desde otros procesos de enrutamiento. Junto con el Tipo 4 describen su camino hacia una ruta externa. |
| 7 | Anuncios de estado de enlace externo de la NSSA | El ASBR, dentro de un área no tan rechoncha | Los LSA tipo 7 son idénticos a los LSA tipo 5.Los LSA de tipo 7 solo se inundan dentro de la NSSA.En el enrutador de borde de área, los LSA de tipo 7 seleccionados se traducen en LSA de tipo 5 y se inundan en la red troncal. |
| 8 | Enlace-LSA (v3) | Cada enrutador interno dentro de un enlace | Proporcione la dirección local de enlace del enrutador local a todos los demás enrutadores en la red local. |
| 9 | LSA de prefijo intraárea (v3) | Cada enrutador interno dentro de un área | Reemplaza parte de la funcionalidad de los Router-LSA; segmento de red auxiliar o un segmento de red de transporte adjunto. |
Tipos de área OSPF v2 y LSA aceptados
No todos los tipos de área usan todos los LSA. A continuación se muestra una matriz de LSA aceptados.
| dentro de una sola área | Interarea | |||||
|---|---|---|---|---|---|---|
| tipo de área | LSA 1 - enrutador | LSA 2 - red | LSA 7 - NSSA externo | LSA 3 - resumen de la red | LSA 4 - Resumen ASBR | LSA 5 - AS externo |
| Columna vertebral | Sí | Sí | No, convertido en Tipo 5 por el ABR | Sí | Sí | Sí |
| no troncal | Sí | Sí | No, convertido en Tipo 5 por el ABR | Sí | Sí | Sí |
| Talón | Sí | Sí | No, ruta predeterminada | Sí | No, ruta predeterminada | No, ruta predeterminada |
| totalmente rechoncho | Sí | Sí | No, ruta predeterminada | No, ruta predeterminada | No, ruta predeterminada | No, ruta predeterminada |
| no tan rechoncho | Sí | Sí | Sí | Sí | No, ruta predeterminada | No, ruta predeterminada |
| Totalmente no tan rechoncho | Sí | Sí | Sí | No, ruta predeterminada | No, ruta predeterminada | No, ruta predeterminada |
Métricas de enrutamiento
OSPF usa el costo de la ruta como su métrica de enrutamiento básica, que fue definida por el estándar para no equipararse a ningún valor estándar como la velocidad, por lo que el diseñador de la red podría elegir una métrica importante para el diseño. En la práctica, se determina comparando la velocidad de la interfaz con un ancho de banda de referencia para el proceso OSPF. El costo se determina dividiendo el ancho de banda de referencia por la velocidad de la interfaz (aunque el costo de cualquier interfaz se puede anular manualmente). Si un ancho de banda de referencia se establece en '10000', entonces un enlace de 10 Gbit/s tendrá un costo de 1. Cualquier velocidad inferior a 1 se redondea a 1. Aquí hay una tabla de ejemplo que muestra la métrica de enrutamiento o 'cálculo de costo ' en una interfaz.
- Tipo-1 LSA tiene un tamaño de campo de 16 bits (65.535 en decimal)
- El LSA de tipo 3 tiene un tamaño de campo de 24 bits (16 777 216 en decimal)
| Velocidad de interfaz | costo del enlace | Usos | |
|---|---|---|---|
| Predeterminado (100 Mbit/s) | 200 Gbit/s | ||
| 200 Gbit/s | 1 | 1 | SFP-DD |
| 40 Gbit/s | 1 | 5 | QSFP+ |
| 25 Gbit/s | 1 | 8 | SFP28 |
| 10 Gbit/s | 1 | 20 | 10 GigE, común en centros de datos |
| 5 Gbit/s | 1 | 40 | NBase-T, enrutadores Wi-Fi |
| 1 Gbit/s | 1 | 200 | puerto gigabit común |
| 100 Mbit/s | 1 | 2000 | puerto de gama baja |
| 10 Mbit/s | 10 | 20000 | Velocidad de los 90. |
OSPF es un protocolo de capa 3: si un conmutador de capa 2 está entre los dos dispositivos que ejecutan OSPF, un lado puede negociar una velocidad diferente del otro lado. Esto puede crear un enrutamiento asimétrico en el enlace (el enrutador 1 al enrutador 2 podría costar '1' y la ruta de retorno podría costar '10'), lo que puede tener consecuencias no deseadas.
Las métricas, sin embargo, solo son directamente comparables cuando son del mismo tipo. Se reconocen cuatro tipos de métricas. En preferencia decreciente, estos tipos son (por ejemplo, una ruta dentro del área siempre se prefiere a una ruta externa, independientemente de la métrica):
- intraárea
- Inter-área
- Tipo externo 1, que incluye tanto el costo de la ruta externa como la suma de los costos de la ruta interna al ASBR que anuncia la ruta,
- Tipo externo 2, cuyo valor es únicamente el del costo del camino externo,
OSPF v3
OSPF versión 3 introduce modificaciones a la implementación IPv4 del protocolo. A pesar de la expansión de las direcciones a 128 bits en IPv6, las identificaciones de área y enrutador siguen siendo números de 32 bits.
Cambios de alto nivel
- A excepción de los enlaces virtuales, todos los intercambios de vecinos utilizan direcciones locales de enlace IPv6 exclusivamente. El protocolo IPv6 se ejecuta por enlace, en lugar de basarse en la subred.
- Toda la información del prefijo IP se eliminó de los anuncios de estado de enlace y del paquete de descubrimiento de saludo, lo que hace que OSPFv3 sea esencialmente independiente del protocolo.
- Tres alcances de inundación separados para LSA:
- Ámbito de enlace local: LSA se inunda solo en el enlace local y no más.
- Alcance del área: LSA se inunda en una sola área OSPF.
- Alcance AS: LSA se inunda en todo el dominio de enrutamiento.
- Uso de direcciones locales de enlace IPv6, para descubrimiento de vecinos, configuración automática.
- La autenticación se ha movido al encabezado de autenticación de IP
Cambios introducidos en OSPF v3, luego respaldados por proveedores a v2
- Soporte explícito para múltiples instancias por enlace
Cambios de formato de paquete
- El número de versión OSPF cambió a 3
- Del encabezado LSA, se ha eliminado el campo de opciones.
- En los paquetes de saludo y la descripción de la base de datos, el campo de opciones se cambia de 16 a 24 bits.
- En el paquete de saludo, se eliminó la información de la dirección. Se ha añadido el ID de la interfaz.
- En los LSA de enrutador, se han agregado dos bits de opciones, el "bit R" y el "bit V6".
- "R-bit": permite que los hosts de hosts múltiples participen en el protocolo de enrutamiento.
- "V6-bit": especializa el R-bit.
- Agregue "ID de instancia", que permite múltiples instancias de protocolo OSPF en la misma interfaz lógica.
Cambios en el formato LSA
- El campo de tipo de LSA se cambia a 16 bits.
- Agregue soporte para manejar tipos de LSA desconocidos
- Se utilizan tres bits para codificar el alcance de inundación.
- Con IPv6, las direcciones en las LSA se expresan como prefijo y longitud de prefijo.
- En las LSA de enrutador y las LSA de red, se elimina la información de la dirección.
- Los LSA de enrutador y los LSA de red se hacen independientes del protocolo de red.
- Se agrega un nuevo tipo de LSA, link-LSA, que proporciona la dirección local del enlace del enrutador a todos los demás enrutadores conectados a la interfaz lógica, proporciona una lista de prefijos IPv6 para asociar con el enlace y puede enviar información que refleje las capacidades del enrutador..
- Los LSA de resumen de tipo 3 de LSA se han renombrado como "LSA de prefijo entre áreas".
- Resumen de LSA tipo 4 Los LSA se han renombrado como "inter-area-router-LSA".
- Se agrega Intra-area-prefix-LSA, un LSA que lleva toda la información del prefijo IPv6.
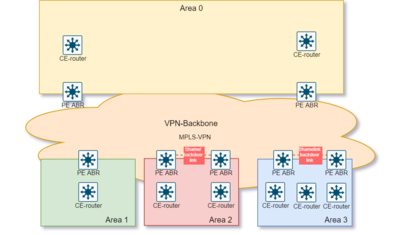
OSPF sobre MPLS-VPN
| Escribe | Tipo de campo | subvalor | nombre |
|---|---|---|---|
| AS de dos octetos | 0x00 | 0x05 | identificador de dominio OSPF |
| AS de cuatro octetos | 0x02 | 0x05 | identificador de dominio OSPF |
| dirección IPv4 | 0x01 | 0x05 | identificador de dominio OSPF |
| dirección IPv4 | 0x01 | 0x07 | Id. de ruta OSPF |
| Opaco | 0x03 | 0x06 | Tipo de ruta OSPF |
| 4 bytes | 1 byte | 1 byte |
|---|---|---|
| número de área | tipo de ruta | Opciones |
Un cliente puede usar OSPF sobre una MPLS-VPN, donde el proveedor de servicios usa BGP o RIP como su protocolo de puerta de enlace interior. Cuando se usa OSPF sobre MPLS-VPN, la red troncal VPN se convierte en parte del área 0 de la red troncal OSPF. En todas las áreas, se ejecutan copias aisladas del IGP.
ventajas:
- La MPLS-VPN es transparente para el enrutamiento estándar OSPF del cliente.
- El equipo del cliente solo necesita ser compatible con OSPF.
- Reduzca la necesidad de túneles (Encapsulación de enrutamiento genérico, IPsec, protección de cables) para usar OSPF.
Para lograr esto, se utiliza una redistribución OSPF-BGP no estándar. Todas las rutas OSPF conservan el tipo y la métrica de LSA de origen. Para evitar bucles, se utiliza un bit DN opcional en las LSA para indicar que ya se ha enviado una ruta desde el extremo del proveedor hasta el equipo del cliente.
Extensiones OSPF
Ingeniería de tráfico
OSPF-TE es una extensión de OSPF que amplía la expresividad para permitir la ingeniería de tráfico y el uso en redes que no son IP. Usando OSPF-TE, se puede intercambiar más información sobre la topología usando LSA opaco que lleva elementos de tipo-longitud-valor. Estas extensiones permiten que OSPF-TE funcione completamente fuera de banda de la red del plano de datos. Esto significa que también se puede utilizar en redes que no sean IP, como las redes ópticas.
OSPF-TE se usa en redes GMPLS como un medio para describir la topología sobre la cual se pueden establecer rutas GMPLS. GMPLS utiliza su propia configuración de ruta y protocolos de reenvío, una vez que tiene el mapa de red completo.
En el Protocolo de reserva de recursos (RSVP), OSPF-TE se utiliza para registrar e inundar las reservas de ancho de banda señaladas por RSVP para rutas de conmutación de etiquetas dentro de la base de datos de estado de enlace.
Enrutamiento óptico
Los documentos RFC 3717 funcionan en el enrutamiento óptico para IP basado en extensiones a OSPF e IS-IS.
Multidifusión Abrir la ruta más corta primero
El protocolo Multicast Open Shortest Path First (MOSPF) es una extensión de OSPF para admitir el enrutamiento de multidifusión. MOSPF permite que los enrutadores compartan información sobre membresías de grupos.
OSPF en redes de transmisión y no transmisión
En las redes de difusión de acceso múltiple, la adyacencia de vecinos se forma dinámicamente utilizando paquetes de saludo de multidifusión a 224.0.0.5. Un DR y BDR se eligen normalmente y funcionan normalmente.
Para las redes de acceso múltiple que no son de transmisión (NBMA), se definen los siguientes dos modos oficiales:
- no retransmitido
- punto a multipunto
Cisco ha definido los siguientes tres modos adicionales para OSPF en topologías NBMA:
- punto a multipunto sin difusión
- transmisión
- punto a punto
Implementaciones notables
- Allied Telesis implementa OSPFv2 y OSPFv3 en Allied Ware Plus (AW+)
- Arista Networks implementa OSPFv2 y OSPFv3
- BIRD implementa OSPFv2 y OSPFv3
- Cisco IOS y NX-OS
- cisco meraki
- D-Link implementa OSPFv2 en el enrutador de servicios unificados.
- FTOS de Dell implementa OSPFv2 y OSPFv3
- ExtremoXOS
- GNU Zebra, una suite de enrutamiento GPL para sistemas similares a Unix compatibles con OSPF
- Enebro junos
- NetWare implementa OSPF en su módulo de enrutamiento multiprotocolo.
- OpenBSD incluye OpenOSPFD, una implementación de OSPFv2.
- Quagga, una bifurcación de GNU Zebra para sistemas tipo Unix
- FRRouting, el sucesor de Quagga
- XORP, una suite de enrutamiento que implementa RFC2328 (OSPFv2) y RFC2740 (OSPFv3) para IPv4 e IPv6
- Windows NT 4.0 Server, Windows 2000 Server y Windows Server 2003 implementaron OSPFv2 en el Servicio de enrutamiento y acceso remoto, aunque la funcionalidad se eliminó en Windows Server 2008.
Aplicaciones
OSPF es un protocolo de enrutamiento ampliamente implementado que puede hacer converger una red en unos segundos y garantizar rutas sin bucles. Tiene muchas características que permiten la imposición de políticas sobre la propagación de rutas que pueden ser apropiadas para mantener locales, para compartir la carga y para la importación selectiva de rutas. IS-IS, por el contrario, se puede ajustar para una sobrecarga más baja en una red estable, el tipo más común en los ISP que en las redes empresariales. Hay algunos accidentes históricos que hicieron de IS-IS el IGP preferido para los ISP, pero los ISP de hoy en día bien pueden optar por utilizar las características de las implementaciones ahora eficientes de OSPF, después de considerar primero las ventajas y desventajas de IS-IS en entornos de proveedores de servicios..
OSPF puede proporcionar una mejor carga compartida en enlaces externos que otros IGP. Cuando la ruta predeterminada a un ISP se inyecta en OSPF desde múltiples ASBR como una ruta externa Tipo I y se especifica el mismo costo externo, otros enrutadores irán al ASBR con el menor costo de ruta desde su ubicación. Esto se puede ajustar aún más ajustando el costo externo. Si la ruta predeterminada de diferentes ISP se inyecta con diferentes costos externos, como una ruta externa Tipo II, la predeterminada de menor costo se convierte en la salida principal y la de mayor costo se convierte en la de respaldo solamente.
El único factor limitante real que puede obligar a los principales ISP a seleccionar IS-IS sobre OSPF es si tienen una red con más de 850 enrutadores.
Contenido relacionado
Lista de nombres de informes de la OTAN para submarinos
Procesamiento de señales de audio
Arquitectura multinivel