
Cálculo bayesiano aproximado
El cálculo bayesiano aproximado (ABC por Approximate Bayesian computation) constituye una clase de métodos computacionales arraigados en las estadísticas bayesianas que se pueden utilizar para estimar las distribuciones posteriores de los parámetros del modelo.
En toda inferencia estadística basada en modelos, la función de verosimilitud tiene una importancia central, ya que expresa la probabilidad de los datos observados bajo un modelo estadístico particular y, por lo tanto, cuantifica los datos de apoyo que se prestan a valores particulares de parámetros y a elecciones entre diferentes modelos. Para modelos simples, normalmente se puede derivar una fórmula analítica para la función de probabilidad. Sin embargo, para modelos más complejos, una fórmula analítica puede ser difícil de alcanzar o la función de probabilidad puede ser computacionalmente muy costosa de evaluar.
Los métodos ABC pasan por alto la evaluación de la función de probabilidad. De esta forma, los métodos ABC amplían el ámbito de los modelos para los que se puede considerar la inferencia estadística. Los métodos ABC están bien fundamentados matemáticamente, pero inevitablemente hacen suposiciones y aproximaciones cuyo impacto debe evaluarse cuidadosamente. Además, el dominio de aplicación más amplio de ABC exacerba los desafíos de la estimación de parámetros y la selección de modelos.
ABC ha ganado rápidamente popularidad en los últimos años y en particular para el análisis de problemas complejos que surgen en las ciencias biológicas, por ejemplo, en genética de poblaciones, ecología, epidemiología, biología de sistemas y en la propagación de radio.
Historia
Las primeras ideas relacionadas con ABC se remontan a la década de 1980. Donald Rubin, al discutir la interpretación de las declaraciones bayesianas en 1984, describió un mecanismo de muestreo hipotético que produce una muestra de la distribución posterior. Este esquema fue más un experimento de pensamiento conceptual para demostrar qué tipo de manipulaciones se realizan al inferir las distribuciones posteriores de parámetros. La descripción del mecanismo de muestreo coincide exactamente con la del esquema de rechazo ABC, y este artículo puede considerarse el primero en describir el cálculo bayesiano aproximado. Sin embargo, Francis Galton construyó un quincunx de dos etapas a fines del siglo XIX que puede verse como una implementación física de un esquema de rechazo ABC para una sola incógnita (parámetro) y una sola observación.Rubin hizo otro punto profético cuando argumentó que en la inferencia bayesiana, los estadísticos aplicados no deberían conformarse solo con modelos tratables analíticamente, sino considerar métodos computacionales que les permitan estimar la distribución posterior de interés. De esta manera, se puede considerar una gama más amplia de modelos. Estos argumentos son particularmente relevantes en el contexto de ABC.
En 1984, Peter Diggle y Richard Gratton sugirieron usar un esquema de simulación sistemática para aproximar la función de probabilidad en situaciones donde su forma analítica es intratable. Su método se basó en definir una cuadrícula en el espacio de parámetros y usarla para aproximar la probabilidad ejecutando varias simulaciones para cada punto de la cuadrícula. Luego se mejoró la aproximación aplicando técnicas de suavizado a los resultados de las simulaciones. Si bien la idea de usar la simulación para la prueba de hipótesis no era nueva, Diggle y Gratton aparentemente introdujeron el primer procedimiento usando la simulación para hacer inferencias estadísticas bajo una circunstancia en la que la probabilidad es intratable.
Aunque el enfoque de Diggle y Gratton había abierto una nueva frontera, su método aún no era exactamente idéntico a lo que ahora se conoce como ABC, ya que apuntaba a aproximar la probabilidad en lugar de la distribución posterior. Un artículo de Simon Tavaré et al.fue el primero en proponer un algoritmo ABC para la inferencia posterior. En su trabajo seminal, se consideró la inferencia sobre la genealogía de los datos de secuencias de ADN y, en particular, el problema de decidir la distribución posterior del tiempo hasta el ancestro común más reciente de los individuos muestreados. Tal inferencia es analíticamente intratable para muchos modelos demográficos, pero los autores presentaron formas de simular árboles coalescentes bajo los modelos putativos. Se obtuvo una muestra del posterior de los parámetros del modelo aceptando/rechazando propuestas basadas en la comparación del número de sitios segregantes en los datos sintéticos y reales. Este trabajo fue seguido por un estudio aplicado sobre el modelado de la variación en el cromosoma Y humano por Jonathan K. Pritchard et al.utilizando el método ABC. Finalmente, el término cálculo bayesiano aproximado fue establecido por Mark Beaumont et al. , ampliando aún más la metodología ABC y discutiendo la idoneidad del enfoque ABC más específicamente para problemas de genética de poblaciones. Desde entonces, ABC se ha extendido a aplicaciones fuera de la genética de poblaciones, como biología de sistemas, epidemiología y filogeografía.
Método
Motivación
Una encarnación común del teorema de Bayes relaciona la probabilidad condicional (o densidad) de un valor de parámetro particular 


donde 



El anterior representa creencias o conocimientos (como las limitaciones físicas fe) sobre
El algoritmo de rechazo ABC
Todos los métodos basados en ABC aproximan la función de verosimilitud mediante simulaciones, cuyos resultados se comparan con los datos observados. Más específicamente, con el algoritmo de rechazo ABC, la forma más básica de ABC, primero se muestrea un conjunto de puntos de parámetros de la distribución anterior. Dado un punto de parámetro muestreado 




donde la medida de distancia 

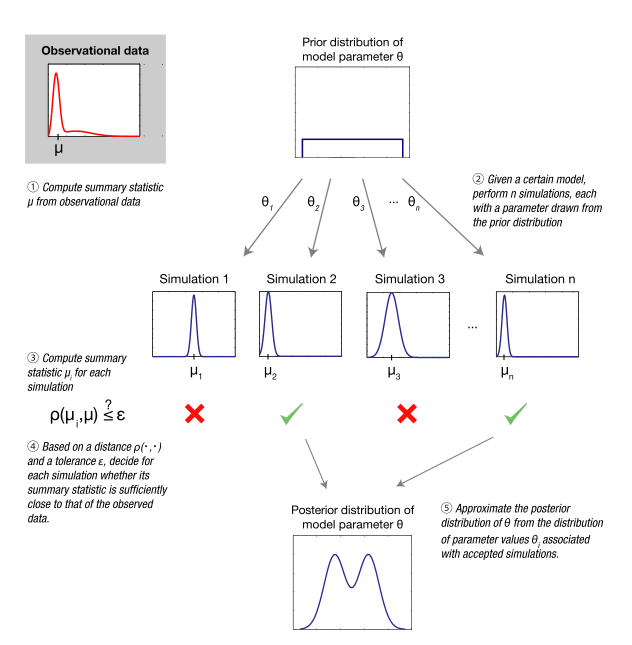 Estimación de parámetros por cálculo bayesiano aproximado: una descripción general conceptual.
Estimación de parámetros por cálculo bayesiano aproximado: una descripción general conceptual.
Resumen estadístico
La probabilidad de generar un conjunto de datos 

Si las estadísticas de resumen son suficientes con respecto a los parámetros del modelo
Como se explica a continuación, normalmente es imposible, fuera de la familia exponencial de distribuciones, identificar un conjunto de estadísticas suficientes de dimensión finita. Sin embargo, las estadísticas de resumen informativas pero posiblemente insuficientes se utilizan a menudo en aplicaciones donde la inferencia se realiza con métodos ABC.
Ejemplo
Un ejemplo ilustrativo es un sistema biestable que se puede caracterizar por un modelo oculto de Markov (HMM) sujeto a ruido de medición. Dichos modelos se emplean para muchos sistemas biológicos: se han utilizado, por ejemplo, en desarrollo, señalización celular, activación/desactivación, procesamiento lógico y termodinámica de no equilibrio. Por ejemplo, el comportamiento del factor de transcripción Sonic hedgehog (Shh) en Drosophila melanogaster se puede modelar con un HMM. El modelo dinámico (biológico) consta de dos estados: A y B. Si la probabilidad de una transición de un estado al otro se define como 


Debido a las dependencias condicionales entre estados en diferentes momentos, el cálculo de la probabilidad de datos de series temporales es algo tedioso, lo que ilustra la motivación para usar ABC. Un problema computacional para el ABC básico es la gran dimensionalidad de los datos en una aplicación como esta. La dimensionalidad se puede reducir utilizando la estadística de resumen 


Paso 1: Suponga que los datos observados forman la secuencia de estado AAAABAABBAAAAAABAAAA, que se genera usando 


Paso 2: Suponiendo que no se sabe nada acerca de, se emplea ![[0,1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)



| i |  | Conjuntos de datos simulados (paso 2) | Resumen estadístico (paso 3) (paso 3) | Distancia (paso 4)  | Resultado(paso 4) |
|---|---|---|---|---|---|
| 1 | 0.08 | AABAAAABAABAAABAAAAA | 8 | 2 | aceptado |
| 2 | 0,68 | AABBABABAAABBABABBAB | 13 | 7 | rechazado |
| 3 | 0.87 | BBBBBBABBBBABABBBBBA | 9 | 3 | rechazado |
| 4 | 0.43 | AABAAAAABBABBBBBBBBA | 6 | 0 | aceptado |
| 5 | 0.53 | ABBBBBAABBABBABAABBB | 9 | 3 | rechazado |
Paso 3: La estadística de resumen se calcula para cada secuencia de datos simulados 
Paso 4: La distancia entre las frecuencias de transición observadas y simuladas 

Paso 5: La distribución posterior se aproxima con los puntos de parámetros aceptados. La distribución posterior debe tener una probabilidad no despreciable para los valores de los parámetros en una región alrededor del valor real de
Las probabilidades posteriores se obtienen a través de ABC con grande 
Esta aplicación de ejemplo de ABC utiliza simplificaciones con fines ilustrativos. Las aplicaciones más realistas de ABC están disponibles en un número creciente de artículos revisados por pares.
Comparación de modelos con ABC
Fuera de la estimación de parámetros, el marco ABC se puede utilizar para calcular las probabilidades posteriores de diferentes modelos candidatos. En tales aplicaciones, una posibilidad es utilizar el muestreo por rechazo de forma jerárquica. Primero, se muestrea un modelo de la distribución anterior para los modelos. Luego, los parámetros se muestrean de la distribución anterior asignada a ese modelo. Finalmente, se realiza una simulación como en un solo modelo ABC. Las frecuencias relativas de aceptación de los diferentes modelos ahora se aproximan a la distribución posterior de estos modelos. De nuevo, se han propuesto mejoras computacionales para ABC en el espacio de modelos, como la construcción de un filtro de partículas en el espacio conjunto de modelos y parámetros.
Una vez que se han estimado las probabilidades posteriores de los modelos, se pueden hacer pleno uso de las técnicas de comparación de modelos bayesianos. Por ejemplo, para comparar las verosimilitudes relativas de dos modelos 



Si las anteriores del modelo son iguales, es decir, 
En la práctica, como se analiza a continuación, estas medidas pueden ser muy sensibles a la elección de las distribuciones previas de los parámetros y las estadísticas de resumen, por lo que las conclusiones de la comparación de modelos deben extraerse con cautela.
Trampas y remedios
| fuente de error | Problema potencial | Solución | Subsección |
|---|---|---|---|
| Tolerancia distinta de cero | La inexactitud introduce un sesgo en la distribución posterior calculada. | Estudios teórico-prácticos de la sensibilidad de la distribución posterior a la tolerancia. ABC ruidoso. | #Aproximación del posterior |
| Estadísticas resumidas insuficientes | La pérdida de información provoca intervalos creíbles inflados. | Selección automática/identificación semiautomática de estadísticas suficientes. Comprobaciones de validación del modelo (p. ej., Templeton 2009). | #Elección y suficiencia de estadísticas resumidas |
| Pequeño número de modelos/modelos especificados incorrectamente | Los modelos investigados no son representativos/carecen de poder predictivo. | Cuidada selección de modelos. Evaluación del poder predictivo. | #Pequeño número de modelos |
| Prioridades y rangos de parámetros | Las conclusiones pueden ser sensibles a la elección de los antecedentes. La elección del modelo puede no tener sentido. | Comprobar la sensibilidad de los factores de Bayes a la elección de priores. Se encuentran disponibles algunos resultados teóricos con respecto a la elección de antecedentes. Utilice métodos alternativos para la validación del modelo. | #Distribución previa y rangos de parámetros |
| Maldición de dimensionalidad | Bajas tasas de aceptación de parámetros. Los errores del modelo no se pueden distinguir de una exploración insuficiente del espacio de parámetros. Riesgo de sobreajuste. | Métodos para la reducción del modelo si corresponde. Métodos para acelerar la exploración de parámetros. Controles de calidad para detectar sobreajustes. | #Maldición de dimensionalidad |
| Clasificación de modelos con estadísticas de resumen | El cálculo de los factores de Bayes en las estadísticas resumidas puede no estar relacionado con los factores de Bayes en los datos originales, lo que, por lo tanto, puede hacer que los resultados no tengan sentido. | Solo use estadísticas de resumen que cumplan con las condiciones necesarias y suficientes para producir una elección de modelo bayesiano consistente. Utilice métodos alternativos para la validación del modelo. | #Factor de Bayes con ABC y estadísticas resumidas |
| Implementación | Baja protección a supuestos comunes en la simulación y el proceso de inferencia. | Comprobaciones de cordura de los resultados. Estandarización de software. | #Controles de calidad indispensables |
Al igual que con todos los métodos estadísticos, se requiere inherentemente una serie de suposiciones y aproximaciones para la aplicación de métodos basados en ABC a problemas reales de modelado. Por ejemplo, establecer el parámetro
Al mismo tiempo, algunas de las críticas que se han dirigido a los métodos ABC, en particular dentro del campo de la filogeografía, no son específicas de ABC y se aplican a todos los métodos bayesianos o incluso a todos los métodos estadísticos (por ejemplo, la elección de la distribución previa y rangos de parámetros). Sin embargo, debido a la capacidad de los métodos ABC para manejar modelos mucho más complejos, algunos de estos escollos generales son de particular relevancia en el contexto de los análisis ABC.
En esta sección se analizan estos riesgos potenciales y se revisan las posibles formas de abordarlos.
Aproximación de la parte posterior
Un no despreciable 
Como un intento de corregir parte del error debido a un valor distinto de cero
Finalmente, la inferencia estadística que usa ABC con una tolerancia distinta de cero
Elección y suficiencia de las estadísticas resumidas
Las estadísticas de resumen se pueden usar para aumentar la tasa de aceptación de ABC para datos de alta dimensión. Las estadísticas suficientes de baja dimensión son óptimas para este propósito, ya que capturan toda la información relevante presente en los datos de la forma más simple posible. Sin embargo, las estadísticas suficientes de baja dimensión son típicamente inalcanzables para los modelos estadísticos en los que la inferencia basada en ABC es más relevante y, en consecuencia, suele ser necesaria alguna heurística para identificar útiles estadísticas de resumen de baja dimensión. El uso de un conjunto de estadísticas de resumen mal elegidas a menudo conducirá a intervalos creíbles inflados debido a la pérdida implícita de información, lo que también puede sesgar la discriminación entre modelos. Se encuentra disponible una revisión de los métodos para elegir estadísticas resumidas,que pueden proporcionar una valiosa orientación en la práctica.
Un enfoque para capturar la mayor parte de la información presente en los datos sería usar muchas estadísticas, pero la precisión y la estabilidad de ABC parecen disminuir rápidamente con un número creciente de estadísticas resumidas. En cambio, una mejor estrategia es centrarse solo en las estadísticas relevantes: la relevancia depende de todo el problema de inferencia, del modelo utilizado y de los datos disponibles.
Se ha propuesto un algoritmo para identificar un subconjunto representativo de estadísticas de resumen, evaluando iterativamente si una estadística adicional introduce una modificación significativa de la posterior. Uno de los desafíos aquí es que un gran error de aproximación ABC puede influir en gran medida en las conclusiones sobre la utilidad de una estadística en cualquier etapa del procedimiento. Otro método se descompone en dos pasos principales. Primero, se construye una aproximación de referencia del posterior minimizando la entropía. Los conjuntos de resúmenes de candidatos se evalúan luego comparando los posteriores aproximados por ABC con el posterior de referencia.
Con ambas estrategias, se selecciona un subconjunto de estadísticas de un gran conjunto de estadísticas candidatas. En cambio, el enfoque de regresión de mínimos cuadrados parciales utiliza información de todas las estadísticas candidatas, cada una de las cuales se pondera adecuadamente. Recientemente, un método para construir resúmenes de manera semiautomática ha alcanzado un interés considerable. Este método se basa en la observación de que la elección óptima de estadísticos de resumen, al minimizar la pérdida cuadrática de las estimaciones puntuales de los parámetros, se puede obtener a través de la media posterior de los parámetros, que se aproxima realizando una regresión lineal a partir de los datos simulados..
Los métodos para la identificación de estadísticas resumidas que también podrían evaluar simultáneamente la influencia en la aproximación del posterior serían de gran valor. Esto se debe a que la elección de las estadísticas de resumen y la elección de la tolerancia constituyen dos fuentes de error en la distribución posterior resultante. Estos errores pueden corromper la clasificación de los modelos y también pueden dar lugar a predicciones de modelo incorrectas. De hecho, ninguno de los métodos anteriores evalúa la elección de resúmenes con el fin de seleccionar el modelo.
Factor de Bayes con ABC y estadísticas de resumen
Se ha demostrado que la combinación de estadísticas de resumen insuficientes y ABC para la selección del modelo puede ser problemática. De hecho, si se permite que el factor de Bayes basado en el resumen estadístico 

Por lo tanto, una estadística de resumen 
lo que resulta en eso 
Por lo tanto, el cálculo de los factores de Bayes sobre
Sin embargo, este problema solo es relevante para la selección del modelo cuando se ha reducido la dimensión de los datos. La inferencia basada en ABC, en la que los conjuntos de datos reales se comparan directamente, como es el caso de algunas aplicaciones de biología de sistemas (p. ej., consulte), evita este problema.
Controles de calidad indispensables
Como deja en claro la discusión anterior, cualquier análisis ABC requiere elecciones y compensaciones que pueden tener un impacto considerable en sus resultados. Específicamente, la elección de modelos/hipótesis en competencia, el número de simulaciones, la elección de estadísticas de resumen o el umbral de aceptación no pueden basarse actualmente en reglas generales, pero el efecto de estas elecciones debe evaluarse y probarse en cada estudio.
Se han propuesto varios enfoques heurísticos para el control de calidad de ABC, como la cuantificación de la fracción de la varianza del parámetro explicada por las estadísticas de resumen. Una clase común de métodos tiene como objetivo evaluar si la inferencia produce o no resultados válidos, independientemente de los datos realmente observados. Por ejemplo, dado un conjunto de valores de parámetros, que normalmente se extraen de las distribuciones anterior o posterior de un modelo, se puede generar una gran cantidad de conjuntos de datos artificiales. De esta manera, la calidad y la solidez de la inferencia ABC se pueden evaluar en un entorno controlado, midiendo qué tan bien el método de inferencia ABC elegido recupera los valores reales de los parámetros, y también modela si se consideran múltiples modelos estructuralmente diferentes simultáneamente.
Otra clase de métodos evalúa si la inferencia tuvo éxito a la luz de los datos observados dados, por ejemplo, comparando la distribución predictiva posterior de las estadísticas de resumen con las estadísticas de resumen observadas. Más allá de eso, las técnicas de validación cruzaday los controles predictivos representan estrategias futuras prometedoras para evaluar la estabilidad y la validez predictiva fuera de la muestra de las inferencias ABC. Esto es particularmente importante cuando se modelan grandes conjuntos de datos, porque entonces el respaldo posterior de un modelo en particular puede parecer abrumadoramente concluyente, incluso si todos los modelos propuestos son, de hecho, representaciones deficientes del sistema estocástico subyacente a los datos de observación. Las comprobaciones predictivas fuera de la muestra pueden revelar posibles sesgos sistemáticos dentro de un modelo y proporcionar pistas sobre cómo mejorar su estructura o parametrización.
Recientemente se han propuesto enfoques fundamentalmente novedosos para la elección del modelo que incorporan el control de calidad como un paso integral en el proceso. ABC permite, por construcción, la estimación de las discrepancias entre los datos observados y las predicciones del modelo, con respecto a un conjunto completo de estadísticas. Estas estadísticas no son necesariamente las mismas que las utilizadas en el criterio de aceptación. Las distribuciones de discrepancia resultantes se han utilizado para seleccionar modelos que están de acuerdo con muchos aspectos de los datos simultáneamente.y la inconsistencia del modelo se detecta a partir de resúmenes conflictivos y codependientes. Otro método basado en el control de calidad para la selección de modelos emplea ABC para aproximar el número efectivo de parámetros del modelo y la desviación de las distribuciones predictivas posteriores de resúmenes y parámetros. El criterio de información de desviación se utiliza entonces como medida del ajuste del modelo. También se ha demostrado que los modelos preferidos en base a este criterio pueden entrar en conflicto con los sustentados por los factores de Bayes. Por esta razón, es útil combinar diferentes métodos de selección de modelos para obtener conclusiones correctas.
Los controles de calidad se pueden lograr y, de hecho, se realizan en muchos trabajos basados en ABC, pero para ciertos problemas, la evaluación del impacto de los parámetros relacionados con el método puede ser un desafío. Sin embargo, se puede esperar que el uso cada vez mayor de ABC proporcione una comprensión más completa de las limitaciones y la aplicabilidad del método.
Riesgos generales en inferencia estadística exacerbados en ABC
Esta sección revisa los riesgos que estrictamente hablando no son específicos de ABC, pero también son relevantes para otros métodos estadísticos. Sin embargo, la flexibilidad que ofrece ABC para analizar modelos muy complejos los hace muy relevantes para discutir aquí.
Distribución previa y rangos de parámetros
La especificación del rango y la distribución previa de parámetros se beneficia enormemente del conocimiento previo sobre las propiedades del sistema. Una crítica ha sido que, en algunos estudios, "los rangos y las distribuciones de los parámetros solo se adivinan en función de la opinión subjetiva de los investigadores", lo que está relacionado con las objeciones clásicas de los enfoques bayesianos.
Con cualquier método computacional, normalmente es necesario restringir los rangos de parámetros investigados. Si es posible, los rangos de parámetros deben definirse en función de las propiedades conocidas del sistema estudiado, pero para aplicaciones prácticas pueden requerir una conjetura fundamentada. Sin embargo, se dispone de resultados teóricos sobre priorizaciones objetivas, que pueden basarse, por ejemplo, en el principio de indiferencia o en el principio de máxima entropía. Por otro lado, los métodos automatizados o semiautomáticos para elegir una distribución previa a menudo arrojan densidades inadecuadas. Como la mayoría de los procedimientos ABC requieren la generación de muestras a partir de la previa, las previas impropias no son directamente aplicables a ABC.
También se debe tener en cuenta el propósito del análisis al elegir la distribución previa. En principio, los datos previos planos y poco informativos, que exageran nuestra ignorancia subjetiva sobre los parámetros, aún pueden producir estimaciones de parámetros razonables. Sin embargo, los factores de Bayes son muy sensibles a la distribución previa de los parámetros. Las conclusiones sobre la elección del modelo basadas en el factor de Bayes pueden ser engañosas a menos que se considere cuidadosamente la sensibilidad de las conclusiones a la elección de los resultados previos.
Pequeño número de modelos
Los métodos basados en modelos han sido criticados por no cubrir exhaustivamente el espacio de hipótesis. De hecho, los estudios basados en modelos a menudo giran en torno a una pequeña cantidad de modelos y, debido al alto costo computacional para evaluar un solo modelo en algunos casos, puede ser difícil cubrir una gran parte del espacio de hipótesis.
Un límite superior para el número de modelos candidatos considerados normalmente se establece por el esfuerzo sustancial requerido para definir los modelos y elegir entre muchas opciones alternativas. No existe un procedimiento específico de ABC comúnmente aceptado para la construcción de modelos, por lo que en su lugar se utilizan la experiencia y los conocimientos previos. Aunque sería beneficioso contar con procedimientos más sólidos para la elección y formulación de modelos a priori, no existe una estrategia única para el desarrollo de modelos en estadística: la caracterización sensata de sistemas complejos siempre requerirá una gran cantidad de trabajo de detección y el uso de expertos. conocimiento del dominio del problema.
Algunos opositores de ABC sostienen que dado que solo unos pocos modelos, elegidos subjetivamente y probablemente todos equivocados, pueden considerarse de manera realista, los análisis ABC brindan solo una visión limitada. Sin embargo, existe una distinción importante entre identificar una hipótesis nula plausible y evaluar el ajuste relativo de las hipótesis alternativas. Dado que las hipótesis nulas útiles, que potencialmente son ciertas, rara vez se pueden presentar en el contexto de modelos complejos, la capacidad predictiva de los modelos estadísticos como explicaciones de fenómenos complejos es mucho más importante que la prueba de una hipótesis nula estadística en este contexto. También es común promediar los modelos investigados, ponderados en función de su verosimilitud relativa, para inferir características del modelo (p. ej., valores de parámetros) y hacer predicciones.
Grandes conjuntos de datos
Grandes conjuntos de datos pueden constituir un cuello de botella computacional para los métodos basados en modelos. Se señaló, por ejemplo, que en algunos análisis basados en ABC, se debe omitir parte de los datos. Varios autores han argumentado que los grandes conjuntos de datos no son una limitación práctica, aunque la gravedad de este problema depende en gran medida de las características de los modelos. Varios aspectos de un problema de modelado pueden contribuir a la complejidad computacional, como el tamaño de la muestra, la cantidad de variables o características observadas, la resolución temporal o espacial, etc. Sin embargo, con el aumento de la potencia informática, este problema será potencialmente menos importante.
En lugar de muestrear parámetros para cada simulación de la anterior, se ha propuesto alternativamente combinar el algoritmo Metropolis-Hastings con ABC, que resultó en una tasa de aceptación más alta que para ABC simple. Naturalmente, tal enfoque hereda las cargas generales de los métodos MCMC, como la dificultad para evaluar la convergencia, la correlación entre las muestras de la paralelización posterior y relativamente pobre.
Asimismo, las ideas de los métodos Monte Carlo secuencial (SMC) y Monte Carlo poblacional (PMC) se han adaptado al entorno ABC. La idea general es abordar iterativamente lo posterior desde lo anterior a través de una secuencia de distribuciones objetivo. Una ventaja de tales métodos, en comparación con ABC-MCMC, es que las muestras del posterior resultante son independientes. Además, con los métodos secuenciales, los niveles de tolerancia no deben especificarse antes del análisis, sino que se ajustan de forma adaptativa.
Es relativamente sencillo paralelizar una serie de pasos en algoritmos ABC basados en muestreo de rechazo y métodos secuenciales de Monte Carlo. También se ha demostrado que los algoritmos paralelos pueden generar aceleraciones significativas para la inferencia basada en MCMC en filogenética, que puede ser un enfoque manejable también para los métodos basados en ABC. Sin embargo, es muy probable que un modelo adecuado para un sistema complejo requiera un cálculo intensivo, independientemente del método de inferencia elegido, y depende del usuario seleccionar un método que sea adecuado para la aplicación particular en cuestión.
Maldición de dimensionalidad
Los conjuntos de datos de alta dimensión y los espacios de parámetros de alta dimensión pueden requerir la simulación de un número extremadamente grande de puntos de parámetros en estudios basados en ABC para obtener un nivel razonable de precisión para las inferencias posteriores. En tales situaciones, el costo computacional aumenta considerablemente y, en el peor de los casos, puede volver intratable el análisis computacional. Estos son ejemplos de fenómenos bien conocidos, a los que generalmente se hace referencia con el término genérico maldición de la dimensionalidad.
Para evaluar qué tan severamente la dimensionalidad de un conjunto de datos afecta el análisis dentro del contexto de ABC, se han derivado fórmulas analíticas para el error de los estimadores ABC como funciones de la dimensión de las estadísticas de resumen. Además, Blum y François han investigado cómo se relaciona la dimensión de los estadísticos de resumen con el error cuadrático medio para diferentes ajustes de corrección al error de los estimadores ABC. También se argumentó que las técnicas de reducción de dimensiones son útiles para evitar la maldición de la dimensionalidad, debido a una estructura subyacente potencialmente de menor dimensión de las estadísticas de resumen.Motivados por minimizar la pérdida cuadrática de los estimadores ABC, Fearnhead y Prangle propusieron un esquema para proyectar datos (posiblemente de alta dimensión) en estimaciones de las medias posteriores de los parámetros; estos medios, que ahora tienen la misma dimensión que los parámetros, se utilizan como estadísticas de resumen para ABC.
ABC se puede utilizar para inferir problemas en espacios de parámetros de alta dimensión, aunque se debe tener en cuenta la posibilidad de sobreajuste (p. ej., consulte los métodos de selección de modelos en y). Sin embargo, la probabilidad de aceptar los valores simulados para los parámetros bajo una tolerancia dada con el algoritmo de rechazo ABC generalmente disminuye exponencialmente con el aumento de la dimensionalidad del espacio de parámetros (debido al criterio de aceptación global). Aunque ningún método computacional (basado en ABC o no) parece ser capaz de romper la maldición de la dimensionalidad, recientemente se han desarrollado métodos para manejar espacios de parámetros de alta dimensión bajo ciertas suposiciones (p.lo que potencialmente podría reducir en gran medida los tiempos de simulación para ABC). Sin embargo, la aplicabilidad de tales métodos depende del problema y, en general, no se debe subestimar la dificultad de explorar espacios de parámetros. Por ejemplo, la introducción de la estimación de parámetros globales deterministas condujo a informes de que los óptimos globales obtenidos en varios estudios previos de problemas de baja dimensión eran incorrectos. Para ciertos problemas, puede ser difícil saber si el modelo es incorrecto o, como se discutió anteriormente, si la región explorada del espacio de parámetros es inapropiada. Los enfoques más pragmáticos son reducir el alcance del problema a través de la reducción del modelo,discretización de variables y uso de modelos canónicos como los modelos ruidosos. Los modelos ruidosos explotan información sobre la independencia condicional entre variables.
Software
Actualmente se encuentran disponibles varios paquetes de software para la aplicación de ABC a clases particulares de modelos estadísticos.
| Software | Palabras clave y características | Referencia |
|---|---|---|
| pyABC | Framework Python para ABC-SMC distribuido eficientemente (Sequential Monte Carlo). | |
| PyMC | Un paquete de Python para el modelado estadístico bayesiano y el aprendizaje automático probabilístico. | |
| DIY-ABC | Software para ajuste de datos genéticos a situaciones complejas. Comparación de modelos de la competencia. Estimación de parámetros. Cálculo de medidas de precisión y sesgo para un modelo dado y valores de parámetros conocidos. | |
| paquete abcR | Varios algoritmos ABC para realizar la estimación de parámetros y la selección de modelos. Métodos de regresión heteroscedástica no lineal para ABC. Herramienta de validación cruzada. | |
| Paquete EasyABCR | Varios algoritmos para realizar esquemas de muestreo ABC eficientes, incluidos 4 esquemas de muestreo secuencial y 3 esquemas MCMC. | |
| ABC-SysBio | Paquete Python. Inferencia de parámetros y selección de modelos para sistemas dinámicos. Combina el muestreador de rechazo ABC, ABC SMC para la inferencia de parámetros y ABC SMC para la selección de modelos. Compatible con modelos escritos en lenguaje de marcado de biología de sistemas (SBML). Modelos deterministas y estocásticos. | |
| ABCcaja de herramientas | Programas de código abierto para varios algoritmos ABC, incluido el muestreo de rechazo, MCMC sin probabilidad, un muestreador basado en partículas y ABC-GLM. Compatibilidad con la mayoría de los programas de cálculo de estadísticas de resumen y simulación. | |
| msBayes | Paquete de software de código abierto que consta de varios programas C y R que se ejecutan con un "front-end" de Perl. Modelos coalescentes jerárquicos. Datos genéticos de población de múltiples especies co-distribuidas. | |
| PopABC | Paquete de software para la inferencia del patrón de divergencia demográfica. Simulación coalescente. Elección del modelo bayesiano. | |
| ONESAMP | Programa basado en la web para estimar el tamaño efectivo de la población a partir de una muestra de genotipos de microsatélites. Estimaciones del tamaño efectivo de la población, junto con límites creíbles del 95%. | |
| ABC4F | Software para estimación de estadísticos F para datos dominantes. | |
| 2 MALO | Mezcla Bayesiana de 2 eventos. Software que permite hasta dos eventos de mezcla independientes con hasta tres poblaciones parentales. Estimación de varios parámetros (mezcla, tamaños efectivos, etc.). Comparación de pares de modelos de mezcla. | |
| ELFI | Motor para inferencia libre de verosimilitud. ELFI es un paquete de software estadístico escrito en Python para cálculo bayesiano aproximado (ABC), también conocido, por ejemplo, como inferencia libre de probabilidad, inferencia basada en simulador, inferencia bayesiana aproximada, etc. | |
| ABCpy | Paquete de Python para ABC y otros esquemas de inferencia sin probabilidad. Varios algoritmos de última generación disponibles. Proporciona una forma rápida de integrar generativo existente (desde C++, R, etc.), paralelización fácil de usar usando MPI o Spark y aprendizaje de estadísticas resumidas (con red neuronal o regresión lineal). |
La idoneidad de los paquetes de software individuales depende de la aplicación específica en cuestión, el entorno del sistema informático y los algoritmos necesarios.
Contenido relacionado
Distribución predictiva posterior
Área estadística metropolitana
Regresión lineal bayesiana