
InterPro
InterPro es una base de datos de familias de proteínas, dominios de proteínas y sitios funcionales en los que las características identificables encontradas en proteínas conocidas se pueden aplicar a nuevas secuencias de proteínas para caracterizarlas funcionalmente.
El contenido de InterPro consiste en firmas de diagnóstico y las proteínas con las que coinciden significativamente. Las firmas consisten en modelos (tipos simples, como expresiones regulares o más complejos, como los modelos ocultos de Markov) que describen familias, dominios o sitios de proteínas. Los modelos se construyen a partir de secuencias de aminoácidos de familias o dominios conocidos y posteriormente se utilizan para buscar secuencias desconocidas (como las que surgen de la secuenciación del genoma novedoso) para clasificarlas. Cada una de las bases de datos miembros de InterPro contribuye a un nicho diferente, desde clasificaciones basadas en estructuras de muy alto nivel (SUPERFAMILY y CATH-Gene3D) hasta clasificaciones de subfamilias bastante específicas (PRINTS y PANTHER).
La intención de InterPro es proporcionar una ventanilla única para la clasificación de proteínas, donde todas las firmas producidas por las diferentes bases de datos miembros se colocan en entradas dentro de la base de datos de InterPro. Las firmas que representan dominios, sitios o familias equivalentes se colocan en la misma entrada y las entradas también pueden estar relacionadas entre sí. Siempre que sea posible, se asocia información adicional, como una descripción, nombres coherentes y términos de ontología genética (GO), a cada entrada.
Datos contenidos en Inter Pro
InterPro contiene tres entidades principales: proteínas, firmas (también denominadas "métodos" o "modelos") y entradas. Las proteínas de UniProtKB son también las entidades proteicas centrales de InterPro. La información sobre qué firmas coinciden significativamente con estas proteínas se calcula a medida que UniProtKB publica las secuencias y estos resultados se ponen a disposición del público (ver más abajo). Las coincidencias de firmas con proteínas son las que determinan cómo se integran las firmas en las entradas de InterPro: superposición comparativa de conjuntos de proteínas coincidentes y la ubicación de las firmas. Las coincidencias en las secuencias se utilizan como indicadores de relación. En InterPro sólo se integran las firmas que se consideran de calidad suficiente. A partir de la versión 81.0 (lanzada el 21 de agosto de 2020), las entradas de InterPro anotaron el 73,9 % de los residuos encontrados en UniProtKB con otro 9,2 % anotado por firmas que están pendientes de integración.

InterPro también incluye datos para variantes de empalme y las proteínas contenidas en las bases de datos UniParc y UniMES.
Bases de datos de los miembros del consorcio InterPro
Las firmas de InterPro provienen de 13 "bases de datos de miembros", que se enumeran a continuación.
- CATH-Gene3D
- Describe familias de proteínas y arquitecturas de dominio en genomas completos. Las familias proteínas se forman usando un algoritmo de agrupación de Markov, seguido de agrupación multi-enlaces según la identidad de secuencia. Mapping of predicted structure and sequence domains is undertaken using hidden Markov models library representing CATH and Pfam domains. La anotación funcional se proporciona a las proteínas de múltiples recursos. La predicción funcional y el análisis de arquitecturas de dominio está disponible en el sitio web Gene3D.
- CDD
- La base de datos de dominio conservado es un recurso de anotación de proteínas que consiste en una colección de modelos de alineación de secuencias múltiples anotados para dominios antiguos y proteínas de longitud completa. Estos están disponibles como matrices de puntuación específicas (PSSM) para la identificación rápida de dominios conservados en secuencias de proteínas a través de RPS-BLAST.
- HAMAP
- Se apoya en la Anotación Automatizada de alta calidad y Manual de Proteomes microbianos. Los perfiles HAMAP son creados manualmente por curadores expertos que identifican proteínas que forman parte de proteínas bacterianas, arqueales y plastoides bien conservadas (es decir, cloroplastos, cianelles, apicoplastos, plastoides no fotosintéticos) proteínas familias o subfamilias.
- MobiDB
- MobiDB es una base de datos que anota trastorno intrínseco en proteínas.
- PANTHER
- PANTHER es una gran colección de familias de proteínas que han sido subdivididas en subfamilias funcionalmente relacionadas, utilizando experiencia humana. Estas subfamilias modelan la divergencia de funciones específicas dentro de las familias de proteínas, permitiendo una asociación más precisa con función (funcional molecular curado por humanos y clasificaciones de procesos biológicos y diagramas de vías), así como la inferencia de aminoácidos importantes para la especificidad funcional. Los modelos de Markov ocultos (HMM) se construyen para cada familia y subfamilia para clasificar secuencias de proteínas adicionales.
- Pfam
- Es una gran colección de alineaciones de secuencia múltiple y modelos ocultos de Markov que abarcan muchos dominios y familias de proteínas comunes.
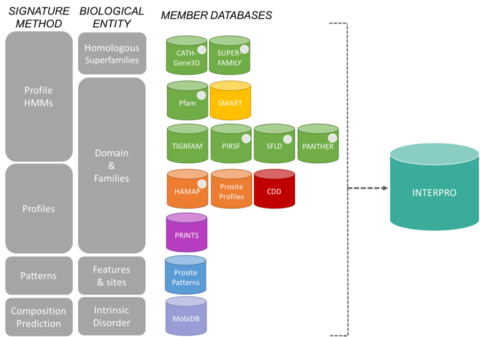
Las 13 bases de datos miembros del consorcio InterPro agrupadas por su método de construcción de firmas y la entidad biológica en la que se centran. - PIRSF
- El sistema de clasificación de proteínas es una red con múltiples niveles de diversidad de secuencias de superfamilias a subfamilias que refleja la relación evolutiva de proteínas y dominios de longitud completa. La unidad primaria de clasificación PIRSF es la familia homeomorfa, cuyos miembros son homologosos (evolucionados desde un ancestro común) y homeomórficos (compartiendo la similitud de secuencia de longitud completa y una arquitectura de dominio común).
- PRINTS
- PRINTS es un compendio de huellas de proteínas. Una huella dactilar es un grupo de motivos conservados utilizados para caracterizar a una familia de proteínas; su poder diagnóstico es refinado por el escaneo iterativo de UniProt. Normalmente los motivos no se solapan, pero se separan a lo largo de una secuencia, aunque pueden ser contiguos en el espacio 3D. Las huellas dactilares pueden codificar pliegues de proteínas y funcionalidades más flexibles y poderosamente que los motivos individuales, su potencia diagnóstica completa derivando del contexto mutuo proporcionado por los vecinos motivos.
- PROSITE
- PROSITE es una base de datos de familias y dominios de proteínas. Consiste en sitios, patrones y perfiles biológicamente significativos que ayudan a identificar de forma fiable a qué familia de proteínas conocidas (si hay) pertenece una nueva secuencia.
- SMART
- Herramienta de investigación de arquitectura modular simple Permite la identificación y anotación de dominios genéticamente móviles y el análisis de arquitecturas de dominio. Más de 800 familias de dominio encontradas en las proteínas de señalización, extracelulares y asociadas a la cromatina son detectables. Estos dominios están ampliamente anotados con respecto a distribuciones filoticas, clase funcional, estructuras terciarias y residuos funcionalmente importantes.
- SUPERFAMILY
- SUPERFAMILY es una biblioteca de modelos de perfil ocultos Markov que representan todas las proteínas de estructura conocida. La biblioteca se basa en la clasificación SCOP de proteínas: cada modelo corresponde a un dominio SCOP y tiene como objetivo representar a toda la superfamilia SCOP a la que pertenece el dominio. SUPERFAMILY ha sido utilizado para llevar a cabo tareas estructurales a todos los genomas completamente secuenciados.
- SFLD
- Una clasificación jerárquica de enzimas que relaciona características específicas de secuencia-estructura a capacidades químicas específicas.
- TIGRFAMs
- TIGRFAMs es una colección de familias de proteínas, con alineaciones de secuencia múltiple curadas, modelos ocultos de Markov (HMMs) y anotación, que proporciona una herramienta para identificar proteínas funcionalmente relacionadas basadas en la homología de secuencia. Las entradas que son "equivalogs" grupo de proteínas homologosas que se conservan con respecto a la función.

Tipos de datos
InterPro consta de siete tipos de datos proporcionados por diferentes miembros del consorcio:
| Tipo de datos | Descripción | Contribuir bases de datos |
|---|---|---|
| InterPro Entries | Dominios estructurales y/o funcionales de proteínas predicho utilizando una o más firmas | Todas las 13 bases de datos |
| Firmas de la base de datos de los miembros | Firmas de bases de datos de miembros. Estas incluyen firmas integradas en InterPro, y aquellas que no son | Todas las 13 bases de datos |
| Proteína | Secuencias de proteínas | UniProtKB (Swiss-Prot y TrEMBL) |
| Proteome | Colección de proteínas que pertenecen a un solo organismo | UniProtKB |
| Estructura | Estructuras tridimensionales de proteínas | PDBe |
| Taxonomía | Información taxonómica de proteínas | UniProtKB |
| Set | Grupos de familias relacionadas con la evolución | Pfam, CDD |

Tipos de entrada InterPro
Las entradas de InterPro se pueden dividir en cinco tipos:
- Homologous Superfamily: Un grupo de proteínas que comparten un origen evolutivo común como se ve en sus similitudes estructurales, incluso si sus secuencias no son muy similares. Estas entradas sólo son proporcionadas específicamente por dos bases de datos miembros: CATH-Gene3D y SUPERFAMILY.
- Familia: Un grupo de proteínas que tienen un origen evolutivo común determinado a través de similitudes estructurales, funciones relacionadas o homología secuencial.
- Dominio: Una unidad distinta en una proteína con una función, estructura o secuencia particular.
- Repito: Una secuencia de aminoácidos, generalmente no más de 50 aminoácidos, que tienden a repetir muchas veces en una proteína.
- Sitio: Una breve secuencia de aminoácidos donde se conserva al menos un aminoácido. Estos incluyen sitios de modificación post-traducción, sitios conservados, sitios de unión y sitios activos.
Acceso
La base de datos está disponible para búsquedas basadas en texto y secuencias a través de un servidor web, y para descarga a través de FTP anónimo. Al igual que otras bases de datos de EBI, es de dominio público, ya que su contenido puede ser utilizado "por cualquier individuo y para cualquier propósito". InterPro tiene como objetivo publicar datos al público cada 8 semanas, generalmente dentro de un día después de la publicación UniProtKB de las mismas proteínas.
Interpro interfaz de programación de aplicaciones (API)
InterPro proporciona una API para acceso programático a todas las entradas de InterPro y sus entradas relacionadas en formato Json. Hay seis puntos finales principales para la API correspondientes a los diferentes tipos de datos de InterPro: entrada, proteína, estructura, taxonomía, proteoma y conjunto.
InterProScan
InterProScan es un paquete de software que permite a los usuarios escanear secuencias con firmas de bases de datos de miembros. Los usuarios pueden utilizar este software de escaneo de firmas para caracterizar funcionalmente nuevas secuencias de nucleótidos o proteínas. InterProScan se utiliza con frecuencia en proyectos genómicos para obtener una prueba de "primer paso" caracterización del genoma de interés. A diciembre de 2020, la versión pública de InterProScan (v5.x) utiliza una arquitectura basada en Java. Actualmente, el paquete de software solo es compatible con un sistema operativo Linux de 64 bits.
También se puede acceder a InterProScan, junto con muchas otras herramientas bioinformáticas de EMBL-EBI, mediante programación utilizando las API de servicios web RESTful y SOAP.
Véase también
- Protein family
- Dominio de la función desconocida
- Motivo de secuencia
Referencias
- ^ Blum M, Chang HY, Chuguransky S, Grego T, Kandasaamy S, Mitchell A, et al. (Noviembre 2020). "La base de datos de dominios y familias de proteínas InterPro: 20 años". Nucleic Acids Research. 49 (D1): D344–D354. doi:10.1093/nar/gkaa977. PMC 7778928. PMID 33156333.
- ^ Hunter S, Jones P, Mitchell A, Apweiler R, Attwood TK, Bateman A, et al. (enero de 2012). "InterPro en 2011: nuevos desarrollos en la base de datos de predicción familiar y de dominio". Nucleic Acids Research. 40 (Détabase issue): D306-12. doi:10.1093/nar/gkr948. PMC 3245097. PMID 22096229.
- ^ Apweiler R, Attwood TK, Bairoch A, Bateman A, Birney E, Biswas M, et al. (enero de 2001). "La base de datos InterPro, un recurso de documentación integrado para familias de proteínas, dominios y sitios funcionales". Nucleic Acids Research. 29 (1): 37–40. doi:10.1093/nar/29.1.37. PMC 29841. PMID 11125043.
- ^ Apweiler R, Attwood TK, Bairoch A, Bateman A, Birney E, Biswas M, et al. (diciembre de 2000). "InterPro - un recurso de documentación integrado para familias de proteínas, dominios y sitios funcionales". Bioinformática. 16 (12): 1145–50. doi:10.1093/bioinformática/16.12.1145. PMID 11159333.
- ^ a b Blum, Matthias; Chang, Hsin-Yu; Chuguransky, Sara; Grego, Tiago; Kandasaamy, Swaathi; Mitchell, Alex; Nuka, Gift; Paysan-Lafosse, Typhaine; Qureshi, Matloob; Raj, Shriya; Richardson, Lorna (2020-11-06). "La base de datos de dominios y familias de proteínas InterPro: 20 años". Nucleic Acids Research. 49 (D1): D344–D354. doi:10.1093/nar/gkaa977. ISSN 0305-1048. PMC 7778928. PMID 33156333.
- ^ EMBL-EBI. "¿De dónde vienen los datos? tención InterPro. Retrieved 2020-12-04.
- ^ EMBL-EBI. "InterPro tipos de entrada Silencio InterPro". Retrieved 2020-12-04.
- ^ "Términos de Uso para los Servicios EMBL-EBI ← Instituto Europeo de Bioinformática".
- ^ "¿Cómo descargar datos InterPro? — InterPro Documentation". interpro-documentación.readthedocs.io. Retrieved 2020-12-04.
- ^ Quevillon E, Silventoinen V, Pillai S, Harte N, Mulder N, Apweiler R, López R (julio de 2005). "InterProScan: identificador de dominios de proteínas" (Texto completo gratuito). Nucleic Acids Research. 33 (Problema del servidor web): W116-20. doi:10.1093/nar/gki442. PMC 1160203. PMID 15980438.
- ^ Lander ES, Linton LM, Birren B, Nusbaum C, Zody MC, Baldwin J, et al. (Febrero 2001). "Secuenciación interior y análisis del genoma humano" (PDF). Naturaleza. 409 (6822): 860-921. Bibcode:2001Natur.409..860L. doi:10.1038/35057062. PMID 11237011.
- ^ Holt RA, Subramanian GM, Halpern A, Sutton GG, Charlab R, Nusskern DR, et al. (octubre de 2002). "La secuencia genoma del mosquito de malaria Anopheles gambiae". Ciencia. 298 (5591): 129–49. Bibcode:2002Sci...298..129H. CiteSeerX 10.1.1.149.9058. doi:10.1126/ciencia.1076181. PMID 12364791. S2CID 4512225.
- ^ Jones P, Binns D, Chang HY, Fraser M, Li W, McAnulla C, et al. (mayo de 2014). "InterProScan 5: clasificación de función de proteínas a escala genoma". Bioinformática. 30 (9): 1236–40. doi:10.1093/bioinformática/btu031. PMC 3998142. PMID 24451626.
- ^ Madeira F, Park YM, Lee J, Buso N, Gur T, Madhusoodanan N, et al. (Julio 2019). "Las herramientas de búsqueda y análisis de secuencias EMBL-EBI API en 2019". Nucleic Acids Research. 47 (W1): W636-W641. doi:10.1093/nar/gkz268. PMC 6602479. PMID 30976793.
Enlaces externos
- Sitio oficial — servidor web
Bioinformática | |
|---|---|
| Bases de datos |
|
| Software |
|
| Otros |
|
| Instituciones |
|
| Organizaciones |
|
| Reuniones |
|
| Formatos de archivo |
|
| Temas relacionados |
|
| |