
Estructura secundaria de proteínas

Estructura secundaria de proteína es la conformación espacial local del esqueleto polipeptídico excluyendo las cadenas laterales. Los dos elementos estructurales secundarios más comunes son las hélices alfa y las láminas beta, aunque también se producen giros beta y bucles omega. Los elementos de la estructura secundaria típicamente se forman espontáneamente como un intermedio antes de que la proteína se pliegue en su estructura terciaria tridimensional.
La estructura secundaria se define formalmente por el patrón de enlaces de hidrógeno entre los átomos de hidrógeno amino y oxígeno carboxilo en la columna vertebral del péptido. La estructura secundaria se puede definir alternativamente en función del patrón regular de ángulos diédricos de la columna vertebral en una región particular de la gráfica de Ramachandran, independientemente de si tiene los enlaces de hidrógeno correctos.
El concepto de estructura secundaria fue introducido por primera vez por Kaj Ulrik Linderstrøm-Lang en Stanford en 1952. Otros tipos de biopolímeros, como los ácidos nucleicos, también poseen estructuras secundarias características.
Tipos
| Atributo de geometría | α-helix | 310 helix | π-helix |
|---|---|---|---|
| Residuos por turno | 3.6 | 3.0 | 4.4 |
| Traducción por residuo | 1.5 Å (0.15 nm) | 2.0 Å (0,20 nm) | 1.1 Å (0.11 nm) |
| Radius of helix | 2.3 Å (0,23 nm) | 1.9 Å (0.19 nm) | 2.8 Å (0,28 nm) |
| Pitch | 5.4 Å (0,54 nm) | 6.0 Å (0,60 nm) | 4.8 Å (0,48 nm) |
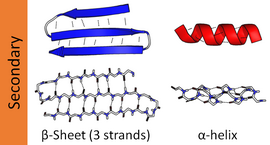
Las estructuras secundarias más comunes son las hélices alfa y las láminas beta. Se calcula que otras hélices, como la hélice 310 y la hélice π, tienen patrones de enlaces de hidrógeno energéticamente favorables, pero rara vez se observan en proteínas naturales, excepto en los extremos de las hélices α debido al empaquetamiento desfavorable de la columna vertebral en el centro de la hélice. Otras estructuras extendidas, como la hélice de poliprolina y la hoja alfa, son raras en las proteínas en estado nativo, pero a menudo se supone que son importantes intermediarios del plegamiento de proteínas. Los giros cerrados y los bucles sueltos y flexibles unen las zonas más "regulares" elementos de estructura secundaria. La espiral aleatoria no es una verdadera estructura secundaria, pero es la clase de conformaciones que indican una ausencia de estructura secundaria regular.
Los aminoácidos varían en su capacidad para formar los diversos elementos de la estructura secundaria. La prolina y la glicina a veces se conocen como "rompedores de hélice" porque interrumpen la regularidad de la conformación del esqueleto helicoidal α; sin embargo, ambos tienen habilidades conformacionales inusuales y se encuentran comúnmente en turnos. Los aminoácidos que prefieren adoptar conformaciones helicoidales en las proteínas incluyen metionina, alanina, leucina, glutamato y lisina ("MALEK" en códigos de 1 letra de aminoácidos); por el contrario, los grandes residuos aromáticos (triptófano, tirosina y fenilalanina) y los aminoácidos ramificados en Cβ (isoleucina, valina y treonina) prefieren adoptar conformaciones de cadena β. Sin embargo, estas preferencias no son lo suficientemente fuertes como para producir un método confiable para predecir la estructura secundaria solo a partir de la secuencia.
Se cree que las vibraciones colectivas de baja frecuencia son sensibles a la rigidez local dentro de las proteínas, lo que revela que las estructuras beta son genéricamente más rígidas que las alfa o las proteínas desordenadas. Las mediciones de dispersión de neutrones han conectado directamente la característica espectral a ~ 1 THz con los movimientos colectivos de la estructura secundaria de la proteína GFP de barril beta.
Los patrones de enlaces de hidrógeno en las estructuras secundarias pueden estar significativamente distorsionados, lo que dificulta la determinación automática de la estructura secundaria. Hay varios métodos para definir formalmente la estructura secundaria de la proteína (p. ej., DSSP, DEFINE, STRIDE, ScrewFit, SST).
Clasificación DSSP

El Diccionario de Estructura Secundaria de Proteínas, abreviado DSSP, se usa comúnmente para describir la estructura secundaria de proteínas con códigos de una sola letra. La estructura secundaria se asigna en base a patrones de enlaces de hidrógeno como los propuestos inicialmente por Pauling et al. en 1951 (antes de que se hubiera determinado experimentalmente cualquier estructura proteica). Hay ocho tipos de estructura secundaria que define DSSP:
- G = helix de 3 vueltas (310 helix). Residuos de longitud mínima 3.
- H = helix de 4 vueltas (helix alfa). Residuos de longitud mínima 4.
- I = Helix de 5 vueltas (helix de π). Residuos de longitud mínima 5.
- T = giro unido al hidrógeno (3, 4 o 5 vueltas)
- E = hebra extendida en conformación paralela y/o antiparalela β-pieza. Residuos de longitud mínima 2.
- B = residuos en aislado β-bridge (single pair β-sheet formación de bonos de hidrógeno)
- S = curva (la única asignación no basada en el hidrógeno).
- C = bobina (residuos que no están en ninguna de las conformaciones anteriores).
'Bobina' a menudo se codifica como ' ' (espacio), C (bobina) o '–' (estrellarse). Se requiere que las hélices (G, H e I) y las conformaciones de hoja tengan una longitud razonable. Esto significa que 2 residuos adyacentes en la estructura primaria deben formar el mismo patrón de enlaces de hidrógeno. Si el patrón de enlaces de hidrógeno de la hélice o la hoja es demasiado corto, se designan como T o B, respectivamente. Existen otras categorías de asignación de estructuras secundarias de proteínas (giros pronunciados, bucles Omega, etc.), pero se usan con menos frecuencia.
La estructura secundaria se define mediante enlaces de hidrógeno, por lo que la definición exacta de un enlace de hidrógeno es fundamental. La definición estándar de enlace de hidrógeno para la estructura secundaria es la de DSSP, que es un modelo puramente electrostático. Asigna cargas de ±q1 ≈ 0,42e al carbono carbonílico y al oxígeno, respectivamente, y cargas de ±q2 ≈ 0.20e a la amida de hidrógeno y nitrógeno, respectivamente. La energía electrostática es
- E=q1q2()1rON+1rCH− − 1rOH− − 1rCN)⋅ ⋅ 332kcal/mol.{displaystyle E=q_{1}q_{2}left({frac {1}{r_{mathrm {}}}+{frac {1}{r_{mathrm {CH}}-{frac} {1} {fn} {fnMicroc} {1} {r_{mathrm {}}}right)cdot 332{text{ kcal/mol}}}}

Según DSSP, existe un enlace de hidrógeno si y solo si E es inferior a −0,5 kcal/mol (−2,1 kJ/mol). Aunque la fórmula DSSP es una aproximación relativamente tosca de la energía física del enlace de hidrógeno, generalmente se acepta como una herramienta para definir la estructura secundaria.
Clasificación SST
SST es un método bayesiano para asignar una estructura secundaria a datos de coordenadas de proteínas utilizando el criterio de información de Shannon de inferencia de longitud mínima de mensaje (MML). SST trata cualquier asignación de estructura secundaria como una hipótesis potencial que intenta explicar (comprimir) datos de coordenadas de proteínas dados. La idea central es que la mejor asignación estructural secundaria es la que puede explicar (comprimir) las coordenadas de una proteína dada de la manera más económica, vinculando así la inferencia de estructura secundaria a la compresión de datos sin pérdidas. SST delinea con precisión cualquier cadena de proteína en regiones asociadas con los siguientes tipos de asignación:
- E = (Extended) hilo de un Sábana β
- G = Mano derecha 310 helix
- H = Mano derecha α-helix
- I = Mano derecha π-helix
- g = Mano izquierda 310 helix
- h = Mano izquierda α-helix
- i = Mano izquierda π-helix
- 3 = 310- Como Turn
- 4 = α- Como Turn
- 5 = π-como Turn
- T = Turno no especificado
- C = Coil
- - = Residuos no asignados
SST detecta π y 310 extremos helicoidales en α-hélices estándar, y ensambla automáticamente los diversos hebras extendidas en láminas plegadas β consistentes. Proporciona una salida legible de elementos estructurales secundarios disecados y un script cargable PyMol correspondiente para visualizar los elementos estructurales secundarios asignados individualmente.
Determinación experimental
El contenido bruto de estructura secundaria de un biopolímero (p. ej., "esta proteína tiene un 40 % de hélice α y un 20 % de hoja β") se puede estimar espectroscópicamente. Para las proteínas, un método común es el dicroísmo circular ultravioleta lejano (UV lejano, 170–250 nm). Un mínimo doble pronunciado a 208 y 222 nm indica una estructura helicoidal α, mientras que un mínimo único a 204 nm o 217 nm refleja una estructura de bobina aleatoria o de hoja β, respectivamente. Un método menos común es la espectroscopia infrarroja, que detecta diferencias en las oscilaciones de los enlaces de los grupos amida debido a los enlaces de hidrógeno. Finalmente, los contenidos de estructuras secundarias se pueden estimar con precisión utilizando los desplazamientos químicos de un espectro de RMN inicialmente no asignado.
Predicción
Predecir la estructura terciaria de la proteína a partir solo de su secuencia de aminoácidos es un problema muy desafiante (consulte la predicción de la estructura de la proteína), pero usar las definiciones de estructura secundaria más simples es más manejable.
Los primeros métodos de predicción de estructuras secundarias se limitaban a predecir los tres estados predominantes: hélice, hoja o espiral aleatoria. Estos métodos se basaron en las propensiones de formación de hélices o láminas de aminoácidos individuales, a veces junto con reglas para estimar la energía libre de formar elementos de estructura secundaria. Las primeras técnicas ampliamente utilizadas para predecir la estructura secundaria de proteínas a partir de la secuencia de aminoácidos fueron el método Chou-Fasman y el método GOR. Aunque dichos métodos pretendían lograr una precisión del ~60 % en la predicción de cuál de los tres estados (hélice/lámina/bobina) adopta un residuo, las evaluaciones informáticas ciegas demostraron más tarde que la precisión real era mucho menor.
Se logró un aumento significativo en la precisión (hasta casi el 80 %) al explotar la alineación de secuencias múltiples; conocer la distribución completa de los aminoácidos que se encuentran en una posición (y en su vecindad, típicamente ~7 residuos en cada lado) a lo largo de la evolución proporciona una imagen mucho mejor de las tendencias estructurales cerca de esa posición. Por ejemplo, una proteína determinada podría tener una glicina en una posición determinada, lo que por sí solo podría sugerir una espiral aleatoria allí. Sin embargo, la alineación de secuencias múltiples podría revelar que los aminoácidos que favorecen la hélice se encuentran en esa posición (y en posiciones cercanas) en el 95 % de las proteínas homólogas que abarcan casi mil millones de años de evolución. Además, al examinar la hidrofobicidad promedio en esa posición y en las cercanas, la misma alineación también podría sugerir un patrón de accesibilidad del solvente residual consistente con una hélice α. Tomados en conjunto, estos factores sugerirían que la glicina de la proteína original adopta una estructura helicoidal α, en lugar de una espiral aleatoria. Se utilizan varios tipos de métodos para combinar todos los datos disponibles para formar una predicción de 3 estados, incluidas redes neuronales, modelos ocultos de Markov y máquinas de vectores de soporte. Los métodos de predicción modernos también proporcionan una puntuación de confianza para sus predicciones en cada posición.
Los métodos de predicción de estructura secundaria se evaluaron mediante los experimentos de evaluación crítica de la predicción de la estructura de proteínas (CASP) y se compararon continuamente, p. por EVA (referencia). Según estas pruebas, los métodos más precisos fueron Psipred, SAM, PORTER, PROF y SABLE. El área principal de mejora parece ser la predicción de cadenas β; los residuos predichos con confianza como cadena β probablemente lo sean, pero los métodos tienden a pasar por alto algunos segmentos de cadena β (falsos negativos). Es probable que haya un límite superior de ~90 % de precisión de predicción general, debido a las idiosincrasias del método estándar (DSSP) para asignar clases de estructuras secundarias (hélice/hebra/bobina) a estructuras PDB, con las que se comparan las predicciones.
La predicción precisa de la estructura secundaria es un elemento clave en la predicción de la estructura terciaria, excepto en los casos más simples (modelado de homología). Por ejemplo, un patrón predicho con confianza de seis elementos de estructura secundaria βαββαβ es la firma de un pliegue de ferredoxina.
Aplicaciones
Se pueden usar estructuras secundarias de proteínas y ácidos nucleicos para ayudar en la alineación de múltiples secuencias. Estas alineaciones se pueden hacer más precisas mediante la inclusión de información de estructura secundaria además de información de secuencia simple. Esto a veces es menos útil en el ARN porque el apareamiento de bases está mucho más conservado que la secuencia. Las relaciones distantes entre proteínas cuyas estructuras primarias no pueden alinearse a veces se pueden encontrar mediante la estructura secundaria.
Se ha demostrado que las hélices α son más estables, resistentes a las mutaciones y se pueden diseñar que las cadenas β en las proteínas naturales, por lo que es probable que el diseño de proteínas α funcionales sea más fácil que el diseño de proteínas con hélices y cadenas; esto ha sido recientemente confirmado experimentalmente.
Contenido relacionado
Pluot
Harry kroto
Hilaire Ruelle