Generalización de la distribución normal unidimensional a dimensiones superiores
En teoría de probabilidad y estadística, la distribución normal multivariante, distribución gaussiana multivariante o distribución normal conjunta es una generalización de la distribución normal dimensional (univariada) a dimensiones superiores. Una definición es que se dice que un vector aleatorio tiene una distribución normal variable k si cada combinación lineal de sus componentes k tiene una distribución normal univariante. Su importancia se deriva principalmente del teorema del límite central multivariante. La distribución normal multivariante se usa a menudo para describir, al menos aproximadamente, cualquier conjunto de variables aleatorias de valor real (posiblemente) correlacionadas, cada una de las cuales se agrupa alrededor de un valor medio.
Definiciones
Notación y parametrización
La distribución normal multivariada de un k-dimensional vector aleatorio  se puede escribir en la siguiente notación:
se puede escribir en la siguiente notación:

o para hacer saber explícitamente que X es k-dimensional,

con vector medio k-dimensional
![{displaystyle {boldsymbol {mu }}=operatorname {E} [mathbf {X} ]=(operatorname {E} [X_{1}],operatorname {E} [X_{2}],ldotsoperatorname {E} [X_{k}])^{textbf {T}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e69e434645f47377bc8766624255c8026adf7964)
y  matriz de covariancia
matriz de covariancia
![{displaystyle Sigma _{i,j}=operatorname {E} [(X_{i}-mu _{i})(X_{j}-mu _{j})]=operatorname {Cov} [X_{i},X_{j}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c970083f8469366521881996464f23d376b7c40b)
tales que  y
y  . El inverso de la matriz de covariancia se llama la matriz de precisión, denotada por
. El inverso de la matriz de covariancia se llama la matriz de precisión, denotada por  .
.
Vector aleatorio normal estándar
Un vector aleatorio real se llama vector normal aleatorio normal si todos sus componentes  son independientes y cada una es una unidad-varianza cero-medio normalmente distribuida variable aleatoria, es decir, si
son independientes y cada una es una unidad-varianza cero-medio normalmente distribuida variable aleatoria, es decir, si  para todos
para todos  .
.
Vector aleatorio normal centrado
Un vector aleatorio real se llama centrado normal vector aleatorio si existe un determinista  matriz
matriz  tales que
tales que  tiene la misma distribución
tiene la misma distribución  Donde
Donde  es un vector normal aleatorio normal con
es un vector normal aleatorio normal con  componentes.
componentes.
Vector aleatorio normal
Un vector aleatorio real se llama vector aleatorio normal si existe un azar -vector , que es un vector normal normal al azar, un  -vector
-vector  , y un matriz , tal que
, y un matriz , tal que  .
.
Formalmente:

Aquí está la matriz de covariancia  .
.
En el caso degenerado donde la matriz de covariancia es singular, la distribución correspondiente no tiene densidad; vea la sección abajo para detalles. Este caso surge con frecuencia en las estadísticas; por ejemplo, en la distribución del vector de residuos en la regresión de los mínimos cuadrados ordinarios. El en general no independiente; pueden verse como el resultado de la aplicación de la matriz a una colección de variables gaisianas independientes .
Definiciones equivalentes
Las siguientes definiciones son equivalentes a la definición dada anteriormente. Un vector aleatorio  tiene una distribución normal multivariada si satisface una de las siguientes condiciones equivalentes.
tiene una distribución normal multivariada si satisface una de las siguientes condiciones equivalentes.
- Cada combinación lineal
 de sus componentes se distribuye normalmente. Es decir, para cualquier vector constante
de sus componentes se distribuye normalmente. Es decir, para cualquier vector constante  , la variable aleatoria
, la variable aleatoria  tiene una distribución normal univariada, donde una distribución normal univariada con varianza cero es una masa de punto en su media.
tiene una distribución normal univariada, donde una distribución normal univariada con varianza cero es una masa de punto en su media. - Hay un k-vector y un semidefinido positivo simétrico matriz
 , tal que la función característica de es
, tal que la función característica de es 
La distribución normal esférica se puede caracterizar como la distribución única donde los componentes son independientes en cualquier sistema de coordenadas ortogonales.
Función de densidad
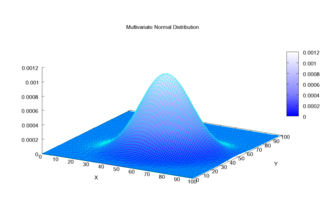
Densidad bivariable de articulación normal
Caso no degenerado
Se dice que la distribución normal multivariada es "no degenerada" cuando la matriz de covariancia simétrica es positivo. En este caso la distribución tiene densidad

Donde  es un verdadero k-dimensional vector de columna y
es un verdadero k-dimensional vector de columna y  es el determinante , también conocido como la varianza generalizada. La ecuación anterior reduce a la de la distribución normal univariada si es un
es el determinante , también conocido como la varianza generalizada. La ecuación anterior reduce a la de la distribución normal univariada si es un  matriz (es decir, un número real único).
matriz (es decir, un número real único).
La versión circularmente simétrica de la distribución normal compleja tiene una forma ligeramente diferente.
Cada lugar geométrico de iso-densidad, el lugar geométrico de los puntos en el espacio k-dimensional, cada uno de los cuales da el mismo valor particular de la densidad, es una elipse o su generalización de dimensión superior; por tanto, la normal multivariante es un caso especial de las distribuciones elípticas.
La cantidad  se conoce como la distancia Mahalanobis, que representa la distancia del punto de prueba de la media
se conoce como la distancia Mahalanobis, que representa la distancia del punto de prueba de la media  . Note que en el caso cuando
. Note que en el caso cuando  , la distribución reduce a una distribución normal univariada y la distancia Mahalanobis reduce al valor absoluto de la puntuación estándar. Vea también Intervalo abajo.
, la distribución reduce a una distribución normal univariada y la distancia Mahalanobis reduce al valor absoluto de la puntuación estándar. Vea también Intervalo abajo.
Caso bivariado
En el caso no singular 2-dimensional ), la función de densidad de probabilidad de un vector
), la función de densidad de probabilidad de un vector ![{displaystyle {text{[XY]′}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/24925a0dd360004248b2a1de70e2b0bcf3fcf687) es:
es:
![{displaystyle f(x,y)={frac {1}{2pi sigma _{X}sigma _{Y}{sqrt {1-rho ^{2}}}}}exp left(-{frac {1}{2(1-rho ^{2})}}left[left({frac {x-mu _{X}}{sigma _{X}}}right)^{2}-2rho left({frac {x-mu _{X}}{sigma _{X}}}right)left({frac {y-mu _{Y}}{sigma _{Y}}}right)+left({frac {y-mu _{Y}}{sigma _{Y}}}right)^{2}right]right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c616921276f29c0c0cd5383fd81045939f8f6e82)






En el caso bivariado, la primera condición equivalente para la reconstrucción multivariada de la normalidad puede ser menos restrictiva ya que es suficiente para verificar que contablemente muchas combinaciones lineales distintas de y son normales para concluir que el vector de es bivariable normal.
El loci iso-densidad bivariada trazado en el  -plano son elipses, cuyos ejes principales son definidos por los eigenvectores de la matriz de covariancia (los semidiámetros mayores y menores de la elipse igualan la raíz cuadrada de los eigenvalues ordenados).
-plano son elipses, cuyos ejes principales son definidos por los eigenvectores de la matriz de covariancia (los semidiámetros mayores y menores de la elipse igualan la raíz cuadrada de los eigenvalues ordenados).

Distribución normal bivariada centrada en

con una desviación estándar de 3 en aproximadamente el

dirección y de 1 en dirección ortogonal.
Como valor absoluto del parámetro de correlación aumenta, estos loci se exprimen hacia la siguiente línea:

Esto es porque esta expresión, con  (donde sgn es la función Sign) sustituido por , es la mejor predicción lineal imparcial de dado un valor .
(donde sgn es la función Sign) sustituido por , es la mejor predicción lineal imparcial de dado un valor .
Caso degenerado
Si la matriz de covariancia no es de rango completo, entonces la distribución normal multivariada es degenerada y no tiene una densidad. Más precisamente, no tiene una densidad con respecto a k-dimensional Medida de Lebesgue (que es la medida habitual asumida en los cursos de probabilidad de nivel de cálculo). Sólo vectores aleatorios cuyas distribuciones son absolutamente continuas con respecto a una medida se dice que tienen densidades (con respecto a esa medida). Para hablar de densidades pero evitar tratar con complicaciones teoréticas de medida puede ser más simple restringir la atención a un subconjunto de  de las coordenadas
de las coordenadas  tal que la matriz de covariancia para este subconjunto es positiva definida; entonces las otras coordenadas pueden ser consideradas como una función afinada de estas coordenadas seleccionadas.
tal que la matriz de covariancia para este subconjunto es positiva definida; entonces las otras coordenadas pueden ser consideradas como una función afinada de estas coordenadas seleccionadas.
Para hablar de densidades significativamente en casos singulares, debemos seleccionar una medida de base diferente. Usando el teorema de desintegración podemos definir una restricción de la medida de Lebesgue a la - subespacial affine dimensional  donde se apoya la distribución gaussiana, es decir,
donde se apoya la distribución gaussiana, es decir,  . Con respecto a esta medida la distribución tiene la densidad del motivo siguiente:
. Con respecto a esta medida la distribución tiene la densidad del motivo siguiente:

Donde  es el inverso generalizado, es el rango de y
es el inverso generalizado, es el rango de y  es el pseudo-determinante.
es el pseudo-determinante.
Función de distribución acumulativa
La noción de función de distribución acumulativa (cdf) en la dimensión 1 se puede extender de dos maneras al caso multidimensional, basado en regiones rectangulares y elipsoidales.
La primera manera es definir el cdf  de un vector aleatorio como la probabilidad de que todos los componentes son inferiores o iguales a los valores correspondientes en el vector :
de un vector aleatorio como la probabilidad de que todos los componentes son inferiores o iguales a los valores correspondientes en el vector :

Aunque no hay forma cerrada para , hay un número de algoritmos que lo estiman numéricamente.
Otra manera es definir el cdf  como la probabilidad de que una muestra se encuentra dentro del ellipsoide determinado por su distancia Mahalanobis
como la probabilidad de que una muestra se encuentra dentro del ellipsoide determinado por su distancia Mahalanobis  del Gaussian, una generalización directa de la desviación estándar.
Para calcular los valores de esta función, existen fórmulas analíticas cerradas, como sigue.
del Gaussian, una generalización directa de la desviación estándar.
Para calcular los valores de esta función, existen fórmulas analíticas cerradas, como sigue.
Intervalo
El intervalo para la distribución normal multivariante produce una región que consta de esos vectores x que satisfacen

Aquí. es un - vector dimensional, es el conocido - vector medio dimensional, es la matriz de covariancia conocida y  es la función cuantil para la probabilidad
es la función cuantil para la probabilidad  de la distribución de chi-squared con grados de libertad.
Cuando
de la distribución de chi-squared con grados de libertad.
Cuando  la expresión define el interior de una elipse y la distribución equiparada simplifica a una distribución exponencial equivalente a dos (valor igual a la mitad).
la expresión define el interior de una elipse y la distribución equiparada simplifica a una distribución exponencial equivalente a dos (valor igual a la mitad).
Función de distribución acumulativa complementaria (distribución de cola)
Función de distribución acumulativa complementaria (ccdf) o Distribución de la cola se define como  .
Cuando
.
Cuando  , entonces
el ccdf puede ser escrito como una probabilidad el máximo de variables Gaussianas dependientes:
, entonces
el ccdf puede ser escrito como una probabilidad el máximo de variables Gaussianas dependientes:

Si bien no existe una fórmula cerrada simple para calcular el ccdf, el máximo de variables gaussianas dependientes puede
estimarse con precisión mediante el método de Monte Carlo.
Propiedades
Probabilidad en diferentes dominios
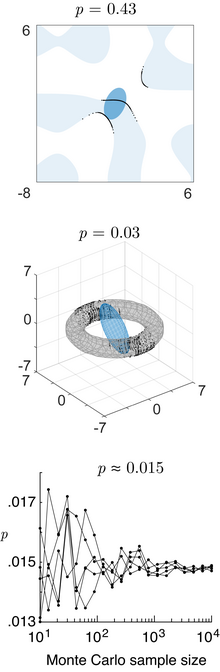
Top: la probabilidad de una normalidad bivariada en el dominio

(reglas azules). Medio: la probabilidad de una normalidad trivariada en un dominio toroidal. Tema: converger Monte-Carlo integral de la probabilidad de una normalidad 4-variada en el dominio poliedral normal 4d definido por

. Todos estos son computados por el método numérico de rastreo de rayos.
El contenido de probabilidad de la normalidad multivariable en un dominio cuadrático definido por  (donde)
(donde)  es una matriz,
es una matriz,  es un vector, y
es un vector, y  es un escalar), que es relevante para la clasificación Bayesian / teoría de la decisión usando el análisis discriminante gausiano, es dada por la distribución generalizada de chi-squared.
El contenido de probabilidad dentro de cualquier dominio general definido por
es un escalar), que es relevante para la clasificación Bayesian / teoría de la decisión usando el análisis discriminante gausiano, es dada por la distribución generalizada de chi-squared.
El contenido de probabilidad dentro de cualquier dominio general definido por  (donde)
(donde)  es una función general) se puede calcular utilizando el método numérico de rastreo de rayos (código principal).
es una función general) se puede calcular utilizando el método numérico de rastreo de rayos (código principal).
Momentos superiores
Los momentos de késimo orden de x están dados por
![{displaystyle mu _{1,ldotsN}(mathbf {x}) {stackrel {mathrm {def} }{=}} mu _{r_{1},ldotsr_{N}}(mathbf {x}) {stackrel {mathrm {def} }{=}}operatorname {E} left[prod _{j=1}^{N}X_{j}^{r_{j}}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/68bafb23658afe2f4246d5f27781aac7eeacbaa7)
donde r1 + r2 + ⋯ + rN = k.
Los momentos centrales de késimo orden son los siguientes
- Si k Es extraño. μ1,... N()x − μ) = 0.
- Si k incluso con k = 2λ, entonces

donde se toma la suma sobre todas las asignaciones del conjunto  en λ (sin orden) pares. Eso es, para un kT (= 2λ = 6) momento central, uno resume los productos de λ = 3 covarianzas (el valor esperado) μ se considera 0 en interés de la parsimonia:
en λ (sin orden) pares. Eso es, para un kT (= 2λ = 6) momento central, uno resume los productos de λ = 3 covarianzas (el valor esperado) μ se considera 0 en interés de la parsimonia:
![{displaystyle {begin{aligned}&operatorname {E} [X_{1}X_{2}X_{3}X_{4}X_{5}X_{6}]\[8pt]={}&operatorname {E} [X_{1}X_{2}]operatorname {E} [X_{3}X_{4}]operatorname {E} [X_{5}X_{6}]+operatorname {E} [X_{1}X_{2}]operatorname {E} [X_{3}X_{5}]operatorname {E} [X_{4}X_{6}]+operatorname {E} [X_{1}X_{2}]operatorname {E} [X_{3}X_{6}]operatorname {E} [X_{4}X_{5}]\[4pt]&{}+operatorname {E} [X_{1}X_{3}]operatorname {E} [X_{2}X_{4}]operatorname {E} [X_{5}X_{6}]+operatorname {E} [X_{1}X_{3}]operatorname {E} [X_{2}X_{5}]operatorname {E} [X_{4}X_{6}]+operatorname {E} [X_{1}X_{3}]operatorname {E} [X_{2}X_{6}]operatorname {E} [X_{4}X_{5}]\[4pt]&{}+operatorname {E} [X_{1}X_{4}]operatorname {E} [X_{2}X_{3}]operatorname {E} [X_{5}X_{6}]+operatorname {E} [X_{1}X_{4}]operatorname {E} [X_{2}X_{5}]operatorname {E} [X_{3}X_{6}]+operatorname {E} [X_{1}X_{4}]operatorname {E} [X_{2}X_{6}]operatorname {E} [X_{3}X_{5}]\[4pt]&{}+operatorname {E} [X_{1}X_{5}]operatorname {E} [X_{2}X_{3}]operatorname {E} [X_{4}X_{6}]+operatorname {E} [X_{1}X_{5}]operatorname {E} [X_{2}X_{4}]operatorname {E} [X_{3}X_{6}]+operatorname {E} [X_{1}X_{5}]operatorname {E} [X_{2}X_{6}]operatorname {E} [X_{3}X_{4}]\[4pt]&{}+operatorname {E} [X_{1}X_{6}]operatorname {E} [X_{2}X_{3}]operatorname {E} [X_{4}X_{5}]+operatorname {E} [X_{1}X_{6}]operatorname {E} [X_{2}X_{4}]operatorname {E} [X_{3}X_{5}]+operatorname {E} [X_{1}X_{6}]operatorname {E} [X_{2}X_{5}]operatorname {E} [X_{3}X_{4}].end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0517839a9528128fa6d69cedfe4f5003a34716f4)
Este rendimiento  términos en la suma (15 en el caso anterior), siendo cada uno el producto de λ (en este caso 3) covarianzas. Para los momentos de cuarto orden (cuatro variables) hay tres términos. Para los momentos de sexto orden hay 3 × 5 = 15 términos, y para los momentos de octavo orden hay 3 × 5 × 7 = 105 términos.
términos en la suma (15 en el caso anterior), siendo cada uno el producto de λ (en este caso 3) covarianzas. Para los momentos de cuarto orden (cuatro variables) hay tres términos. Para los momentos de sexto orden hay 3 × 5 = 15 términos, y para los momentos de octavo orden hay 3 × 5 × 7 = 105 términos.
Las covarianzas se determinan luego reemplazando los términos de la lista ![{displaystyle [1,ldots2lambda ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a605bf32a38577fe9df1bc5715a4a3cac5869832) por los términos correspondientes de la lista r1 entonces r2 dos, etc. Para ilustrar esto, examine el siguiente caso de cuarto orden del momento central:
por los términos correspondientes de la lista r1 entonces r2 dos, etc. Para ilustrar esto, examine el siguiente caso de cuarto orden del momento central:
![{displaystyle {begin{aligned}operatorname {E} left[X_{i}^{4}right]&=3sigma _{ii}^{2}\[4pt]operatorname {E} left[X_{i}^{3}X_{j}right]&=3sigma _{ii}sigma _{ij}\[4pt]operatorname {E} left[X_{i}^{2}X_{j}^{2}right]&=sigma _{ii}sigma _{jj}+2sigma _{ij}^{2}\[4pt]operatorname {E} left[X_{i}^{2}X_{j}X_{k}right]&=sigma _{ii}sigma _{jk}+2sigma _{ij}sigma _{ik}\[4pt]operatorname {E} left[X_{i}X_{j}X_{k}X_{n}right]&=sigma _{ij}sigma _{kn}+sigma _{ik}sigma _{jn}+sigma _{in}sigma _{jk}.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4e08f5bc180e3f1f4379c1026100e833ea85de97)
Donde  es la covariancia de Xi y Xj. Con el método anterior se encuentra primero el caso general para un kmomento con k diferentes X variables,
es la covariancia de Xi y Xj. Con el método anterior se encuentra primero el caso general para un kmomento con k diferentes X variables, ![{displaystyle Eleft[X_{i}X_{j}X_{k}X_{n}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0b4bbbf2becaf15b246898e928a37e7d0ab6f93a) , y luego uno simplifica esto en consecuencia. Por ejemplo,
, y luego uno simplifica esto en consecuencia. Por ejemplo, ![{displaystyle operatorname {E} [X_{i}^{2}X_{k}X_{n}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f7bc1920d0e524aa567ca471bdb54dcf7ef7e673) , uno deja Xi = Xj y uno utiliza el hecho de que
, uno deja Xi = Xj y uno utiliza el hecho de que  .
.
Funciones de un vector normal

a: Densidad de probabilidad de una función

de una sola variable normal

con

y

.
b: Densidad de probabilidad de una función

de un vector normal

, con mala

, y covariancia

.
c: Mapa de calor de la densidad de probabilidad conjunta de dos funciones de un vector normal
, con mala

, y covariancia

.
d: Densidad de probabilidad de una función

de 4 variables normales normales. Estos son computados por el método numérico de rastreo de rayos.
Una forma cuadrática de un vector normal  ,
,  (donde) es una matriz, es un vector, y es un cuero cabelludo), es una variable cisterna generalizada.
(donde) es una matriz, es un vector, y es un cuero cabelludo), es una variable cisterna generalizada.
Si es una función general de valor de escalar de un vector normal, su función de densidad de probabilidad, la función de distribución acumulativa y la función de distribución acumulativa inversa se pueden computar con el método numérico de rastreo de rayos (código principal).
Función de probabilidad
Si se conoce la matriz media y covariancia, la probabilidad de registro de un vector observado es simplemente el registro de la función de densidad de probabilidad:
![{displaystyle ln L({boldsymbol {x}})=-{frac {1}{2}}left[ln(|{boldsymbol {Sigma }}|,)+({boldsymbol {x}}-{boldsymbol {mu }})'{boldsymbol {Sigma }}^{-1}({boldsymbol {x}}-{boldsymbol {mu }})+kln(2pi)right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4ad05643016bbf6ac76a826320bea00704b50982) ,
,
La versión circular simétrica del caso complejo no central, donde  es un vector de números complejos, sería
es un vector de números complejos, sería

i.e. con la transposición conyugal (indicada por  ) sustitución de la transposición normal (indicado por
) sustitución de la transposición normal (indicado por  ). Esto es ligeramente diferente que en el caso real, porque la versión circular simétrica de la distribución normal compleja tiene una forma ligeramente diferente para la constante de normalización.
). Esto es ligeramente diferente que en el caso real, porque la versión circular simétrica de la distribución normal compleja tiene una forma ligeramente diferente para la constante de normalización.
Se utiliza una notación similar para la regresión lineal múltiple.
Dado que el logaritmo de verosimilitud de un vector normal es una forma cuadrática del vector normal, se distribuye como una variable de chi-cuadrado generalizada.
Entropía diferencial
La entropía diferencial de la distribución normal multivariada es

donde las barras indican el determinante de la matriz y k es la dimensionalidad del espacio vectorial.
Divergencia Kullback-Leibler
La divergencia Kullback-Leibler desde  a
a  , para matrices no singulares1 y la0, es:
, para matrices no singulares1 y la0, es:

Donde es la dimensión del espacio vectorial.
El logaritmo debe tomarse en base e ya que los dos términos que siguen al logaritmo son en sí mismos logaritmos en base e de expresiones que son factores de la función de densidad o no surgen naturalmente. Por lo tanto, la ecuación da un resultado medido en nats. Dividir toda la expresión anterior por loge 2 produce la divergencia en bits.
Cuando  ,
,

Información mutua
La información mutua de una distribución es un caso especial de la divergencia Kullback-Leibler en el que  es la distribución multivariada completa y
es la distribución multivariada completa y  es el producto de las distribuciones marginales de 1 dimensión. En la notación de la sección de divergencias Kullback-Leibler de este artículo,
es el producto de las distribuciones marginales de 1 dimensión. En la notación de la sección de divergencias Kullback-Leibler de este artículo,  es una matriz diagonal con las entradas diagonales de
es una matriz diagonal con las entradas diagonales de  , y . La fórmula resultante para la información mutua es:
, y . La fórmula resultante para la información mutua es:

Donde  es la matriz de correlación construida a partir de .
es la matriz de correlación construida a partir de .
En el caso bivariado la expresión para la información mutua es:

Normalidad articular
Normalmente distribuidos e independientes
Si y son normalmente distribuidos e independientes, esto implica que son "juntamente distribuidos", es decir, el par  debe tener una distribución normal multivariada. Sin embargo, un par de variables distribuidas conjuntamente normalmente no necesitan ser independientes (sólo sería así si no estuvieran relacionadas,
debe tener una distribución normal multivariada. Sin embargo, un par de variables distribuidas conjuntamente normalmente no necesitan ser independientes (sólo sería así si no estuvieran relacionadas,  ).
).
Dos variables aleatorias normalmente distribuidas no necesitan ser juntas normales bivariadas
El hecho de que dos variables al azar y ambos tienen una distribución normal no implica que el par tiene una distribución normal conjunta. Un ejemplo simple es uno en el que X tiene una distribución normal con el valor esperado 0 y la varianza 1, y  si
si  y
y  si
si  , donde
, donde  . Hay contraexamples similares para más de dos variables aleatorias. En general, se suma a un modelo de mezcla.
. Hay contraexamples similares para más de dos variables aleatorias. En general, se suma a un modelo de mezcla.
Correlaciones e independencia
En general, las variables aleatorias pueden no estar correlacionadas pero ser estadísticamente dependientes. Pero si un vector aleatorio tiene una distribución normal multivariada, entonces dos o más de sus componentes que no están correlacionados son independientes. Esto implica que dos o más de sus componentes que son independientes por pares son independientes. Pero, como se señaló anteriormente, no es cierto que dos variables aleatorias que están (por separado, marginalmente) normalmente distribuidas y no correlacionadas son independientes.
Distribuciones condicionales
Si N-dimensional x se divide de la siguiente manera

y, en consecuencia, μ y Σ se dividen de la siguiente manera


entonces la distribución de x1 condicionada a x2 = a es normal multivariado (x1 | x2 = a ) ~ N(μ, Σ) donde

y matriz de covarianza

Aquí.  es el inverso generalizado de
es el inverso generalizado de  . La matriz
. La matriz  es el complemento de Schur .22 dentro .. Es decir, la ecuación anterior es equivalente a invertir la matriz de covariancia general, bajando las filas y columnas correspondientes a las variables que están condicionadas, e invirtiendo de nuevo para conseguir la matriz de covariancia condicional.
es el complemento de Schur .22 dentro .. Es decir, la ecuación anterior es equivalente a invertir la matriz de covariancia general, bajando las filas y columnas correspondientes a las variables que están condicionadas, e invirtiendo de nuevo para conseguir la matriz de covariancia condicional.
Note que sabiendo que x2 = a altera la varianza, aunque la nueva varianza no depende del valor específico de a; quizás más sorprendentemente, la media es cambiada por  ; comparar esto con la situación de no conocer el valor a, en cuyo caso x1 tendría distribución
; comparar esto con la situación de no conocer el valor a, en cuyo caso x1 tendría distribución
 .
.
Un hecho interesante derivado para probar este resultado, es que los vectores aleatorios  y
y  son independientes.
son independientes.
La matriz Σ12Σ22−1 se conoce como la matriz de coeficientes de regresión.
Caso bivariado
En el caso bivariado x se divide en  y
y  , la distribución condicional de dado es
, la distribución condicional de dado es

Donde es el coeficiente de correlación entre y .
Expectativa condicional bivariada
En el caso general

La expectativa condicional de X1 dada X2 es:

Prueba: el resultado se obtiene tomando la expectativa de la distribución condicional  arriba.
arriba.
En el caso centrado con varianzas unitarias
Más resultados...




