
Devanagari
| Parte de una serie sobre | |
|---|---|
| |
| Sistemas de escritura de uso oficial en la India | |
| Categoría | |
| Indic scripts | |
Bengali-Assamese script
· Devanagari script
| |
| scripts derivados árabes | |
script perso-arabic · Urdu script | |
| Guiones alfabéticos | |
Ol Chiki· Latin script | |
| Relacionados | |
Escritura oficial
| |
|

Devanagari (DÍA-və-NAH-gə-ree; देवनागरी, IAST: Devanāgarī, Pronunciación sánscrita: [deːʋɐˈnaːɡɐriː]), también llamado Nagari (Sánscrito: नागरी, Nāgarī), es un abugida de izquierda a derecha (un tipo de sistema de escritura segmentado), basado en la antigua escritura Brāhmī, utilizada en el subcontinente indio del norte. Fue desarrollado y en uso regular en el siglo VII EC. La escritura devanagari, compuesta por 47 caracteres primarios, incluidas 14 vocales y 33 consonantes, es el cuarto sistema de escritura más adoptado del mundo y se utiliza en más de 120 idiomas.
La ortografía de esta escritura refleja la pronunciación del idioma. A diferencia del alfabeto latino, la escritura no tiene el concepto de mayúsculas y minúsculas. Se escribe de izquierda a derecha, tiene una fuerte preferencia por las formas redondeadas simétricas dentro de los contornos cuadrados y se reconoce por una línea horizontal, conocida como shirorekhā, que se extiende a lo largo de la parte superior de las letras completas. En una mirada superficial, la escritura devanagari parece diferente de otras escrituras índicas como bengalí-asamés o gurmukhi, pero un examen más detallado revela que son muy similares excepto por los ángulos y el énfasis estructural.
Entre los idiomas que lo utilizan, ya sea como su única escritura o como una de sus escrituras, se encuentran el marathi, el pāḷi, el sánscrito (la antigua escritura nagari para el sánscrito tenía dos caracteres consonánticos adicionales), el hindi, el boro, el nepalí, el sherpa y el prakrit., Apabhramsha, Awadhi, Bhojpuri, Braj Bhasha, Chhattisgarhi, Haryanvi, Magahi, Nagpuri, Rajasthani, Bhili, Dogri, Kashmiri, Konkani, Sindhi, Nepal Bhasa, Mundari y Santali. La escritura devanagari está estrechamente relacionada con la escritura nandinagari que se encuentra comúnmente en numerosos manuscritos antiguos del sur de la India, y está lejanamente relacionada con varias escrituras del sudeste asiático.
Etimología
Devanagari es un compuesto de "deva" (देव) y "nāgarī" (नागरी). Deva significa "celestial o divino" y es también uno de los términos para una deidad en el hinduismo. Nagari proviene de नगरम् (nagaram) una palabra sánscrita que significa pueblo. Por lo tanto, Devanagari denota desde la morada de la divinidad o deidades.
Nāgarī es el femenino sánscrito de Nāgara "relacionado o perteneciente a un pueblo o ciudad, urbano". Es una frase con lipi ("script") como nāgarī lipi "escritura relacionada con una ciudad", o "hablado en la ciudad".
Escritura devanagari conocida como 'Escritura de la ciudad divina' procedía de Devanagara o la "ciudad del dios". Y de ahí que lo interpreten como "[guión de] la ciudad de los dioses".
El uso del nombre devanāgarī surgió de la antigua término nāgarī. Según Fischer, el nagari surgió en el subcontinente indio noroccidental alrededor del año 633 d. C., se desarrolló por completo en el siglo XI y fue una de las principales escrituras utilizadas para la literatura sánscrita.
Historia
Devanagari es parte de la familia de escrituras brahmánicas de la India, Nepal, el Tíbet y el sudeste asiático. Es un descendiente de la escritura Brahmi del siglo III a. C., que evolucionó hasta convertirse en la escritura Nagari, que a su vez dio origen a Devanagari y Nandinagari. Devanagari ha sido ampliamente adoptado en India y Nepal para escribir sánscrito, marathi, hindi, idiomas indoarios centrales, konkani, boro y varios idiomas nepalíes.
Algunas de las pruebas epigráficas más antiguas que atestiguan el desarrollo de la escritura sánscrita nagari en la India antigua datan de las inscripciones del siglo I al IV d. C. descubiertas en Gujarat. Las variantes de escritura llamadas Nāgarī, reconociblemente cercanas a Devanagari, se atestiguan por primera vez a partir de las inscripciones de Rudradaman del siglo I d.C. en sánscrito, mientras que la forma estandarizada moderna de Devanagari estaba en uso alrededor del año 1000 d.C. Las inscripciones medievales sugieren una difusión generalizada de las escrituras relacionadas con Nagari, con biscripts que presentan escritura local junto con la adopción de escrituras Nagari. Por ejemplo, el pilar Pattadakal de mediados del siglo VIII en Karnataka tiene texto tanto en escritura Siddha Matrika como en una escritura Telugu-Kannada temprana; mientras que la inscripción de Kangra Jawalamukhi en Himachal Pradesh está escrita en escritura Sharada y Devanagari.
La escritura nagari se usaba regularmente en el siglo VII d.C. y se desarrolló por completo a fines del primer milenio. El uso del sánscrito en la escritura nagari en la India medieval está atestiguado por numerosas inscripciones de templos de cuevas y pilares, incluidas las inscripciones de Udayagiri del siglo XI en Madhya Pradesh, y un ladrillo con inscripciones encontrado en Uttar Pradesh, fechado en 1217 EC, que ahora es celebrada en el Museo Británico. Las versiones preliminares y relacionadas del guión se han descubierto en reliquias antiguas fuera de la India, como en Sri Lanka, Myanmar e Indonesia; mientras que en el este de Asia, los budistas usaban la escritura Siddha Matrika considerada como el precursor más cercano a Nagari. Nagari ha sido el primus inter pares de las escrituras índicas. Durante mucho tiempo ha sido utilizado tradicionalmente por personas con educación religiosa en el sur de Asia para registrar y transmitir información, existiendo en todo el país en paralelo con una amplia variedad de escrituras locales (como Modi, Kaithi y Mahajani) que se utilizan para la administración, el comercio y otros. usos diarios.
Sharada permaneció en uso paralelo en Cachemira. Una versión temprana de Devanagari es visible en la inscripción Kutila de Bareilly fechada en Vikram Samvat 1049 (es decir, 992 EC), que demuestra el surgimiento de la barra horizontal para agrupar letras que pertenecen a una palabra. Uno de los textos sánscritos más antiguos que se conservan de principios del período posterior a Maurya consta de 1413 páginas de Nagari de un comentario de Patanjali, con una fecha de composición de alrededor de 150 a. C., la copia superviviente se transcribió alrededor del siglo XIV d.
| k- | kh- | g- | gh- | ṅ- | c- | ch- | j- | Jh... | ñ- | Å- | Åh- | . | ¿Qué? | . | t- | T- | d- | * | No... | p- | ph- | b- | bh- | m- | Y... | r- | Yo... | v. | ś- | . | s... | h- | |
| Brahmi | 𑀓 | 𑀔 | 𑀕 | 𑀖 | 𑀗 | 𑀘 | 𑀙 | 𑀚 | 𑀛 | 𑀜 | 𑀝 | 𑀞 | 𑀟 | 𑀠 | 𑀡 | 𑀢 | 𑀣 | 𑀤 | 𑀥 | 𑀦 | 𑀧 | 𑀨 | 𑀩 | 𑀪 | 𑀫 | 𑀬 | 𑀭 | 𑀮 | 𑀯 | 𑀰 | 𑀱 | 𑀲 | 𑀳 |
| Gupta | |||||||||||||||||||||||||||||||||
| Devanagari | क | ख | ▪ | घ | ङ | च | छ | . | झ | ञ | ट | ‹ | ड | ढ | ण | latitud | थ | . | ध | Valoraciones | प | फ | ब | भ | म | य | र | . | व | श | ष | ▪ | . |
Este de Asia

En el siglo VII, bajo el gobierno de Songtsen Gampo del Imperio tibetano, Thonmi Sambhota fue enviado a Nepal para iniciar negociaciones de matrimonio con una princesa nepalí y encontrar un sistema de escritura adecuado para el idioma tibetano. Así inventó la escritura tibetana, basada en la Nagari utilizada en Cachemira. Agregó 6 nuevos caracteres para sonidos que no existían en sánscrito.
Otras escrituras estrechamente relacionadas con el nagari, como Siddham Matrka, se usaban en Indonesia, Vietnam, Japón y otras partes del este de Asia entre los siglos VII y X.
La mayoría de las escrituras del sudeste asiático tienen sus raíces en las escrituras dravidianas, a excepción de algunas que se encuentran en las regiones centro-sur de Java y partes aisladas del sudeste asiático que se asemejan a Devanagari o su prototipo. La escritura kawi en particular es similar a la devanagari en muchos aspectos, aunque la morfología de la escritura tiene cambios locales. Las primeras inscripciones en las escrituras similares a Devanagari son de alrededor del siglo X, con muchas más entre los siglos XI y XIV. Algunas de las antiguas inscripciones de Devanagari se encuentran en templos hindúes de Java, como el templo de Prambanan. Las inscripciones de Ligor y Kalasan de Java central, que datan del siglo VIII, también están en escritura nagari del norte de la India. Según el epigrafista y erudito en estudios asiáticos Lawrence Briggs, estos pueden estar relacionados con la inscripción en placa de cobre del siglo IX de Devapaladeva (Bengala), que también está en escritura devanagari temprana. El término Kawi en escritura Kawi es una palabra prestada de Kavya (poesía). Según los antropólogos y estudiosos de estudios asiáticos John Norman Miksic y Goh Geok Yian, la versión del siglo VIII de la primera escritura nagari o devanagari se adoptó en Java, Bali (Indonesia) y Khmer (Camboya) alrededor de los siglos VIII o IX, como lo demuestra las numerosas inscripciones de este período.
Cartas
El orden de las letras de Devanagari, como casi todas las escrituras brahmánicas, se basa en principios fonéticos que consideran tanto la forma como el lugar de articulación de las consonantes y vocales que representan. Este arreglo generalmente se conoce como varṇamālā " guirnalda de letras". El formato de Devanagari para sánscrito sirve como prototipo para su aplicación, con variaciones o adiciones menores, a otros idiomas.
Vocales
Las vocales y su disposición son:
| Forma independiente | IAST | ISO | IPA | Como diacrítica con प (Barakhadi) | Forma independiente | IAST | ISO | IPA | Como diacrítica con प (Barakhadi) | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| kanu (Gutural) | . | a | [Primero] | प | आ | ā | [Correcto] | प | ||||
| tālavya (Palatal) | इ | i | [i] | प | ई | . | [ibal] | प | ||||
| os надина (Labial) | उ | u | [u] | पु6 | ऊ | ū | [u pasillo] | पू6 | ||||
| mūrdhanya (Retroflex) | ऋ | . | r̥ | [r] | पृ | ॠ4 | ṝ | r r | [r] | पॄ | ||
| dantya (Dental) | ऌ4 | . | l̥ | [l] | पॢ | ॡ4, 5 | ḹ | l. | [l] | पॣ | ||
| kanāhatālavya (Palatogutural) | . | e | ē | [ebal] | पे | ऐ | ai | [Marca] | पै | |||
| kanusa (Labioguttural) | ओ | o | ō | [o Ambiental] | पो | औ | au | [Marca] | पौ | |||
| Ø/▪1,2 | ṃ | MIN | [◌] | प | Ø/ः1 | ¥ | [h] | पः | ||||
| ॲ / ऍ7 | ê | [æ] | पॅ | ऑ7 | ô | [ ] | पॉ | |||||


.jpg)

- Arreglado con las vocales son dos diacríticos consonantales, la nasal final anusvāra ▪ ṃ y el último fricativo visarga ः ¥ (llamado Ø a) y Ø aḥ). Masica (1991:146) anusvāra en sánscrito que "hay alguna controversia sobre si representa una parada nasal homorgánica [...], una vocal nasal, una semivola nasalizada, o todo esto según contexto". El visarga representa fricación sin voz post-vocal [h], en sánscrito un alofono de s, o menos comúnmente r, usualmente en posición de palabra final. Algunas tradiciones de recitación anexan un eco de la vocal después de la respiración: इः [ihi]. Masica (1991:146) considera visarga junto con cartas ङ ṅa y ञ ña para que las nasales "grandemente predecibles" y palatales sean ejemplos de "sobremata telefónica en el sistema".
- Otro diacrítico es el candrabindu/anunāsika ँ Ø. Salomon (2003:76–77) lo describe como una "forma más empática" de la anusvāra, "a veces [...] solía marcar una verdadera nasalización [vowel]". En un nuevo idioma Indo-Aria como Hindi la distinción es formal: el candrabindu indica la nasalización vocal mientras que anusvār indica una nasal homorgánica que precede a otro consonante: Рँ adelanto [en inglés] "Risas", делиный [ ] "El Ganges". Cuando una akristora tiene una vocal diacrítica sobre la línea superior, que no deja espacio para la candra ("moon") derrame candrabindu, que se dispensa a favor del punto solitario: . [sujeto] "am", pero Отели [Suena] "are". Algunos escritores y compositores se dispensan con el "moon" golpe por completo, utilizando sólo el punto en todas las situaciones.
- El avagraha ऽ Ø (generalmente transliterado con un apostrofe) es una marca de punción sánscrita para la elisión de una vocal en sandhi: ए eko'yam (← периный ekas + Ø ayam"Este". Una vocal original larga perdida a la coalecencia es a veces marcada con un doble avagraha: Преныеныханых sadātmā (← Грованых sadā + आ aguja ātmāSiempre, el yo. En Hindi, Snell (2000:77) afirma que su "principal función es mostrar que una vocal se sostiene en un grito o un grito": आईऽऽऽ! ¡Ahí está!. En Madhyadeshi Idiomas como Bhojpuri, Awadhi, Maithili, etc. que tienen "muchas formas verbales [que] terminan en esa vocal inherente", la avagraha se utiliza para marcar el noelisión de palabra-final inherente a, que de otro modo es una convención ortográfico moderna: बइ baiijkha "sit" versus बइ baiijkh
- Los consonantes silábicos ṝ ()ॠ), ., ()ऌ) y ḹ ()ॡ) son específicos de sánscrito y no incluido en el varnu de otros idiomas. El sonido representado por . también se ha perdido en los idiomas modernos, y su pronunciación ahora va desde [] (Hindi) to [] (Marathi).
- ḹ no es un teléfono real de sánscrito, sino más bien una convención gráfica incluida entre las vocales para mantener la simetría de pares cortos de largo de letras.
- Hay formaciones no regulares de रु rupias, रू rū, y . h.
- Hay dos vocales más en Marathi, ॲ y ऑ, que representan respectivamente [æ], similar a la pronunciación de RP en inglésact, y [.], similar a la pronunciación RP de нелины en 'cot’. Estas vocales se utilizan a veces en Hindi también, como en डॉ dôlar"Dolar". No se define la transliteración IAST. En ISO 15919, la transliteración es ê y ô, respectivamente.
Consonantes
La siguiente tabla muestra las letras consonantes (en combinación con la vocal inherente a) y su disposición. A la derecha de la letra de Devanagari, muestra la transliteración del alfabeto latino utilizando el Alfabeto internacional de transliteración sánscrita y el valor fonético (IPA) en hindi.
| Teléfonos → | sparśa (Oclusivo) | anunāsika (Nasal) | antastha (Aproximante) | ūshman/sasaghar (Fricativo) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Voicing → | agho | sagho | agho | sagho | ||||||||||||
| Aspiración → | alpaprāa | mahāprāa | alpaprāa | mahāprāa | alpaprāa | mahāprāa | ||||||||||
| kanu (Velars) | क | ka [k] | ख | kha [kh] | ▪ | ga [ ] | घ | gha [ ] | ङ | ṅa [ ] | . | # [suspira] | ||||
| tālavya (Palatal) | च | ca [tár] | छ | # [Truh] | . | ja [d.] | झ | jha [d tuya] | ञ | ña [ɲ] | य | Ya sabes. [j] | श | śa [ya] | ||
| mūrdhanya (Retroflex) | ट | ►a [ʈ] | ‹ | Åha [ʈh] | ड | GERA [ɖ] | ढ | TORH [ɖ] | ण | . [ɳ] | र | ra [r] | ष | . [ʂ] | ||
| dantya (Dental) | latitud | ta [t̪] | थ | tha [t̪h] | . | da [d̪] | ध | ♪ [d̪] | Valoraciones | na [n] | . | la [l] | ▪ | sa [s] | ||
| os надина (Labial) | प | pa [p] | फ | pha [ph] | ब | ba [b] | भ | bha [b] | म | ma [m] | व | va [ʋ] | ||||
- Además, hay ळ . (IPA: [ɭ] o [̆]), el alefono lateral intervocal de la parada retroflex de voz en el sánscrito Védico, que es un teléfono en idiomas como Marathi, Konkani, Garhwali y Rajasthani.
- Más allá del conjunto sánscrito, rara vez se han formulado nuevas formas. Masica (1991:146) ofrece lo siguiente: "En cualquier caso, según algunos, todos los sonidos posibles ya habían sido descritos y proporcionados en este sistema, ya que sánscrito era el lenguaje original y perfecto. Por lo tanto, era difícil prever o incluso concebir otros sonidos, desconocidos para los fonéticos de Sánscrito". Cuando los prestatarios extranjeros y los desarrollos internos inevitablemente se acumularon y se levantaron en Nuevas lenguas de Indo-Aria, han sido ignorados por escrito, o tratados a través de medios como diacríticos y ligaduras (ignorados en recitación).
- El diacrítico más prolífico ha sido el punto de subscripto (nuqtā) ़. Hindi lo utiliza para los sonidos persa, árabe e inglés क़ qa /q/, ख़ xa /x/, ▪ ⋅a / . za /z/, झ़ zha / ♪♪ फ़ fa /f/, y para los desarrollos alofónicos ड़ . /ɽ/ y ढ़ . (Aunque) ऴ ḻa /ɻ/ podría existir, no se utiliza en Hindi.)
- Los implosivos de Sindhi y Saraiki se acomodan con una línea adjunta a continuación: ॻ [ə], ॼ [ə], ॾ [ə], ॿ [ə].
- Los sonorantes inspirados pueden ser representados como conjuntos/ligatures con . #: म mha, especificaciones nha, ण ., व vha, . lha, ळ ., र rha.
- Masica (1991:147) señala que Marwari utiliza ॸ para GERA [ə] (mientras) ड representaciones [ə]).
Para obtener una lista de las 297 (33 × 9) posibles sílabas de vocales consonánticas (cortas) en sánscrito, consulte Numeración Āryabhaṭa.
Diacríticas vocales
(feminine)
Tabla: Consonantes con signos diacríticos de vocal. Vocales en su forma independiente en la parte superior y en su forma dependiente correspondiente (signo de vocal) combinadas con la consonante 'k' En el fondo. 'ka' no tiene ningún signo de vocal agregado, donde la vocal 'a&# 39; es inherente.
| a | ā | æ | . | i | . | u | ū | e | ē | ai | o | ō | au | r̥ | r r | l̥ | l. | MIN | ¥ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| . | आ | ॲ | ऑ | इ | ई | उ | ऊ | ऎ | . | ऐ | ऒ | ओ | औ | ऋ | ॠ | ऌ | ॡ | Ø | Ø | |
| ka | kā | # | k | # | kī | ku | kū | ke | kē | kai | ko | kō | kau | kr̥ | kr. | kl̥ | kl. | KaM | kaḥ | k |
| क | क | कॅ | कॉ | क | क | कु | कू | कॆ | के | कै | कॊ | को | कौ | कृ | कॄ | कॢ | कॣ | क | कः | क |
Una vocal se combina con una consonante en su forma diacrítica. Por ejemplo, la vocal आ (ā) se combina con la consonante क् (k) para formar la letra silábica का (kā), con halant (signo de cancelación) eliminado y agregado de un signo de vocal que se indica mediante signos diacríticos. La vocal अ (a) se combina con la consonante क् (k) para formar क (ka) con halant eliminado. Pero la serie diacrítica de क, ख, ग, घ... (ka, kha, ga, gha) no tiene ningún signo de vocal añadido, ya que la vocal अ (a) es inherente. La transliteración de cada combinación aparecerá al pasar el mouse.
| a | ā | i | . | u | ū | e | ai | o | au | a | aḥ | |
| . | आ | इ | ई | उ | ऊ | . | ऐ | ओ | औ | Ø | Ø | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k- | क | क | क | क | कु | कू | के | कै | को | कौ | क | कः |
| kh- | ख | ख | ख | ख | खु | खू | खे | खै | खो | खौ | ख | खः |
| g- | ▪ | перите | ▪ | ▪ | ▪ | ▪ | ▪ | ▪ | ▪ | ▪ | ■ | ▪ |
| gh- | घ | घ | घ | घ | घु | घू | घे | घै | घो | घौ | घ | घः |
| ṅ- | ङ | ङ | ङ | ङ | ङु | ङू | ङे | ङै | ङो | ङौ | ङ | ङः |
| c- | च | च | च | च | चु | चू | चे | चै | चो | चौ | च | चः |
| ch- | छ | छ | छ | छ | छु | छू | छे | छै | छो | छौ | छ | छः |
| j- | . | . | . | . | . | . | . | . | . | . | . | . |
| Jh... | झ | झ | झ | झ | झु | झू | झे | झै | झो | झौ | झ | झः |
| ñ- | ञ | ञ | ञ | ञ | ञु | ञू | ञे | ञै | ञो | ञौ | ञ | ञः |
| Å- | ट | ट | ट | ट | टु | टू | टे | टै | टो | टौ | ट | टः |
| Åh- | ‹ | эленной | ‹ | Alternativa | ठ | ठ | ठ | ठ | ठ | ठ | эленной | ठ |
| . | ड | ड | ड | ड | डु | डू | डे | डै | डो | डौ | ड | डः |
| ¿Qué? | ढ | ढ | ढ | ढ | ढु | ढू | ढे | ढै | ढो | ढौ | ढ | ढः |
| . | ण | ण | ण | ण | णु | णू | णे | णै | णो | णौ | ण | णः |
| t- | latitud | त | Ø | Alternativa | त | त | त | त | त | त | Гленых | त |
| T- | थ | थ | थ | थ | थु | थू | थे | थै | थो | थौ | थ | थः |
| d- | . | . | . | . | . | . | . | . | . | . | Alternativa | . |
| * | ध | ध | ध | ध | धु | धू | धे | धै | धो | धौ | ध | धः |
| No... | Valoraciones | Dimensiones | Valoraciones | Alternativa | Valoraciones | Valoraciones | Valoraciones | Valoraciones | Valoraciones | Valoraciones | Alternativa | Valoraciones |
| p- | प | प | प | प | पु | पू | पे | पै | पो | पौ | प | पः |
| ph- | फ | फ | फ | फ | फु | फू | फे | फै | फो | फौ | फ | फः |
| b- | ब | ब | ब | ब | बु | बू | बे | बै | बो | बौ | ब | बः |
| bh- | भ | भ | भ | भ | भु | भू | भे | भै | भो | भौ | भ | भः |
| m- | म | म | म | म | मु | मू | मे | मै | मो | मौ | म | मः |
| Y... | य | य | य | य | यु | यू | ये | यै | यो | यौ | य | यः |
| r- | र | र | र | र | रु | रू | रे | रै | रो | रौ | र | रः |
| Yo... | . | . | . | . | . | . | . | . | . | . | . | . |
| v. | व | व | व | व | वु | वू | वे | वै | वो | वौ | व | वः |
| ś- | श | श | श | श | शु | शू | शे | शै | शो | शौ | श | शः |
| . | ष | ष | ष | ष | षु | षू | षे | षै | षो | षौ | ष | षः |
| s... | ▪ | Провани | ▪ | ▪ | RASस | RASस | RASस | RASस | RASस | RASस | Глиных | RASस |
| h- | . | ा | . | . | . | . | . | . | . | . | Отели | . |
Consonantes conjuntas

Como se mencionó, las consonantes sucesivas que carecen de una vocal entre ellas pueden unirse físicamente como una consonante conjunta o ligadura. Cuando Devanagari se usa para escribir idiomas distintos al sánscrito, los conjuntos se usan principalmente con palabras sánscritas y palabras prestadas. Las palabras nativas generalmente usan la consonante básica y los hablantes nativos saben suprimir la vocal cuando es convencional hacerlo. Por ejemplo, la palabra hindi nativa karnā se escribe करना (ka-ra-nā). El gobierno de estos grupos varía desde reglas de aplicación amplia a limitada, con excepciones especiales dentro. Si bien está estandarizado en su mayor parte, existen ciertas variaciones en la agrupación, de las cuales el Unicode utilizado en esta página es solo un esquema. Las siguientes son una serie de reglas:
- 24 de los 36 consonantes contienen un derrame vertical derecho (ख kha, घ gha, ण . etc.). Como primeros o medianos fragmentos/miembros de un grupo (cuando las letras deben ser escritas como media pronunciada), pierden ese golpe. Por ejemplo. Dimensiones + व = Dimensiones tva, ण + ढ = ण ., Ганика + थ = Раних Stha. En Unicode, como en Hindi, estos consonantes sin sus tallos verticales se llaman medias formas. श ś(a) aparece como un fragmento diferente en forma de cinta que precede व va, Valoraciones na, च ca, . la, y र ra, haciendo que estos segundos miembros se desplacen y se reduzcan en tamaño. Así श śva, श array śna, श śca श śla, श śra, y शृ śri.
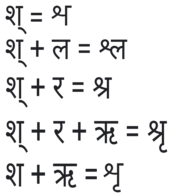 Todas las formas de श
Todas las formas de श - र r a) como primer miembro toma la forma de un dash ascendente curvado sobre el carácter final o su ā-diacrítica. Por ejemplo. र rva, र rvā, र rspa, र rspā. Como miembro final con ट ►a, ‹ Åha, ड GERA, ढ TORH, ड़ ., छ #, es dos líneas juntas debajo del carácter apuntado hacia abajo. Así ट Åra, ‹ Åhra, ड ◆, ढ KINGhra, ड़ ., छ chra. En otro lugar como miembro final es un golpe diagonal que extiende hacia la izquierda y hacia abajo. Por ejemplo. क. latitud ta se cambia para hacer el conjunto Dimensiones tra.
- Como primeros miembros, los caracteres restantes carentes de trazos verticales como . d a) y . h a) puede tener su segundo miembro, reducido en tamaño y falta de su trazo horizontal, colocado debajo. क k(a), छ ch(a), y फ a) acortar sus ganchos derecho y unirse directamente al siguiente miembro.
- Los conjuntos para k y jñ no se derivan claramente de las letras que componen sus componentes. El conjunto para k es क ()क + ष) y para jñ Lo es . (). + ञ).

Acentos
El acento tonal del sánscrito védico se escribe con varios símbolos según el shakha. En el Rigveda, anudātta se escribe con una barra debajo de la línea (◌॒), svarita con un trazo sobre la línea (◌॑) mientras que udātta no está marcado.
Puntuación
El final de una oración o medio verso se puede marcar con "।" símbolo (llamado daṇḍa, que significa "bar", o llamado pūrṇa virām, que significa "punto final/pausa"). El final de un verso completo se puede marcar con un daṇḍa doble, un "॥" símbolo. Una coma (llamada alpa virām, que significa " breve parada/pausa") se utiliza para denotar una pausa natural en el habla. Los signos de puntuación de origen occidental, como los dos puntos, el punto y coma, el signo de exclamación, el guión y el signo de interrogación, se han utilizado en la escritura devanagari desde al menos la década de 1900, coincidiendo con su uso en los idiomas europeos.
Formularios antiguos


Las siguientes variantes de letras también están en uso, particularmente en textos más antiguos.
| estándar | antigua |
|---|---|
Números
| ० | १ | २ | ३ | ४ | ५ | ६ | ७ | ८ | ९ |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Fuentes
Se utiliza una variedad de fuentes Unicode para Devanagari. Estos incluyen Akshar, Annapurna, Arial, CDAC-Gist Surekh, CDAC-Gist Yogesh, Chandas, Gargi, Gurumaa, Jaipur, Jana, Kalimati, Kanjirowa, Lohit Devanagari, Mangal, Kokila, Raghu, Sanskrit2003, Santipur OT, Siddhanta y Thyaka..
La forma de las fuentes Devanagari varía según la función. Según la Universidad de Harvard para estudios de sánscrito:
Uttara [companión a Chandas] es el mejor en términos de ligaduras pero, porque está diseñado para Védico también, requiere tanto espacio vertical que no es adecuado para la fuente de interfaz de usuario (aunque una excelente opción para la fuente "campo original"). Santipur OT es una hermosa fuente que refleja un estilo de tipografía muy temprano [ era medieval] para Devanagari. Sanskrit 2003 es una buena fuente completa y tiene más ligaduras que la mayoría de las fuentes, aunque los estudiantes probablemente encontrarán el espaciamiento de la fuente CDAC-Gist Surekh hace para una comprensión y lectura más rápidas.
El proyecto Google Fonts tiene una serie de fuentes Unicode para Devanagari en una variedad de tipos de letra en categorías serif, sans-serif, pantalla y escritura a mano.
Transliteración

Existen varios métodos de romanización o transliteración del devanagari al alfabeto latino.
Sistema Hunter
El sistema hunteriano es el "sistema nacional de romanización en la India" y el adoptado oficialmente por el Gobierno de la India.
ISO 15919
Se codificó una convención de transliteración estándar en el estándar ISO 15919 de 2001. Utiliza signos diacríticos para mapear el conjunto mucho más grande de grafemas brahmánicos a la escritura latina. La porción específica de Devanagari es casi idéntica al estándar académico para sánscrito, IAST.
IAST
El Alfabeto Internacional de Transliteración Sánscrita (IAST) es el estándar académico para la romanización del sánscrito. IAST es el estándar de facto utilizado en publicaciones impresas, como libros, revistas y textos electrónicos con fuentes Unicode. Se basa en un estándar establecido por el Congreso de Orientalistas en Atenas en 1912. El estándar ISO 15919 de 2001 codificó la convención de transliteración para incluir un estándar ampliado para las escrituras hermanas de Devanagari.
La romanización de la Biblioteca Nacional de Kolkata, destinada a la romanización de todas las escrituras índicas, es una extensión de IAST.
Harvard-Kyoto
En comparación con IAST, Harvard-Kyoto parece mucho más simple. No contiene todos los signos diacríticos que contiene IAST. Fue diseñado para simplificar la tarea de poner una gran cantidad de material textual en sánscrito en un formato legible por máquina, y los inventores afirmaron que reduce el esfuerzo necesario en la transliteración de textos en sánscrito en el teclado. Esto hace que escribir en Harvard-Kyoto sea mucho más fácil que en IAST. Harvard-Kyoto usa letras mayúsculas que pueden ser difíciles de leer en medio de las palabras.
ITRANS
ITRANS es un esquema de transliteración sin pérdidas de Devanagari a ASCII que se usa ampliamente en Usenet. Es una extensión del esquema Harvard-Kyoto. En ITRANS, la palabra devanāgarī se escribe "devanaagarii" o "devanAgarI". ITRANS está asociado con una aplicación del mismo nombre que permite la composición tipográfica en alfabetos índicos. El usuario ingresa letras romanas y el preprocesador ITRANS traduce las letras romanas al devanagari (u otros idiomas índicos). La última versión de ITRANS es la versión 5.30 lanzada en julio de 2001. Es similar al sistema Velthuis y fue creado por Avinash Chopde para ayudar a imprimir varias escrituras índicas con computadoras personales.
Velthuis
La desventaja de los esquemas ASCII anteriores es la distinción entre mayúsculas y minúsculas, lo que implica que los nombres transliterados pueden no escribirse con mayúscula. Esta dificultad se evita con el sistema desarrollado en 1996 por Frans Velthuis para TeX, basado libremente en IAST, en cuyo caso es irrelevante.
Romanización ALA-LC
La romanización ALA-LC es un esquema de transliteración aprobado por la Biblioteca del Congreso y la American Library Association, y ampliamente utilizado en las bibliotecas de América del Norte. Las tablas de transliteración se basan en idiomas, por lo que hay una tabla para hindi, otra para sánscrito y prakrit, etc.
WX
WX es un esquema de transliteración romana para idiomas indios, muy utilizado entre la comunidad de procesamiento de lenguaje natural en India. Se originó en IIT Kanpur para el procesamiento computacional de idiomas indios. Las características más destacadas de este esquema de transliteración son las siguientes.
- Cada consonante y cada vocal tiene un solo mapeo en Romano. Por lo tanto es un código prefijo, ventajoso desde el punto de vista de la computación.
- Se utilizan letras minúsculas para consonantes no inspirados y vocales cortas, mientras que las letras mayúsculas se utilizan para consonantes aspirados y vocales largas. Mientras que las paradas retroflex se mapean a 't, T, d, D, N', los dentales se mapean a 'w, W, x, X, n'. De ahí el nombre 'WX', un recordatorio de esta cartografía idiosincrática.
Codificaciones
ISCII
ISCII es una codificación de 8 bits. Los 128 puntos de código inferiores son ASCII simples, los 128 puntos de código superiores son específicos de ISCII.
Se ha diseñado para representar no solo el devanagari, sino también otras escrituras índicas, así como una escritura basada en el latín con marcas diacríticas utilizadas para la transliteración de las escrituras índicas.
ISCII ha sido reemplazado en gran medida por Unicode, que, sin embargo, ha intentado conservar el diseño ISCII para sus bloques de idioma índico.
Unicódigo
El estándar Unicode define cuatro bloques para Devanagari: Devanagari (U+0900–U+097F), Devanagari Extended (U+A8E0–U+A8FF), Devanagari Extended-A (U+11B00–11B5F) y Vedic Extensions (U+1CD0–U+1CFF).
| Devanagari Gráfico oficial de códigos Unicode Consortium (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+090x | ऀ | ँ | ▪ | ः | ऄ | . | आ | इ | ई | उ | ऊ | ऋ | ऌ | ऍ | ऎ | . |
| U+091x | ऐ | ऑ | ऒ | ओ | औ | क | ख | ▪ | घ | ङ | च | छ | . | झ | ञ | ट |
| U+092x | ‹ | ड | ढ | ण | latitud | थ | . | ध | Valoraciones | ऩ | प | फ | ब | भ | म | य |
| U+093x | र | ऱ | . | ळ | ऴ | व | श | ष | ▪ | . | ऺ | ऻ | ़ | ऽ | . | . |
| U+094x | . | ु | ू | ृ | ॄ | ॅ | ॆ | े | ै | ॉ | ॊ | ो | ौ | . | ॎ | ॏ |
| U+095x | ॐ | ॑ | ॒ | ॓ | ॔ | ॕ | ॖ | ॗ | क़ | ख़ | ▪ | . | ड़ | ढ़ | फ़ | य़ |
| U+096x | ॠ | ॡ | ॢ | ॣ | । | ॥ | ० | १ | २ | ३ | ४ | ५ | ६ | ७ | ८ | ९ |
| U+097x | ॰ | ॱ | ॲ | ॳ | ॴ | ॵ | ॶ | ॷ | ॸ | ॹ | ॺ | ॻ | ॼ | ॽ | ॾ | ॿ |
Notas
| ||||||||||||||||
| Devanagari Extendido Gráfico oficial de códigos Unicode Consortium (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+A8Ex | ꣠ | ꣡ | ꣢ | ꣣ | ꣤ | ꣥ | ꣦ | ꣧ | ꣨ | ꣩ | ꣪ | ꣫ | ꣬ | ꣭ | ꣮ | ꣯ |
| U+A8Fx | ꣰ | ꣱ | ꣲ | ꣳ | ꣴ | ꣵ | ꣶ | ꣷ | ꣸ | ꣹ | ꣺ | ꣻ | ꣼ | ꣽ | ꣾ | ꣿ |
Notas
| ||||||||||||||||
| Devanagari Extended-A Gráfico oficial de códigos Unicode Consortium (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+11B0x | 𑬀 | 𑬁 | 𑬂 | 𑬃 | 𑬄 | 𑬅 | 𑬆 | 𑬇 | 𑬈 | 𑬉 | ||||||
| U+11B1x | ||||||||||||||||
| U+11B2x | ||||||||||||||||
| U+11B3x | ||||||||||||||||
| U+11B4x | ||||||||||||||||
| U+11B5x | ||||||||||||||||
Notas
| ||||||||||||||||
| Extensiones védicas Gráfico oficial de códigos Unicode Consortium (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+1CDx | ᳐ | ᳑ | ᳒ | ᳓ | ᳔ | ᳕ | ᳖ | ᳗ | ᳘ | ᳙ | ᳚ | ᳛ | ᳜ | ᳝ | ᳞ | ᳟ |
| U+1CEx | . | ᳡ | ᳢ | . | ᳤ | ᳥ | ᳦ | ᳧ | ᳨ | . | ᳪ | ᳫ | ᳬ | ᳭ | ᳮ | ᳯ |
| U+1CFx | ᳰ | ᳱ | ᳲ | ᳳ | ᳴ | ᳵ | ᳶ | ᳷ | ᳸ | ᳹ | ᳺ | |||||
Notas
| ||||||||||||||||
Diseños de teclado Devanagari
Diseño InScript
InScript es el diseño de teclado estándar para Devanagari según lo estandarizado por el Gobierno de la India. Está integrado en todos los principales sistemas operativos modernos. Microsoft Windows admite el diseño InScript (usando la fuente Mangal), que se puede usar para ingresar caracteres unicode Devanagari. InScript también está disponible en algunos teléfonos móviles con pantalla táctil.

Máquina de escribir
Este diseño se usaba en máquinas de escribir manuales cuando las computadoras no estaban disponibles o eran poco comunes. Para compatibilidad con versiones anteriores, algunas herramientas de escritura como Indic IME aún brindan este diseño.
Fonética
(feminine)
Estas herramientas funcionan en la transliteración fonética. El usuario escribe en el alfabeto latino y el IME lo convierte automáticamente en Devanagari. Algunas herramientas populares de escritura fonética son Akruti, Baraha IME y Google IME.
El sistema operativo Mac OS X incluye dos diseños de teclado diferentes para Devanagari: uno se asemeja a INSCRIPT/KDE Linux, mientras que el otro es un diseño fonético llamado "Devanagari QWERTY".
Cualquiera de los sistemas de entrada de fuentes Unicode está bien para Wikipedia en idioma índico y otros wikiproyectos, incluidos Wikipedia en hindi, bhojpuri, marathi y nepalí. Si bien algunas personas usan InScript, la mayoría usa la transliteración fonética de Google o la función de entrada Universal Language Selector que se proporciona en Wikipedia. En los wikiproyectos en idioma índico, la función fonética provista inicialmente estaba basada en Java y luego fue compatible con la extensión Narayam para la función de entrada fonética. Actualmente, los proyectos Wiki en idioma índico son compatibles con Universal Language Selector (ULS), que ofrece teclado fonético (akshantaran, marathi: अक्षरांतरण, hindi: लिप्यंतरण, बोलनागरी) y teclado InScript (maratí: मराठी लिपी).
El sistema operativo Ubuntu Linux admite varios diseños de teclado para Devanagari, incluidos Harvard-Kyoto, notación WX, Bolanagari y fonética. El 'remington' El método de tipeo en Ubuntu IBUS es similar al método de tipeo de Krutidev, popular en Rajasthan. El 'itrans' El método es útil para quienes conocen bien el inglés (y el teclado en inglés) pero no están familiarizados con la escritura en devanagari.
Contenido relacionado
Lenguas polisintéticas
Gramática transformacional
Idioma albanés